很多书阐述了EM algorithm的原理,直接点可以在维基百科上找到它的基本情况:
http://en.wikipedia.org/wiki/Expectation%E2%80%93maximization_algorithm。
EM算法分两步走即E步和M步,和很多书本和文章中一样,维基中只给出了核心结论,至于其中的数理逻辑关系并没有给出,需要探究EM算法的推导过程可以参考JerryLead的博客内容,博主整理翻译了Standford的课件:
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html
概况起来,EM(Expectation Maximization)是一种迭代的方法,主要是用来求后验分布的众数,每一步迭代都由E(Expectation)和M(Maximization)组成。
1.E步、M步具体思路如下:
一般情况下,我们将给定y条件的x的密度函数记作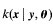 ,根据条件密度函数公式,我们有
,根据条件密度函数公式,我们有
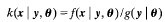 (1)
(1)
上式的样本空间为X,y通常是给定样本,对于上式我们取对数,可以得到
 (2)
(2)
其中
 ,
,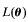 =
=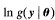 ,
,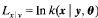
对于(2)式等式两边求期望,等式依然成立。期望要求知道给定y的x的条件密度函数,增加样本的条件密度函数
 (3)
(3)
上式中

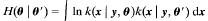
由Jensen's不等式(详见JerryLead博文)我们知道,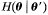 在'
在'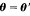 时取到最大值,此时同样有
时取到最大值,此时同样有
 (4)
(4)
(4)式是EM算法的核心等式,该式子是迭代的最终结果。每一步迭代后都能提高后验分布密度函数值,迭代到函数收敛为止。
2.EM算法迭代过程
假设当前是p次循环
a.E步,首先计算

b.M步,找到使上式最大化得到![]()
c.返回a,直至方程收敛
3.EM算法的应用
EM算法主要用于混合分布的参数估计、缺失数据等,见链接:
http://www2.math.umd.edu/~slud//s705/LecNotes/Sec6NotF09.pdf
http://www.stat.sc.edu/~grego/courses/stat740/normem.txt