beauties.xml
- <?xml version="1.0" encoding="UTF-8"?>
- <beauties>
- <beauty>
- <name>林志玲</name>
- <age>28</age>
- </beauty>
- <beauty>
- <name>杨幂</name>
- <age>23</age>
- </beauty>
- </beauties>
main.xml
- <?xml version="1.0" encoding="utf-8"?>
- <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
- android:orientation="vertical"
- android:layout_width="fill_parent"
- android:layout_height="fill_parent"
- >
- <TextView
- android:id="@+id/textView"
- android:layout_width="fill_parent"
- android:layout_height="wrap_content"
- />
- </LinearLayout>
activity的代码:
- package cn.com.saxtest;
- import java.io.InputStream;
- import java.util.ArrayList;
- import javax.xml.parsers.SAXParser;
- import javax.xml.parsers.SAXParserFactory;
- import org.xml.sax.Attributes;
- import org.xml.sax.SAXException;
- import org.xml.sax.helpers.DefaultHandler;
- import android.app.Activity;
- import android.os.Bundle;
- import android.util.Log;
- import android.widget.TextView;
- /**
- *
- * @author chenzheng_java
- * @description 使用sax解析方式解析xml
- * @since 2010/03/04
- *
- */
- public class SaxParserActivity extends Activity {
- private ArrayList<Beauty> beautyList = new ArrayList<Beauty>();
- private Beauty beauty = null;
- @Override
- public void onCreate(Bundle savedInstanceState) {
- super.onCreate(savedInstanceState);
- setContentView(R.layout.main);
- SAXParserFactory factory = SAXParserFactory.newInstance();
- try {
- SAXParser parser = factory.newSAXParser();
- InputStream inputStream = this.getClassLoader()
- .getResourceAsStream("beauties.xml");
- parser.parse(inputStream, new MyDefaultHandler());
- String result = "";
- for(Beauty beauty:beautyList){
- result+="/n "+beauty.toString();
- }
- TextView textView = (TextView) findViewById(R.id.textView);
- textView.setText(result);
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- /**
- *
- * @author chenzheng_java
- * @description 一定要注意,这里是使用的内部类哦。 有些朋友可能有疑问,不用内部类不可以,答案是:当然可以。
- * 这里用内部类的目的其实就是为了提高一丁点效率而已。 如果你喜欢看源码,你就会发现,源码中大量的使用了内部类的。
- *
- */
- private class MyDefaultHandler extends DefaultHandler {
- // 存储目前为止读取到的最后一个element的localname
- private String currentElementName = "";
- /**
- * characters (char ch[], int start, int length)当解析xml中遇到文本内容时会执行。 ch
- * 这个数组中存放的是整个xml文件的字符串的数组形式 start是当前解析的文本在整个xml字符串文件中的开始位置
- * length是当前解析的文本内容的长度 由上面的介绍我们可以知道,我们可以通过new
- * String(ch,start,length)方法来获取我们正解析的文本内容
- */
- @Override
- public void characters(char[] ch, int start, int length)
- throws SAXException {
- Log.i("currentElementName", currentElementName);
- String textContent = new String(ch, start, length);
- if(currentElementName.equals("name")&&textContent!=null&&!textContent.trim().equals("")){
- Log.i("textContent name", textContent);
- beauty.setName(textContent);
- }
- if(currentElementName.equals("age")&&textContent!=null&&!textContent.trim().equals("")){
- Log.i("textContent age", textContent);
- beauty.setAge(textContent);
- }
- }
- /**
- *解析到xml文档的末尾时触发
- */
- @Override
- public void endDocument() throws SAXException {
- }
- /**
- * 解析到元素的末尾时触发
- */
- @Override
- public void endElement(String uri, String localName, String qName)
- throws SAXException {
- if(localName.equals("beauty")){
- beautyList.add(beauty);
- Log.i("beauty", beauty.toString());
- }
- }
- /**
- * 开始解析xml时触发
- */
- @Override
- public void startDocument() throws SAXException {
- }
- /**
- * 解析到元素的开始处触发 startElement (String uri, String localName, String qName,
- * Attributes attributes) uri:Namespace值,当用户没有明确指定以及当命名空间没有被使用的时候,为null
- * localName:element的名称,或者通俗点叫标签的名称。如<name>中的name就是localName qName:
- * 和localName的唯一其别是
- * ,当标签有namespace时,该值返回的数据为全限定名称。例如<chen:name>中,localName为name
- * ,qName为chen:name attributes:元素包含的属性对象。如果没有属性时,返回一个空的属性对象
- */
- @Override
- public void startElement(String uri, String localName, String qName,
- Attributes attributes) throws SAXException {
- currentElementName = localName;
- if(localName.equals("beauty")){
- beauty = new Beauty();
- }
- }
- }
- /**
- *
- * @author chenzheng 这里使用内部类是为了效率考虑,内部类要比单独顶一个bean类更加的高效以及节约空间
- *
- */
- private class Beauty {
- String name;
- String age;
- public String getName() {
- return name;
- }
- public void setName(String name) {
- this.name = name;
- }
- public String getAge() {
- return age;
- }
- public void setAge(String age) {
- this.age = age;
- }
- @Override
- public String toString() {
- return "美女资料 [年龄=" + getAge() + ", 姓名=" + getName() + "]";
- }
- }
- }
运行后就会得到想要的结果了、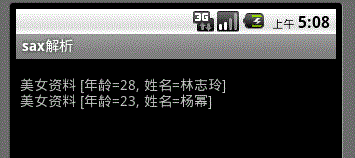
代码结构:
----------------------------------------------------------------------------------------------------------
下面,再让我们一起讨论点废话:
2. 使用SAX 加载XML文件时,他的操作像打开一个“顺序的文件字符流”,在读到XML元素的开始标记,结尾标记和内容标记时将产生一系列的事件
如一个简单的XML文件:<hello><message>hello XML!</message></hello>
会相应的触发:startDocument, startElement, characters, endElement, endDocument, 只需编写这些事件处理程序就可以解析XML文件了
3. SAX 可以高效的使用内存,因为SAX 只是顺序的读取XML 文件的内容,并不会将XML 文件完全加载,这样就比DOM 的处理效率高
但SAX 只能读取XML 文件的内容,而不能更改XML 的内容,也不能随机访问XML 元素
4. 在SAX 中有4个处理器是要实现的:ContentHandler,DTDHandler,EntityResolver,ErrorHandler,以处理不同的事件,这是比较麻烦的,
幸好SAX 定义了一个 DefaultHandler 类把这几个实现了,我们只需在 DefaultHandler中定义事件处理方法,然后注册到XMLReader,而SAXParser封装了XMLReader的实现类,
SAXParser又是由SAXParserFactory提供的,所以我们实际用到的类只有:SAXParserFactory,SAXParser,DefaultHandler
5. SAX 的解析步骤:
(1)写一个类继承 DefaultHandler, 实现自己的事件处理方法
(2)在主程序中建立 SAXParserFactory
(3)可以设置这个factory 的参数
(4)从这个factory 得到SAXParser
(5)解析XML文件