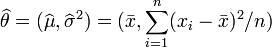在语音识别中,概率模型占了至关重要的地位,在学习语音识别技术前,自己还是好好整理一下相关的概率知识。
1.似然估计
1.1原理
在数理统计学中,似然函数是一种关于统计模型中的参数的函数,表示模型参数中的似然性。似然函数在统计推断中有重大作用,如在最大似然估计和费雪信息之中的应用等等。“似然性”与“或然性”或“概率”意思相近,都是指某种事件发生的可能性,但是在统计学中,“似然性”和“或然性”或“概率”又有明确的区分。概率用于在已知一些参数的情况下,预测接下来的观测所得到的结果,而似然性则是用于在已知某些观测所得到的结果时,对有关事物的性质的参数进行估计。
在这种意义上,似然函数可以理解为条件概率的逆反。在已知某个参数B时,事件A会发生的概率写作:

利用贝叶斯定理,

因此,我们可以反过来构造表示似然性的方法:已知有事件A发生,运用似然函数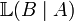 ,我们估计参数B的可能性。形式上,似然函数也是一种条件概率函数,但我们关注的变量改变了:
,我们估计参数B的可能性。形式上,似然函数也是一种条件概率函数,但我们关注的变量改变了:
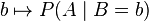
注意到这里并不要求似然函数满足归一性: 。一个似然函数乘以一个正的常数之后仍然是似然函数。对所有
。一个似然函数乘以一个正的常数之后仍然是似然函数。对所有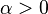 ,都可以有似然函数:
,都可以有似然函数:

1.2例子

两次投掷都正面朝上时的似然函数
考虑投掷一枚硬币的实验。通常来说,已知投出的硬币正面朝上和反面朝上的概率各自是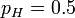 ,便可以知道投掷若干次后出现各种结果的可能性。比如说,投两次都是正面朝上的概率是0.25。用条件概率表示,就是:
,便可以知道投掷若干次后出现各种结果的可能性。比如说,投两次都是正面朝上的概率是0.25。用条件概率表示,就是:
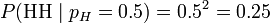
其中H表示正面朝上。
在统计学中,我们关心的是在已知一系列投掷的结果时,关于硬币投掷时正面朝上的可能性的信息。
我们可以建立一个统计模型:假设硬币投出时会有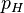 的概率正面朝上,而有
的概率正面朝上,而有
的概率反面朝上。
这时,条件概率可以改写成似然函数:
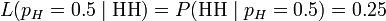
也就是说,对于取定的似然函数,在观测到两次投掷都是正面朝上时, 的似然性是0.25(这并不表示当观测到两次正面朝上时
的概率是0.25)。
如果考虑 ,那么似然函数的值也会改变。
,那么似然函数的值也会改变。
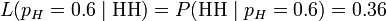

三次投掷中头两次正面朝上,第三次反面朝上时的似然函数
注意到似然函数的值变大了。
这说明,如果参数 的取值变成0.6的话,结果观测到连续两次正面朝上的概率要比假设
时更大。也就是说,参数 取成0.6 要比取成0.5 更有说服力,更为“合理”。总之,似然函数的重要性不是它的具体取值,而是当参数变化时函数到底变小还是变大。对同一个似然函数,如果存在一个参数值,使得它的函数值达到最大的话,那么这个值就是最为“合理”的参数值。
在这个例子中,似然函数实际上等于:
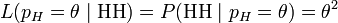 , 其中
, 其中 。
。
如果取 ,那么似然函数达到最大值1。也就是说,当连续观测到两次正面朝上时,假设硬币投掷时正面朝上的概率为1是最合理的。
,那么似然函数达到最大值1。也就是说,当连续观测到两次正面朝上时,假设硬币投掷时正面朝上的概率为1是最合理的。
类似地,如果观测到的是三次投掷硬币,头两次正面朝上,第三次反面朝上,那么似然函数将会是:
 , 其中T表示反面朝上,。
, 其中T表示反面朝上,。
这时候,似然函数的最大值将会在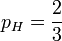 的时候取到。也就是说,当观测到三次投掷中前两次正面朝上而后一次反面朝上
的时候取到。也就是说,当观测到三次投掷中前两次正面朝上而后一次反面朝上
2最大后验估计
2.1原理
最大后验估计是根据经验数据获得对难以观察的量的点估计。与最大似然估计类似,但是最大的不同时,最大后验估计的融入了要估计量的先验分布在其中。故最大后验估计可以看做规则化的最大似然估计。
首先,我们回顾上篇文章中的最大似然估计,假设x为独立同分布的采样,θ为模型参数,f为我们所使用的模型。那么最大似然估计可以表示为:

现在,假设θ的先验分布为g。通过贝叶斯理论,对于θ的后验分布如下式所示:

最后验分布的目标为:

注:最大后验估计可以看做贝叶斯估计的一种特定形式。
2.2例子
假设有五个袋子,各袋中都有无限量的饼干(樱桃口味或柠檬口味),已知五个袋子中两种口味的比例分别是
樱桃 100%
樱桃 75% + 柠檬 25%
樱桃 50% + 柠檬 50%
樱桃 25% + 柠檬 75%
柠檬 100%
如果只有如上所述条件,那问从同一个袋子中连续拿到2个柠檬饼干,那么这个袋子最有可能是上述五个的哪一个?
我们首先采用最大似然估计来解这个问题,写出似然函数。假设从袋子中能拿出柠檬饼干的概率为p(我们通过这个概率p来确定是从哪个袋子中拿出来的),则似然函数可以写作

由于p的取值是一个离散值,即上面描述中的0,25%,50%,75%,1。我们只需要评估一下这五个值哪个值使得似然函数最大即可,得到为袋子5。这里便是最大似然估计的结果。
上述最大似然估计有一个问题,就是没有考虑到模型本身的概率分布,下面我们扩展这个饼干的问题。
假设拿到袋子1或5的机率都是0.1,拿到2或4的机率都是0.2,拿到3的机率是0.4,那同样上述问题的答案呢?这个时候就变MAP了。我们根据公式

写出我们的MAP函数。

根据题意的描述可知,p的取值分别为0,25%,50%,75%,1,g的取值分别为0.1,0.2,0.4,0.2,0.1.分别计算出MAP函数的结果为:0,0.0125,0.125,0.28125,0.1.由上可知,通过MAP估计可得结果是从第四个袋子中取得的最高。
上述都是离散的变量,那么连续的变量呢?假设 为独立同分布的
为独立同分布的 ,μ有一个先验的概率分布为
,μ有一个先验的概率分布为 。那么我们想根据来找到μ的最大后验概率。根据前面的描述,写出MAP函数为:
。那么我们想根据来找到μ的最大后验概率。根据前面的描述,写出MAP函数为:

此时我们在两边取对数可知。所求上式的最大值可以等同于求

的最小值。求导可得所求的μ为

以上便是对于连续变量的MAP求解的过程。
在MAP中我们应注意的是:
MAP与MLE最大区别是MAP中加入了模型参数本身的概率分布,或者说。MLE中认为模型参数本身的概率的是均匀的,即该概率为一个固定值。
3 最大似然估计
3.1原理
给定一个概率分布 ,假定其概率密度函数(连续分布)或概率聚集函数(离散分布)为
,假定其概率密度函数(连续分布)或概率聚集函数(离散分布)为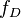 ,以及一个分布参数
,以及一个分布参数 ,我们可以从这个分布中抽出一个具有
,我们可以从这个分布中抽出一个具有 个值的采样
个值的采样 ,通过利用,我们就能计算出其概率:
,通过利用,我们就能计算出其概率:
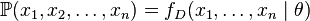
但是,我们可能不知道的值,尽管我们知道这些采样数据来自于分布。那么我们如何才能估计出呢?一个自然的想法是从这个分布中抽出一个具有个值的采样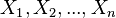 ,然后用这些采样数据来估计.
,然后用这些采样数据来估计.
一旦我们获得,我们就能从中找到一个关于的估计。最大似然估计会寻找关于的最可能的值(即,在所有可能的取值中,寻找一个值使这个采样的“可能性”最大化)。这种方法正好同一些其他的估计方法不同,如的非偏估计,非偏估计未必会输出一个最可能的值,而是会输出一个既不高估也不低估的值。
要在数学上实现最大似然估计法,我们首先要定义似然函数:
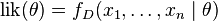
并且在的所有取值上,使这个函数最大化(一阶导数)。这个使可能性最大的 值即被称为的最大似然估计。
值即被称为的最大似然估计。
注意
- 这里的似然函数是指
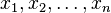 不变时,关于的一个函数。
不变时,关于的一个函数。 - 最大似然估计函数不一定是惟一的,甚至不一定存在。
3.2例子
离散分布,离散有限参数空间[编辑]
考虑一个抛硬币的例子。假设这个硬币正面跟反面轻重不同。我们把这个硬币抛80次(即,我们获取一个采样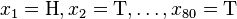 并把正面的次数记下来,正面记为H,反面记为T)。并把抛出一个正面的概率记为
并把正面的次数记下来,正面记为H,反面记为T)。并把抛出一个正面的概率记为 ,抛出一个反面的概率记为
,抛出一个反面的概率记为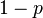 (因此,这里的即相当于上边的)。假设我们抛出了49个正面,31个反面,即49次H,31次T。假设这个硬币是我们从一个装了三个硬币的盒子里头取出的。这三个硬币抛出正面的概率分别为
(因此,这里的即相当于上边的)。假设我们抛出了49个正面,31个反面,即49次H,31次T。假设这个硬币是我们从一个装了三个硬币的盒子里头取出的。这三个硬币抛出正面的概率分别为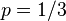 ,
,
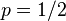 ,
,
 .这些硬币没有标记,所以我们无法知道哪个是哪个。使用最大似然估计,通过这些试验数据(即采样数据),我们可以计算出哪个硬币的可能性最大。这个似然函数取以下三个值中的一个:
.这些硬币没有标记,所以我们无法知道哪个是哪个。使用最大似然估计,通过这些试验数据(即采样数据),我们可以计算出哪个硬币的可能性最大。这个似然函数取以下三个值中的一个:
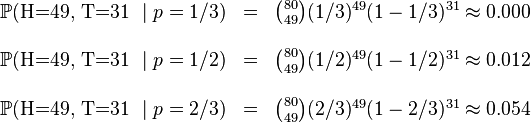
我们可以看到当 时,似然函数取得最大值。这就是的最大似然估计。
时,似然函数取得最大值。这就是的最大似然估计。
离散分布,连续参数空间[编辑]
现在假设例子1中的盒子中有无数个硬币,对于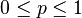 中的任何一个,
中的任何一个,
都有一个抛出正面概率为的硬币对应,我们来求其似然函数的最大值:
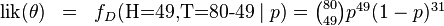
其中. 我们可以使用微分法来求最值。方程两边同时对取微分,并使其为零。
![\begin{matrix}
0 & = & \frac{d}{dp} \left( \binom{80}{49} p^{49}(1-p)^{31} \right) \\
& & \\
& \propto & 49p^{48}(1-p)^{31} - 31p^{49}(1-p)^{30} \\
& & \\
& = & p^{48}(1-p)^{30}\left[ 49(1-p) - 31p \right] \\
\end{matrix}](http://upload.wikimedia.org/math/f/4/3/f43c984e21445732edf403445fe32ea9.png)

在不同比例参数值下一个二项式过程的可能性曲线t = 3, n = 10;其最大似然估计值发生在其众数并在曲线的最大值处。
其解为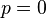 ,
,
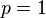 ,以及
,以及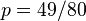 .使可能性最大的解显然是(因为和这两个解会使可能性为零)。因此我们说最大似然估计值为
.使可能性最大的解显然是(因为和这两个解会使可能性为零)。因此我们说最大似然估计值为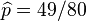 .
.
这个结果很容易一般化。只需要用一个字母 代替49用以表达伯努利试验中的被观察数据(即样本)的“成功”次数,用另一个字母代表伯努利试验的次数即可。使用完全同样的方法即可以得到最大似然估计值:
代替49用以表达伯努利试验中的被观察数据(即样本)的“成功”次数,用另一个字母代表伯努利试验的次数即可。使用完全同样的方法即可以得到最大似然估计值:
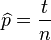
对于任何成功次数为,试验总数为的伯努利试验。
连续分布,连续参数空间[编辑]
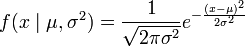
现在有个正态随机变量的采样点,要求的是一个这样的正态分布,这些采样点分布到这个正态分布可能性最大(也就是概率密度积最大,每个点更靠近中心点),其个正态随机变量的采样的对应密度函数(假设其独立并服从同一分布)为:
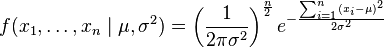
或:
 ,
,
这个分布有两个参数: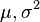 .有人可能会担心两个参数与上边的讨论的例子不同,上边的例子都只是在一个参数上对可能性进行最大化。实际上,在两个参数上的求最大值的方法也差不多:只需要分别把可能性
.有人可能会担心两个参数与上边的讨论的例子不同,上边的例子都只是在一个参数上对可能性进行最大化。实际上,在两个参数上的求最大值的方法也差不多:只需要分别把可能性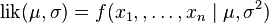 在两个参数上最大化即可。当然这比一个参数麻烦一些,但是一点也不复杂。使用上边例子同样的符号,我们有
在两个参数上最大化即可。当然这比一个参数麻烦一些,但是一点也不复杂。使用上边例子同样的符号,我们有 .
.
最大化一个似然函数同最大化它的自然对数是等价的。因为自然对数log是一个连续且在似然函数的值域内严格递增的上凸函数。[注意:可能性函数(似然函数)的自然对数跟信息熵以及Fisher信息联系紧密。]求对数通常能够一定程度上简化运算,比如在这个例子中可以看到:
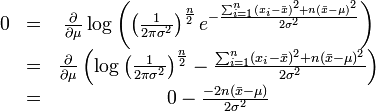
这个方程的解是 .这的确是这个函数的最大值,因为它是
.这的确是这个函数的最大值,因为它是 里头惟一的一阶导数等于零的点并且二阶导数严格小于零。
里头惟一的一阶导数等于零的点并且二阶导数严格小于零。
同理,我们对 求导,并使其为零。
求导,并使其为零。
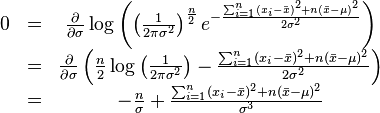
这个方程的解是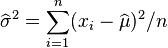 .
.
因此,其关于的最大似然估计为: