Windows 批处理与Linux Shell比较[命令比较]
 Windows的copy命令:
Windows的copy命令:
copy “c:\new folder\1.txt” c:
copy “c:\new folder\1.txt” c:\2.txt
Linux的cp和Windows的cp命令:
cp ~/a.txt ~/test (cp c:\1.txt c:\test2)
cp ~/a.txt ~/test/b.txt (cp c:\1.txt c:\3.txt)
在Windows上推荐robocopy,功能强大,更多的返回值,例如:
robocopy /E /NP /R:12 SourceDir DestinationDir *.txt *.doc /XF test.txt /xd test [从SourceDir拷贝所有的txt和doc文件到DestinationDir,其中排除test.txt和子文件夹下test]
Printf %3d 2 [格式为__2]
printf %-3d 2 [格式为2__]
Printf %03d 2 [格式为002]
Printf %1.2f 3.1415926 [格式为3.14]
printf %8s "aaaa" [格式为____aaaa]
printf "\nXXX: %03d\n" 3 [格式为__3]
Specifier
Description
%c
ASCII character (prints first character of corresponding argument)
%d
Decimal integer
%i
Same as %d
%e
Floating-point format ([-]d.precisione[+-]dd) (see following text for meaning of precision)
%E
Floating-point format ([-]d.precisionE[+-]dd)
%f
Floating-point format ([-]ddd.precision)
%g
%e or %f conversion, whichever is shorter, with trailing zeros removed
%G
%E or %f conversion, whichever is shortest, with trailing zeros removed
%o
Unsigned octal value
%s
String
%u
Unsigned decimal value
%x
Unsigned hexadecimal number; uses a-f for 10 to 15
%X
Unsigned hexadecimal number; uses A-F for 10 to 15
%%
Literal %
expr 5 + 7
expr 5 – 6
expr 5 ”*” 4
expr 5 / 7
expr 7 % 9
expr 1 “|” 0
expr 1 “&” 0
expr 3 “>” 6
expr 3 “<” 6
expr 3 “>=” 3
expr 3 “<=” 3
expr 3 = 3
expr 3 != 3
expr expr1 : re [用re正则表达式在expr1中求解]
expr index expr1 expr2 [取index]
expr substr expr1 expr2 expr3 [取substring]
expr length "abcdef" [取长度]
expr length "abcdef" "<" 5 "|" 15 - 4 ">" 8
awk '{print $0}' scores.txt [打印scores.txt的每一行]
awk '{if($2 ^> "60") print $0}' scores.txt [打印scores.txt的所有第二列大于60的所有行]
awk 'BEGIN {print "start "} {tot+=$2} END {print "totoal is:" tot; print "END"}' scores.txt [将scores.txt中的所有的行的第二列求和]
"} {tot+=$2} END {print "totoal is:" tot; print "END"}' scores.txt [将scores.txt中的所有的行的第二列求和]
awk '{print length($2)}' scores.txt [打印所有行的第二列的长度]
1 awk内置变量
A R G C 命令行参数个数
A R G V 命令行参数排列
E N V I R O N 支持队列中系统环境变量的使用
FILENAME a w k浏览的文件名
F N R 浏览文件的记录数
N F 浏览记录的域个数
N R 已读的记录数
O F S 输出域分隔符
O R S 输出记录分隔符
F S控制域分割符
R S 控制记录分隔符
2 awk操作符
= += *= / = %= ^ = 赋值操作符
? 条件表达操作符
|| && ! 并、与、非(上一节已讲到)
~!~ 匹配操作符,包括匹配和不匹配
< <= == != >> 关系操作符
+ - * / % ^ 算术操作符
+ + -- 前缀和后缀
3 awk支持函数
g s u b ( r, s ) 在整个$ 0中用s替代r
g s u b ( r, s , t ) 在整个t中用s替代r
i n d e x ( s , t ) 返回s中字符串t的第一位置
l e n g t h ( s ) 返回s长度
m a t c h ( s , r ) 测试s是否包含匹配r的字符串
s p l i t ( s , a , f s ) 在f s上将s分成序列a
s p r i n t ( f m t , e x p ) 返回经f m t格式化后的e x p
s u b ( r, s ) 用$ 0中最左边最长的子串代替s
s u b s t r ( s , p ) 返回字符串s中从p开始的后缀部分
s u b s t r ( s , p , n ) 返回字符串s中从p开始长度为n的后缀部分
4 awk支持print 和 printf
sed ‘=' test.txt [打印文件且显示行号]
sed 's/tom/tom2010/g' test.txt [将文件中的所有的tom替换为tom2010]
sed '5,6d' test.txt [删除文件5到6行]
sed '10a\abcd' test.txt [在第10行后增加abcd]
sed '/unix/i\adflajflad\n\adfadfajdlf' test.txt [在unix前插入adflajflad\n\adfadfajdlf]
Sed ‘1c\aaaa’ test.txt [修改第一行为aaaa]
sed ‘4q’ test.txt [处理到第4行退出]
sed '2r 1.txt' test.txt [将文件1.txt读入到文件test.txt的第二行]
-e 允许对同一行进行多次编辑,每一次编辑用到的命令都必须跟在一个-e后面。
-n 取消默认的输出。
查询:
x x为一行号,如1
x , y 表示行号范围从x到y,如2,5表示从第2行到第5行
/ p a t t e r n / 查询包含模式的行。例如/ d i s k /或/[a-z]/
/ p a t t e r n / p a t t e r n / 查询包含两个模式的行。例如/ d i s k / d i s k s /
p a t t e r n / , x 在给定行号上查询包含模式的行。如/ r i b b o n / , 3
x , / p a t t e r n / 通过行号和模式查询匹配行。3 . / v d u /
x , y ! 查询不包含指定行号x和y的行。1 , 2 !
[:alnum:] Alphanumeric [a-z A-Z 0-9] [:alpha:] Alphabetic [a-z A-Z] [:blank:] Spaces or tabs [:cntrl:]
Any control characters [:digit:] Numeric digits [0-9] [:graph:] Any visible characters (no whitespace)
[:lower:] Lower-case [a-z] [:print:] Non-control characters [:punct:] Punctuation characters
[:space:] Whitespace [:upper:] Upper-case [A-Z] [:xdigit:] hex digits [0-9 a-f A-F]
sed编辑命令:
p 打印匹配行
= 显示文件行号
a \ 在定位行号后附加新文本信息
i \ 在定位行号后插入新文本信息
d 删除定位行
c \ 用新文本替换定位文本
s 使用替换模式替换相应模式
r 从另一个文件中读文本
w 写文本到一个文件
q 第一个模式匹配完成后推出或立即推出
l 显示与八进制A S C I I代码等价的控制字符
{ } 在定位行执行的命令组
n 从另一个文件中读文本下一行,并附加在下一行
g 将模式2粘贴到/pattern n/
y 传送字符
n 延续到下一输入行;允许跨行的模式匹配语句
替换选项如下:
g 缺省情况下只替换第一次出现模式,使用g选项替换全局所有出现模式。
p 缺省s e d将所有被替换行写入标准输出,加p选项将使- n选项无效。- n选项不打印输出
结果。
w 文件名使用此选项将输出定向到一个文件。
sed中的一些特殊定义是 规则 表达式 描述
/./ 将与包含至少一个字符的任何行匹配
/../ 将与包含至少两个字符的任何行匹配
/^#/ 将与以 '#' 开始的任何行匹配
/^$/ 将与所有空行匹配
/}^/ 将与以 '}'(无空格)结束的任何行匹配
/} *^/ 将与以 '}' 后面跟有 零或多个空格结束的任何行匹配
/[abc]/ 将与包含小写 'a'、'b' 或 'c' 的任何行匹配
/^[abc]/ 将与以 'a'、'b' 或 'c' 开始的任何行匹配
grep "map" test.txt [在test.txt中查找map]
grep "map" *.txt [在所有的txt中查找map]
grep -c “aud“ test.txt [在test.txt中查找aud且只输出匹配的行号]
grep -n “aud“ test.txt [在test.txt中查找aud且输出匹配的行和行号]
grep -v “aud“ test.txt [显示所有不包含aud的所有的行号]
grep -i “aud“ test.txt [在test.txt中查找aud且不区分大小写]
常用的g r e p选项有:
-c 只输出匹配行的计数。
-i 不区分大小写(只适用于单字符)。
-h 查询多文件时不显示文件名。
-l 查询多文件时只输出包含匹配字符的文件名。
-n 显示匹配行及行号。
-s 不显示不存在或无匹配文本的错误信息。
-v 显示不包含匹配文本的所有行。
一 Windows Dos与Linux 相同的内部命令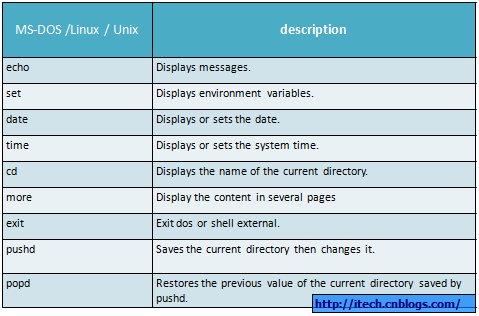
二 Windows Dos与Linux 不同的内部命令
三 Windows Dos与Linux 不同的内部命令2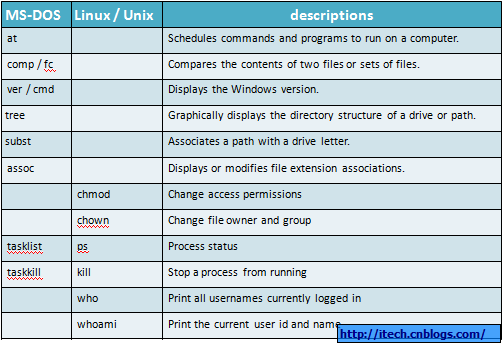
四 Windows Dos与Linux 不同的外部命令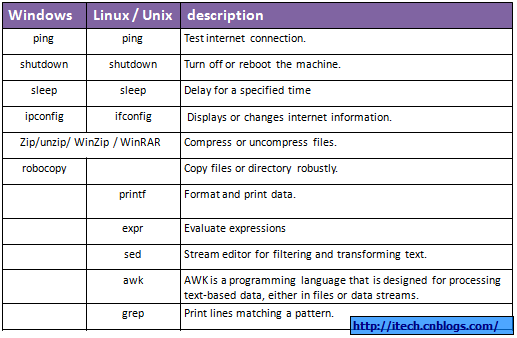
五 命令帮助
五 更多参考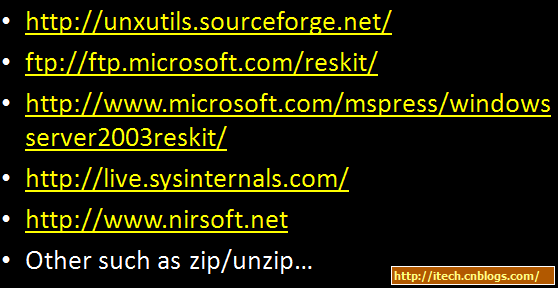
六 Linux命令在Windows上执行
几乎所有的Linux的命令都同时被编译为Windows的exe版本,所以我们可以在Windows上使用所有的Linux的命令。更多参考:
1)http://unxutils.sourceforge.net
2)http://www.cnblogs.com/itech/archive/2009/05/22/1487120.html
七 有用但是不常用的命令
1)robocopy用来copy
Windows的copy命令:copy “c:\new folder\1.txt” c:copy “c:\new folder\1.txt” c:\2.txtLinux的cp和Windows的cp命令:cp ~/a.txt ~/test (cp c:\1.txt c:\test2)cp ~/a.txt ~/test/b.txt (cp c:\1.txt c:\3.txt)在Windows上推荐robocopy,功能强大,更多的返回值,例如:robocopy /E /NP /R:12 SourceDir DestinationDir *.txt *.doc /XF test.txt /xd test [从SourceDir拷贝所有的txt和doc文件到DestinationDir,其中排除test.txt和子文件夹下test]2)printf用来格式为字符串
Printf %3d 2 [格式为__2]printf %-3d 2 [格式为2__]Printf %03d 2 [格式为002]Printf %1.2f 3.1415926 [格式为3.14]printf %8s "aaaa" [格式为____aaaa]printf "\nXXX: %03d\n" 3 [格式为__3]所有的printf的格式参数:
SpecifierDescription%cASCII character (prints first character of corresponding argument)%dDecimal integer%iSame as %d%eFloating-point format ([-]d.precisione[+-]dd) (see following text for meaning of precision)%EFloating-point format ([-]d.precisionE[+-]dd)%fFloating-point format ([-]ddd.precision)%g%e or %f conversion, whichever is shorter, with trailing zeros removed%G%E or %f conversion, whichever is shortest, with trailing zeros removed%oUnsigned octal value%sString%uUnsigned decimal value%xUnsigned hexadecimal number; uses a-f for 10 to 15%XUnsigned hexadecimal number; uses A-F for 10 to 15%%Literal %3)Expr用来表达式计算
expr 5 + 7 expr 5 – 6expr 5 ”*” 4 expr 5 / 7expr 7 % 9 expr 1 “|” 0 expr 1 “&” 0 expr 3 “>” 6 expr 3 “<” 6 expr 3 “>=” 3 expr 3 “<=” 3 expr 3 = 3 expr 3 != 3 expr expr1 : re [用re正则表达式在expr1中求解] expr index expr1 expr2 [取index]expr substr expr1 expr2 expr3 [取substring]expr length "abcdef" [取长度]expr length "abcdef" "<" 5 "|" 15 - 4 ">" 8 4)Awk用来处理文本数据库
awk '{print $0}' scores.txt [打印scores.txt的每一行]awk '{if($2 ^> "60") print $0}' scores.txt [打印scores.txt的所有第二列大于60的所有行]awk 'BEGIN {print "start"} {tot+=$2} END {print "totoal is:" tot; print "END"}' scores.txt [将scores.txt中的所有的行的第二列求和]awk '{print length($2)}' scores.txt [打印所有行的第二列的长度]awk参数:
1 awk内置变量A R G C 命令行参数个数A R G V 命令行参数排列E N V I R O N 支持队列中系统环境变量的使用FILENAME a w k浏览的文件名F N R 浏览文件的记录数N F 浏览记录的域个数N R 已读的记录数O F S 输出域分隔符O R S 输出记录分隔符F S控制域分割符R S 控制记录分隔符2 awk操作符= += *= / = %= ^ = 赋值操作符? 条件表达操作符|| && ! 并、与、非(上一节已讲到)~!~ 匹配操作符,包括匹配和不匹配< <= == != >> 关系操作符+ - * / % ^ 算术操作符+ + -- 前缀和后缀3 awk支持函数g s u b ( r, s ) 在整个$ 0中用s替代rg s u b ( r, s , t ) 在整个t中用s替代ri n d e x ( s , t ) 返回s中字符串t的第一位置l e n g t h ( s ) 返回s长度m a t c h ( s , r ) 测试s是否包含匹配r的字符串s p l i t ( s , a , f s ) 在f s上将s分成序列as p r i n t ( f m t , e x p ) 返回经f m t格式化后的e x ps u b ( r, s ) 用$ 0中最左边最长的子串代替ss u b s t r ( s , p ) 返回字符串s中从p开始的后缀部分s u b s t r ( s , p , n ) 返回字符串s中从p开始长度为n的后缀部分4 awk支持print 和 printf5)sed [选项] s e d命令 输入文件。
sed ‘=' test.txt [打印文件且显示行号]sed 's/tom/tom2010/g' test.txt [将文件中的所有的tom替换为tom2010]sed '5,6d' test.txt [删除文件5到6行]sed '10a\abcd' test.txt [在第10行后增加abcd]sed '/unix/i\adflajflad\n\adfadfajdlf' test.txt [在unix前插入adflajflad\n\adfadfajdlf]Sed ‘1c\aaaa’ test.txt [修改第一行为aaaa]sed ‘4q’ test.txt [处理到第4行退出]sed '2r 1.txt' test.txt [将文件1.txt读入到文件test.txt的第二行]其他的sed参数:
-e 允许对同一行进行多次编辑,每一次编辑用到的命令都必须跟在一个-e后面。-n 取消默认的输出。查询:x x为一行号,如1x , y 表示行号范围从x到y,如2,5表示从第2行到第5行/ p a t t e r n / 查询包含模式的行。例如/ d i s k /或/[a-z]// p a t t e r n / p a t t e r n / 查询包含两个模式的行。例如/ d i s k / d i s k s /p a t t e r n / , x 在给定行号上查询包含模式的行。如/ r i b b o n / , 3x , / p a t t e r n / 通过行号和模式查询匹配行。3 . / v d u /x , y ! 查询不包含指定行号x和y的行。1 , 2 ![:alnum:] Alphanumeric [a-z A-Z 0-9] [:alpha:] Alphabetic [a-z A-Z] [:blank:] Spaces or tabs [:cntrl:]
Any control characters [:digit:] Numeric digits [0-9] [:graph:] Any visible characters (no whitespace)
[:lower:] Lower-case [a-z] [:print:] Non-control characters [:punct:] Punctuation characters
[:space:] Whitespace [:upper:] Upper-case [A-Z] [:xdigit:] hex digits [0-9 a-f A-F]
sed编辑命令:p 打印匹配行= 显示文件行号a \ 在定位行号后附加新文本信息i \ 在定位行号后插入新文本信息d 删除定位行c \ 用新文本替换定位文本s 使用替换模式替换相应模式r 从另一个文件中读文本w 写文本到一个文件q 第一个模式匹配完成后推出或立即推出l 显示与八进制A S C I I代码等价的控制字符{ } 在定位行执行的命令组n 从另一个文件中读文本下一行,并附加在下一行g 将模式2粘贴到/pattern n/y 传送字符n 延续到下一输入行;允许跨行的模式匹配语句替换选项如下:g 缺省情况下只替换第一次出现模式,使用g选项替换全局所有出现模式。p 缺省s e d将所有被替换行写入标准输出,加p选项将使- n选项无效。- n选项不打印输出结果。w 文件名使用此选项将输出定向到一个文件。sed中的一些特殊定义是 规则 表达式 描述
/./ 将与包含至少一个字符的任何行匹配
/../ 将与包含至少两个字符的任何行匹配
/^#/ 将与以 '#' 开始的任何行匹配
/^$/ 将与所有空行匹配
/}^/ 将与以 '}'(无空格)结束的任何行匹配
/} *^/ 将与以 '}' 后面跟有 零或多个空格结束的任何行匹配
/[abc]/ 将与包含小写 'a'、'b' 或 'c' 的任何行匹配
/^[abc]/ 将与以 'a'、'b' 或 'c' 开始的任何行匹配
6)grep
grep "map" test.txt [在test.txt中查找map]grep "map" *.txt [在所有的txt中查找map]grep -c “aud“ test.txt [在test.txt中查找aud且只输出匹配的行号]grep -n “aud“ test.txt [在test.txt中查找aud且输出匹配的行和行号]grep -v “aud“ test.txt [显示所有不包含aud的所有的行号]grep -i “aud“ test.txt [在test.txt中查找aud且不区分大小写]其他的参数:
常用的g r e p选项有:-c 只输出匹配行的计数。-i 不区分大小写(只适用于单字符)。-h 查询多文件时不显示文件名。-l 查询多文件时只输出包含匹配字符的文件名。-n 显示匹配行及行号。-s 不显示不存在或无匹配文本的错误信息。-v 显示不包含匹配文本的所有行。八 完!