C++ 用异常使得可以将正常执行代码和出错处理区别开来。 比如一个栈,其为空时,调用其一个pop 函数,接下来怎么办? 栈本身并不知道该如何处理,需要通知给其调用者(caller),因为只有调用者清楚接下来该怎么做。 异常,就提供了一个很好机制。 但是异常需要操作系统,编译器,RTTI的特性支持。
下面围绕一个问题 “为什么析构函数不能抛出异常?” 展开C++中异常的实现。
Effective C++ 里面有一条”别让异常逃离析构函数“,大意说是Don't do that, otherwise the behavior is undefined. 这里讨论一下从异常的实现角度,讨论一下为什么不要 ?
1. 函数调用框架和SEH( Structure Error Handling)
程序


1 int widget( int a, int b) 2 { 3 return a + b; 4 } 5 6 int bar(int a, int b) 7 { 8 int c = widget(a, b); 9 return c; 10 } 11 12 int foo( int a, int b) 13 { 14 int c=bar(a, b); 15 return c; 16 } 17 18 int main() 19 { 20 foo( 1, 2); 21 }
其汇编代码
 View
ViewCode
调用框架
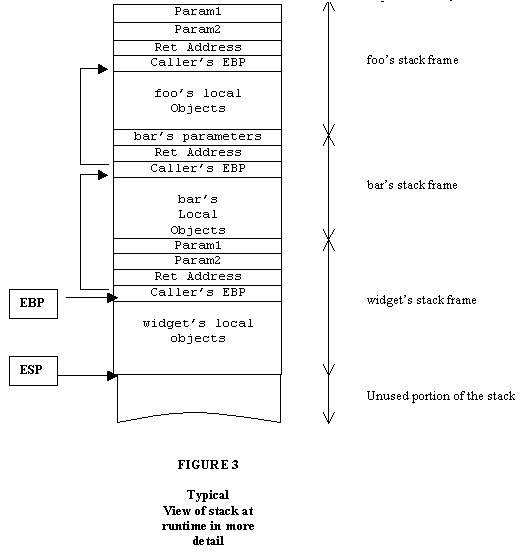
2。 加入SEH 之后,函数调用框架稍微修改一下: 对每一个函数加入一个Exception_Registration 的链表,链表头存放在FS:[0] 里面。当异常抛出时,就去遍历该链表找到合适的catch 块。 对于每一个Exception_Registration 存放链表的上一个节点,异常处理函数( Error Handler). 用来处理异常。 这些结构都是编译器加上的,分别在函数调用的prologue 和epilogue ,注册和注销 一个异常处理节点。
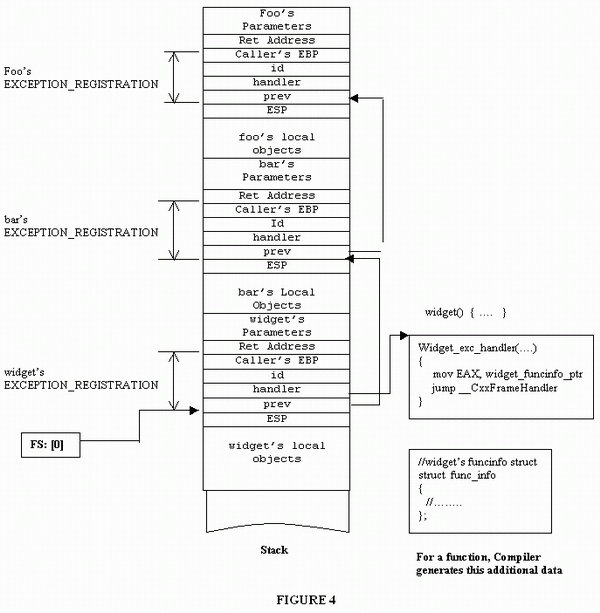
NOTE: error handling
1. 当异常发生时,系统得到控制权,系统从FS:[0]寄存器取到异常处理链的头,以及异常的类型, 调用异常处理函数。(异常函数是编译器生成的)
2. 从链表头去匹配 异常类型和catch 块接收的类型。( 这里用到RTTI 信息)
3. unwind stack。这里需要析构已经创建的对象。( 这里需要判断析构哪些对象,这一步是编译器做的)
4. 执行catch 块代码。
后返回到程序的正常代码,即catch块下面的第一行代码。
可见,在exception 找到对应的 Catche 块后, 去栈展开(unwind stack),析构已有的对象后,进入到Catch 块中。 问题是: 程序怎么知道程序运行到哪里? 哪些对象需要调用析构函数? 这也是编译器做的,对于每一个Catch 块,其记录下如果该catch 块若被调用,哪些对象需要被析构。 这有这么一张表。具体实现可以参见reference2.
3. 当析构抛出异常时,接下来的故事。
实验1: Base 类的析构抛出异常;
1 class Base 2 { 3 public: 4 void fun() { throw 1; } 5 ~Base() { throw 2; } 6 }; 7 8 int main() 9 { 10 try 11 { 12 Base base; 13 //base.fun(); 14 } 15 catch (...) 16 { 17 //cout <<"get the catch"<<endl; 18 } 19 }
运行没有问题。
实验2: 打开上面注释掉的第13行代码( //base.fun(); ),再试运行,结果呢?
在debug 模式下弹出对话框

为什么呢?
因为SEH 是一个链表,链表头地址存在FS:[0] 的寄存器里面。 在实验2,函数base.fun先抛出异常,从FS:[0]开始向上遍历 SHL 节点,匹配到catch 块。 找到代码里面为一个catch块,再去展开栈,调用base 的析构函数,然而析构又抛出异常。 如果系统再去从SEL链表匹配,会改变FS:[0]值,这时候程序迷失了,不知道下面该怎么什么? 因为他已经丢掉了上一次异常链那个节点。
实验3:如果析构函数的异常被处理呢, 程序还会正常运行吗?
1 class Base 2 { 3 public: 4 void fun() { throw 1; } 5 ~Base() 6 { 7 try 8 { 9 throw 2; 10 } 11 catch (int e) 12 { 13 // do something 14 } 15 } 16 }; 17 18 int main() 19 { 20 try 21 { 22 Base base; 23 //base.fun(); 24 } 25 catch (...) 26 { 27 //cout <<"get the catch"<<endl; 28 } 29 }
的确可以运行。
因为析构抛出来的异常,在到达上一层析构节点之前已经被别的catch 块给处理掉。那么当回到上一层异常函数时, 其SEH 没有变,程序可以继续执行。
这也许就是为什么C++不支持异常中抛的异常。
4. 效率:
当无异常抛出时,其开销就是在函数调用的时候注册/注销 异常处理函数,这些开销很小。
但是当异常抛出时,其开销就大了,编译异常链,用RTTI比配类型,调用析构;但是比传统的那种返回值,层层返回,效率也不会太差。 带来好的好处是代码好维护,减少出错处理的重复代码,并且与逻辑代码分开。
权衡一下,好处还是大大的:)
5. 总结一下流程:
为了安全,”析构函数尽可能的不要抛出异常“。
如果非抛不可,语言也提供了方法,就是自己的异常,自己给吃掉。但是这种方法不提倡,我们提倡有错早点报出来。
Note:
1.同样还有一个问题,”构造函数可以抛出异常么? 为什么?“
C++ 里面当构造函数抛出异常时,其会调用构造函数里面已经创建对象的析构函数,但是对以自己的析构函数没有调用,就可能产生内存泄漏,比如自己new 出来的内存没有释放。
有两个办法。在Catch 块里面释放已经申请的资源 或者 用智能指针把资源当做对象处理。
Delphi 里面当构造函数抛异常时,在其执行Catch 代码前,其先调用析构函数。
所以,构造抛出异常,是否调用析构函数,不是取决于技术,而是取决于语言的设计者。
2. 关于多线程,异常是线程安全的。 对于每一个线程都有自己的 Thread Info/Environment Block. 维护自己的SEH结构。
Reference:
1.http://www.codeproject.com/KB/cpp/exceptionhandler.aspx
2.http://baiy.cn/doc/cpp/inside_exception.htm
3.http://www.mzwu.com/article.asp?id=1469