最近阅读蔡学镛老师的《编程ING》读到第一篇里的REBOL字符编码问题,遇到了点小问题,后来又理解通了,所以写下这篇文章加强记忆。
首先,计算机世界里的编码有多种,比如1个字节的ASCII,这种编码方式包含了英文和一些符号,但不包括中文,日文,韩文等等字符。如果要使用中文,韩文等各国文字的话,就一般使用基本包含各种字符的2字节Unicode编码。还有可变动长度的UTF-8编码方式,它用ASCII方式1字节表示英文,用3字节表示中文。而REBOL支持2字节的Unicode编码和可变字节的UTF-8编码方式,只是用的地方不大一样。

Unicode码点是适合运行的数据格式,因为长度都一样,方便处理,例如string类型的数据都是Unicode编码方式。
“^()”,括号里放unicode码点即可得到对应的编码字符。string型数据可以放任意多个(1个也行)的字符。
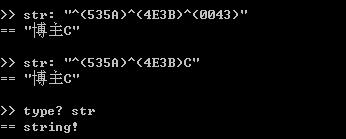
若是使用只能装一个字符的char,则必须在使用#"^()",引号前要多个#

UTF-8适合存储和网络传输,因为长度较短节省空间,毕竟REBOL代码大多数都是英文,因此�REBOLREbOL r
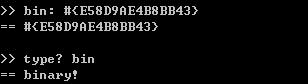
REBOL规定脚本文件一定是UTF-8编码格式。在存储和网络传输时我们都用二进制方式即binary。
使用方式即为#{},中括号里直接放对应字符的UTF-8编码。
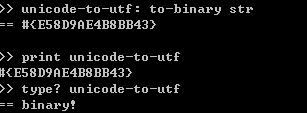
UTF-8与Unicode两种编码方式可以相互转化
UTF-8转Unicode 使用to-string
Unicode转UTF-8 使用to-binary