本文着重介绍sharding的基本思想和理论上的切分策略,关于更加细致的实施策略和参考事例请参考我的另一篇博文:数据库分库分表(sharding)系列(一) 拆分实施策略和示例演示
一、基本思想
Sharding的基本思想就要把一个数据库切分成多个部分放到不同的数据库(server)上,从而缓解单一数据库的性能问题。不太严格的讲,对于海量数据的数据库,如果是因为表多而数据多,这时候适合使用垂直切分,即把关系紧密(比如同一模块)的表切分出来放在一个server上。如果表并不多,但每张表的数据非常多,这时候适合水平切分,即把表的数据按某种规则(比如按ID散列)切分到多个数据库(server)上。当然,现实中更多是这两种情况混杂在一起,这时候需要根据实际情况做出选择,也可能会综合使用垂直与水平切分,从而将原有数据库切分成类似矩阵一样可以无限扩充的数据库(server)阵列。下面分别详细地介绍一下垂直切分和水平切分.
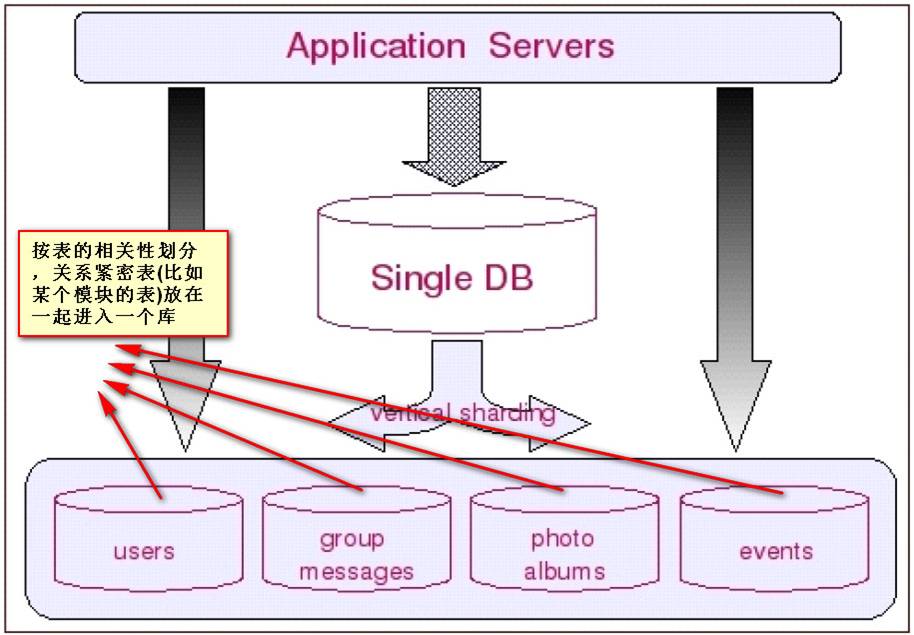
垂直切分的最大特点就是规则简单,实施也更为方便,尤其适合各业务之间的耦合度非
常低,相互影响很小,业务逻辑非常清晰的系统。在这种系统中,可以很容易做到将不同业
务模块所使用的表分拆到不同的数据库中。根据不同的表来进行拆分,对应用程序的影响也
更小,拆分规则也会比较简单清晰。(这也就是所谓的”share nothing”)。
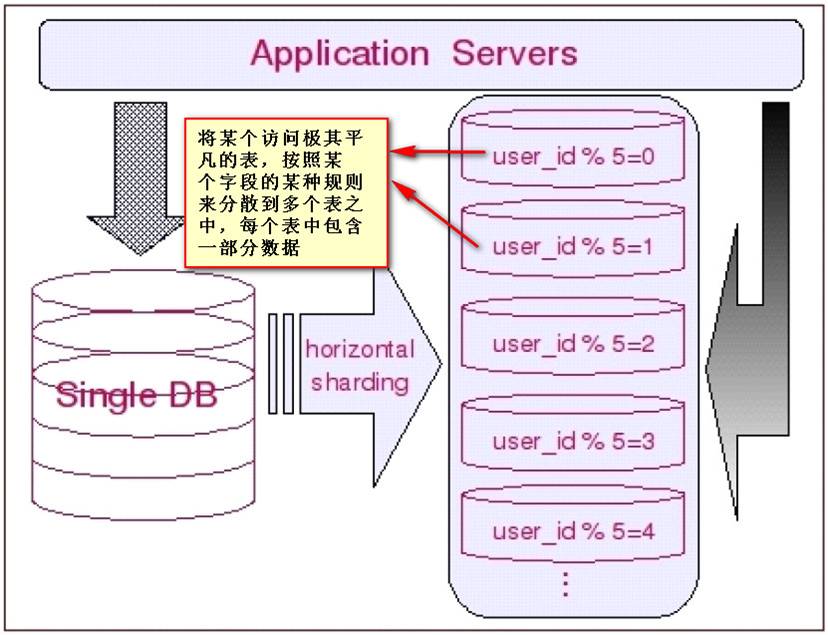
水平切分于垂直切分相比,相对来说稍微复杂一些。因为要将同一个表中的不同数据拆
分到不同的数据库中,对于应用程序来说,拆分规则本身就较根据表名来拆分更为复杂,后
期的数据维护也会更为复杂一些。
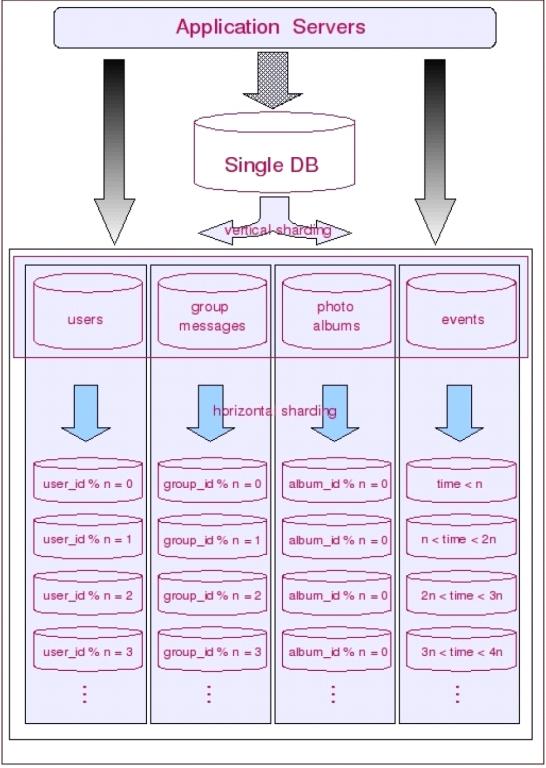
让我们从普遍的情况来考虑数据的切分:一方面,一个库的所有表通常不可能由某一张表全部串联起来,这句话暗含的意思是,水平切分几乎都是针对一小搓一小搓(实际上就是垂直切分出来的块)关系紧密的表进行的,而不可能是针对所有表进行的。另一方面,一些负载非常高的系统,即使仅仅只是单个表都无法通过单台数据库主机来承担其负载,这意味着单单是垂直切分也不能完全解决问明。因此多数系统会将垂直切分和水平切分联合使用,先对系统做垂直切分,再针对每一小搓表的情况选择性地做水平切分。从而将整个数据库切分成一个分布式矩阵。
二、切分策略
如前面所提到的,切分是按先垂直切分再水平切分的步骤进行的。垂直切分的结果正好为水平切分做好了铺垫。垂直切分的思路就是分析表间的聚合关系,把关系紧密的表放在一起。多数情况下可能是同一个模块,或者是同一“聚集”。这里的“聚集”正是领域驱动设计里所说的聚集。在垂直切分出的表聚集内,找出“根元素”(这里的“根元素”就是领域驱动设计里的“聚合根”),按“根元素”进行水平切分,也就是从“根元素”开始,把所有和它直接与间接关联的数据放入一个shard里。这样出现跨shard关联的可能性就非常的小。应用程序就不必打断既有的表间关联。比如:对于社交网站,几乎所有数据最终都会关联到某个用户上,基于用户进行切分就是最好的选择。再比如论坛系统,用户和论坛两个模块应该在垂直切分时被分在了两个shard里,对于论坛模块来说,Forum显然是聚合根,因此按Forum进行水平切分,把Forum里所有的帖子和回帖都随Forum放在一个shard里是很自然的。
对于共享数据数据,如果是只读的字典表,每个shard里维护一份应该是一个不错的选择,这样不必打断关联关系。如果是一般数据间的跨节点的关联,就必须打断。
需要特别说明的是:当同时进行垂直和水平切分时,切分策略会发生一些微妙的变化。比如:在只考虑垂直切分的时候,被划分到一起的表之间可以保持任意的关联关系,因此你可以按“功能模块”划分表格,但是一旦引入水平切分之后,表间关联关系就会受到很大的制约,通常只能允许一个主表(以该表ID进行散列的表)和其多个次表之间保留关联关系,也就是说:当同时进行垂直和水平切分时,在垂直方向上的切分将不再以“功能模块”进行划分,而是需要更加细粒度的垂直切分,而这个粒度与领域驱动设计中的“聚合”概念不谋而合,甚至可以说是完全一致,每个shard的主表正是一个聚合中的聚合根!这样切分下来你会发现数据库分被切分地过于分散了(shard的数量会比较多,但是shard里的表却不多),为了避免管理过多的数据源,充分利用每一个数据库服务器的资源,可以考虑将业务上相近,并且具有相近数据增长速率(主表数据量在同一数量级上)的两个或多个shard放到同一个数据源里,每个shard依然是独立的,它们有各自的主表,并使用各自主表ID进行散列,不同的只是它们的散列取模(即节点数量)必需是一致的。(
本文着重介绍sharding的基本思想和理论上的切分策略,关于更加细致的实施策略和参考事例请参考我的另一篇博文:数据库分库分表(sharding)系列(一) 拆分实施策略和示例演示
)
1.事务问题:
解决事务问题目前有两种可行的方案:分布式事务和通过应用程序与数据库共同控制实现事务下面对两套方案进行一个简单的对比。
方案一:使用分布式事务
优点:交由数据库管理,简单有效
缺点:性能代价高,特别是shard越来越多时
方案二:由应用程序和数据库共同控制
原理:将一个跨多个数据库的分布式事务分拆成多个仅处
于单个数据库上面的小事务,并通过应用程序来总控
各个小事务。
优点:性能上有优势
缺点:需要应用程序在事务控制上做灵活设计。如果使用
了spring的事务管理,改动起来会面临一定的困难。
2.跨节点Join的问题
只要是时行切分,跨节点Join的问明是不可避免的。但是良好的设计和切分却可以减少此类情况的发生。解决这一问题的普遍做法是分两次查询实现。在第一次查询的结果集中找出关联数据的id,根据这些id发起第二次请求得到关联数据。
3.跨节点的count,order by,group by以及聚合函数问题
这些是一类问题,因为它们都需要基于全部数据集合进行计算。多数的代理都不会自动处理合并工作。解决方案:与解决跨节点join问题的类似,分别在各个节点上得到结果后在应用程序端进行合并。和join不同的是每个结点的查询可以并行执行,因此很多时候它的速度要比单一大表快很多。但如果结果集很大,对应用程序内存的消耗是一个问题。
参考资料:
《MySQL性能调优与架构设计》
注:本文图片摘自《MySQL性能调优与架构设计》一 书
本文原文连接: http://blog.csdn.net/bluishglc/article/details/7696085 ,转载请注明出处!本文着重介绍sharding切分策略,如果你对数据库sharding缺少基本的了解,请参考我另一篇从基础理论全面介绍sharding的文章:数据库Sharding的基本思想和切分策略
第一部分:实施策略

图1.数据库分库分表(sharding)实施策略图解(点击查看大图)
1.准备阶段
对数据库进行分库分表(Sharding化)前,需要开发人员充分了解系统业务逻辑和数据库schema.一个好的建议是绘制一张数据库ER图或领域模型图,以这类图为基础划分shard,直观易行,可以确保开发人员始终保持清醒思路。对于是选择数据库ER图还是领域模型图要根据项目自身情况进行选择。如果项目使用数据驱动的开发方式,团队以数据库ER图作为业务交流的基础,则自然会选择数据库ER图,如果项目使用的是领域驱动的开发方式,并通过OR-Mapping构建了一个良好的领域模型,那么领域模型图无疑是最好的选择。就我个人来说,更加倾向使用领域模型图,因为进行切分时更多的是以业务为依据进行分析判断,领域模型无疑更加清晰和直观。
2.分析阶段
1. 垂直切分
垂直切分的依据原则是:将业务紧密,表间关联密切的表划分在一起,例如同一模块的表。结合已经准备好的数据库ER图或领域模型图,仿照活动图中的泳道概念,一个泳道代表一个shard,把所有表格划分到不同的泳道中。下面的分析示例会展示这种做法。当然,你也可以在打印出的ER图或模型图上直接用铅笔圈,一切取决于你自己的喜好。
2. 水平切分
垂直切分后,需要对shard内表格的数据量和增速进一步分析,以确定是否需要进行水平切分。
2.1若划分到一起的表格数据增长缓慢,在产品上线后可遇见的足够长的时期内均可以由单一数据库承载,则不需要进行水平切分,所有表格驻留同一shard,所有表间关联关系会得到最大限度的保留,同时保证了书写SQL的自由度,不易受join、group by、order by等子句限制。
2.2 若划分到一起的表格数据量巨大,增速迅猛,需要进一步进行水平分割。进一步的水平分割就这样进行:
2.2.1.结合业务逻辑和表间关系,将当前shard划分成多个更小的shard,通常情况下,这些更小的shard每一个都只包含一个主表(将以该表ID进行散列的表)和多个与其关联或间接关联的次表。这种一个shard一张主表多张次表的状况是水平切分的必然结果。这样切分下来,shard数量就会迅速增多。如果每一个shard代表一个独立的数据库,那么管理和维护数据库将会非常麻烦,而且这些小shard往往只有两三张表,为此而建立一个新库,利用率并不高,因此,在水平切分完成后可再进行一次“反向的Merge”,即:将业务上相近,并且具有相近数据增长速率(主表数据量在同一数量级上)的两个或多个shard放到同一个数据库上,在逻辑上它们依然是独立的shard,有各自的主表,并依据各自主表的ID进行散列,不同的只是它们的散列取模(即节点数量)必需是一致的。这样,每个数据库结点上的表格数量就相对平均了。
2.2.2. 所有表格均划分到合适的shard之后,所有跨越shard的表间关联都必须打断,在书写sql时,跨shard的join、group by、order by都将被禁止,需要在应用程序层面协调解决这些问题。
特别想提一点:经水平切分后,shard的粒度往往要比只做垂直切割的粒度要小,原单一垂直shard会被细分为一到多个以一个主表为中心关联或间接关联多个次表的shard,此时的shard粒度与领域驱动设计中的“聚合”概念不谋而合,甚至可以说是完全一致,每个shard的主表正是一个聚合中的聚合根!
3.实施阶段
如果项目在开发伊始就决定进行分库分表,则严格按照分析设计方案推进即可。如果是在中期架构演进中实施,除搭建实现sharding逻辑的基础设施外(关于该话题会在下篇文章中进行阐述),还需要对原有SQL逐一过滤分析,修改那些因为sharding而受到影响的sql.
第二部分:示例演示
本文选择一个人尽皆知的应用:jpetstore来演示如何进行分库分表(sharding)在分析阶段的工作。由于一些个人原因,演示使用的jpetstore来自原ibatis官方的一个Demo版本,SVN地址为:http://mybatis.googlecode.com/svn/tags/java_release_2.3.4-726/jpetstore-5。关于jpetstore的业务逻辑这里不再介绍,这是一个非常简单的电商系统原型,其领域模型如下图:

图2. jpetstore领域模型
由于系统较简单,我们很容易从模型上看出,其主要由三个模块组成:用户,产品和订单。那么垂直切分的方案也就出来了。接下来看水平切分,如果我们从一个实际的宠物店出发考虑,可能出现数据激增的单表应该是Account和Order,因此这两张表需要进行水平切分。对于Product模块来说,如果是一个实际的系统,Product和Item的数量都不会很大,因此只做垂直切分就足够了,也就是(Product,Category,Item,Iventory,Supplier)五张表在一个数据库结点上(没有水平切分,不会存在两个以上的数据库结点)。但是作为一个演示,我们假设产品模块也有大量的数据需要我们做水平切分,那么分析来看,这个模块要拆分出两个shard:一个是(Product(主),Category),另一个是(Item(主),Iventory,Supplier),同时,我们认为:这两个shard在数据增速上应该是相近的,且在业务上也很紧密,那么我们可以把这两个shard放在同一个数据库节点上,Item和Product数据在散列时取一样的模。根据前文介绍的图纸绘制方法,我们得到下面这张sharding示意图:

图3. jpetstore sharding示意图
对于这张图再说明几点:
1.使用泳道表示物理shard(一个数据库结点)
2.若垂直切分出的shard进行了进一步的水平切分,但公用一个物理shard的话,则用虚线框住,表示其在逻辑上是一个独立的shard。
3.深色实体表示主表
4.X表示需要打断的表间关联
本文将主要介绍一些常见的全局主键生成策略,然后重点介绍flickr使用的一种非常优秀的全局主键生成方案。关于分库分表(sharding)的拆分策略和实施细则,请参考该系列的前一篇文章:数据库分库分表(sharding)系列(一)
拆分实施策略和示例演示 本文原文连接: http://blog.csdn.net/bluishglc/article/details/7710738 ,转载请注明出处!
第一部分:一些常见的主键生成策略
一旦数据库被切分到多个物理结点上,我们将不能再依赖数据库自身的主键生成机制。一方面,某个分区数据库自生成的ID无法保证在全局上是唯一的;另一方面,应用程序在插入数据之前需要先获得ID,以便进行SQL路由。目前几种可行的主键生成策略有:
1. UUID:使用UUID作主键是最简单的方案,但是缺点也是非常明显的。由于UUID非常的长,除占用大量存储空间外,最主要的问题是在索引上,在建立索引和基于索引进行查询时都存在性能问题。
2. 结合数据库维护一个Sequence表:此方案的思路也很简单,在数据库中建立一个Sequence表,表的结构类似于:
- CREATE TABLE `SEQUENCE` (
- `tablename` varchar(30) NOT NULL,
- `nextid` bigint(20) NOT NULL,
- PRIMARY KEY (`tablename`)
- ) ENGINE=InnoDB
每当需要为某个表的新纪录生成ID时就从Sequence表中取出对应表的nextid,并将nextid的值加1后更新到数据库中以备下次使用。此方案也较简单,但缺点同样明显:由于所有插入任何都需要访问该表,该表很容易成为系统性能瓶颈,同时它也存在单点问题,一旦该表数据库失效,整个应用程序将无法工作。有人提出使用Master-Slave进行主从同步,但这也只能解决单点问题,并不能解决读写比为1:1的访问压力问题。
除此之外,还有一些方案,像对每个数据库结点分区段划分ID,以及网上的一些ID生成算法,因为缺少可操作性和实践检验,本文并不推荐。实际上,接下来,我们要介绍的是Fickr使用的一种主键生成方案,这个方案是目前我所知道的最优秀的一个方案,并且经受了实践的检验,可以为大多数应用系统所借鉴。
第二部分:一种极为优秀的主键生成策略
flickr开发团队在2010年撰文介绍了flickr使用的一种主键生成测策略,同时表示该方案在flickr上的实际运行效果也非常令人满意,原文连接:Ticket
Servers: Distributed Unique Primary Keys on the Cheap 这个方案是我目前知道的最好的方案,它与一般Sequence表方案有些类似,但却很好地解决了性能瓶颈和单点问题,是一种非常可靠而高效的全局主键生成方案。

图1. flickr采用的sharding主键生成方案示意图(点击查看大图)
flickr这一方案的整体思想是:建立两台以上的数据库ID生成服务器,每个服务器都有一张记录各表当前ID的Sequence表,但是Sequence中ID增长的步长是服务器的数量,起始值依次错开,这样相当于把ID的生成散列到了每个服务器节点上。例如:如果我们设置两台数据库ID生成服务器,那么就让一台的Sequence表的ID起始值为1,每次增长步长为2,另一台的Sequence表的ID起始值为2,每次增长步长也为2,那么结果就是奇数的ID都将从第一台服务器上生成,偶数的ID都从第二台服务器上生成,这样就将生成ID的压力均匀分散到两台服务器上,同时配合应用程序的控制,当一个服务器失效后,系统能自动切换到另一个服务器上获取ID,从而保证了系统的容错。
关于这个方案,有几点细节这里再说明一下:
1. flickr的数据库ID生成服务器是专用服务器,服务器上只有一个数据库,数据库中表都是用于生成Sequence的,这也是因为auto-increment-offset和auto-increment-increment这两个数据库变量是数据库实例级别的变量。
2. flickr的方案中表格中的stub字段只是一个char(1) NOT NULL存根字段,并非表名,因此,一般来说,一个Sequence表只有一条纪录,可以同时为多张表生成ID,如果需要表的ID是有连续的,需要为该表单独建立Sequence表。
3. 方案使用了mysql的LAST_INSERT_ID()函数,这也决定了Sequence表只能有一条记录。
4. 使用REPLACE INTO插入数据,这是很讨巧的作法,主要是希望利用mysql自身的机制生成ID,不仅是因为这样简单,更是因为我们需要ID按照我们设定的方式(初值和步长)来生成。
5. SELECT LAST_INSERT_ID()必须要于REPLACE INTO语句在同一个数据库连接下才能得到刚刚插入的新ID,否则返回的值总是0
6. 该方案中Sequence表使用的是MyISAM引擎,以获取更高的性能,注意:MyISAM引擎使用的是表级别的锁,MyISAM对表的读写是串行的,因此不必担心在并发时两次读取会得到同一个ID(另外,应该程序也不需要同步,每个请求的线程都会得到一个新的connection,不存在需要同步的共享资源)。经过实际对比测试,使用一样的Sequence表进行ID生成,MyISAM引擎要比InnoDB表现高出很多!
7. 可使用纯JDBC实现对Sequence表的操作,以便获得更高的效率,实验表明,即使只使用Spring JDBC性能也不及纯JDBC来得快!
实现该方案,应用程序同样需要做一些处理,主要是两方面的工作:
1. 自动均衡数据库ID生成服务器的访问
2. 确保在某个数据库ID生成服务器失效的情况下,能将请求转发到其他服务器上执行。
本系列相关文章:
数据库分库分表(sharding)系列(一)
拆分实施策略和示例演示
数据库分库分表(sharding)系列(二)
全局主键生成策略
数据库分库分表(sharding)系列(三)
关于使用框架还是自主开发以及sharding实现层面的考量
数据库Sharding的基本思想和切分策略