一、Cache的相关知识
二、TI DSP上的Cache结构
三、CCS Cache分析工具
四、实例
五、总结
一、Cache的相关知识
1、引入Cache的必要性
随着CPU主频的提升,带动系统性能的改善,但系统性能的提高不仅仅取决于CPU,还与系统架构、指令结构、信息在各个部件之间的传送速度及存储部件的存取速度等因素有关,特别是与CPU/内存之间的存取速度关系密切。若CPU工作速度较高,但内存存取速度较低,则造成CPU等待,降低处理速度,浪费CPU的能力。如2.5GHz的PⅢ,一次指令执行时间为0.4ns,与其相配的内存(DRAM如DDR2533)存取时间为1.876ns,比前者慢4.69倍。很显然是不能发挥整机的性能的。
如何减少CPU与内存之间的速度差异?慢速的DRAM和快速CPU之间插入一速度较快、容量较小的SRAM,起到缓冲作用;使CPU既可以以较快速度存取SRAM中的数据,又不使系统成本上升过高,这就是Cache法。它是PC系统在不大增加成本的前提下,使性能提升的一个非常有效的技术。
如何减少CPU与内存之间的速度差异?慢速的DRAM和快速CPU之间插入一速度较快、容量较小的SRAM,起到缓冲作用;使CPU既可以以较快速度存取SRAM中的数据,又不使系统成本上升过高,这就是Cache法。它是PC系统在不大增加成本的前提下,使性能提升的一个非常有效的技术。
同样的问题也出现在以DSP为核心的数字信号处理系统中。
高速运作的处理器需要与之相连的存储器达到其所要的速度。然而,二者却出现了变化的不一致性。一方面处理器速度增长很迅速,但是存储器却没有。使得与处理器相连接的存储器成为制约系统速度的瓶颈。
在此种情况下,小而快的Cache应运而生。它以与处理器相当的速度向处理器提供其需要的代码和数据,同时从慢速的存储器得到常用的数据并管理。
2、Cache工作方式
从上面的分析中,我们可以看到Cache需要得到CPU常用的数据才能提高系统性能。其工作在如下两种方式:
a、临时地点方式:
如果一个单元以前被使用了,那么它很可能被再次使用。在一个循环中取指令和数据的重复工作是很典型的一个例子。
b、空间地点方式:
位于当前使用单元附近的单元很可能在接下来的处理中被使用。顺序的取一个矩阵中的元素是很容易使用该方式的。
3、Cache工作性能评价
很容易理解,Cache的性能将有如下两个指标来评价:缺失率和命中率。
Cache的最小单元称为块(line),如果一个处理器所要求的数据的地址定位在Cache的某个块上,称为命中。反之为缺失。如果缺失发生,就需要到下一级的存储器上取得该数据。所以,缺失率是衡量Cache性能一项重要指标。缺失率越多,整个系统的性能就越低。另外,我们可以看到,当缺失发生,不但需要为处理器取得该数据,还要在Cache上权衡放不放该数据,以及放在哪里。这常常引起一个称为分配的过程,就是需要在Cache中为该数据安放一个新位置,其影响就是要拿走一个旧的元素。
我们可以将缺失分为如下三类:
a、必要的缺失:这些缺失发生在对于Cache的第一次寻找,这是因为在开始并没有给Cache机会去为处理器准备数据。它也被称为“第一次引用缺失”;
b、容量缺失:在程序执行过程中,Cache没有足够空间开放置数据。
c、冲突缺失:这些缺失发生是因为多于一个数据或是程序代码被安排在同一个Cache块上。
通过这样的分类,可以改善性能。对于容量缺失,我们可以减少在同一时间执行的程序和数据。而冲突缺失是我们研究的主要对象,我们可以经过改变数据和程序在存储器中的位置来使得其对应与不同的Cache块,从而消除冲突缺失。
二、TI DSP上的Cache结构
1、纵观TI数字信号处理器的Cache
TI的DSP有很多都包括一个或是多个Caches。TMS320C55xTM、TMS320C620x和TMS320C6701都有一个指令Cache,它是一个最近使用指令的缓冲区。
TMS320C6000TM系列的一些设备使用了两级Cache,分别作用于处理器指令和程序存储。
2、本文主要演示的C6455Cache结构
TMS320C64x+TMDSP(包括TMS320C6455设备)是TMS320C6000TMDSP平台的高性能定点DSP系列。C6455是由TI开发的基于第三代高性能、高级的VeloeiTITM超长指令体系。它是对包括视频、电信机构、医学成像、无线系统应用的非常好的选择。
C6455DSP集成了大量的片上存储,并把其组织为二级存储系统。第一级的程序和数据存储均有32KB。可以将这两部分作为映射存储或是Cache( TMS320C645x Bootloader User’s Guide,SPRUEC6)或是二者的联合。当配置为Cache时,L1P为直接映射Cache,L1D为2路组相联Cache。二级是程序和数据共用的2096KB。
下面主要对一级数据Cache的结构进行说明。后面的例子也主要讨论该部分的问题。
L1DCache结构
L1Cache的大小可以配置为4k到32k,其为2路组相联映射的Cache,意味着对于系统中的每个物理地址块在Cache中都有两个可能的位置安放它。当CPU想要取某地址的数据时,L1DCache要检查该地址在Cache中是否存在。CPU提供的32位地址被分为如下六个区域,如图所示:

六位的块内偏移表示L1D的块大小是64B。该六位Cache在逻辑上是不予理睬的,因为他们确定了块内哪个地址是要取的数据,因此他们对于Cache标记逻辑比较是不相关的。组区域表示数据可以存放在Cache中的L1DCache字块。其宽度取决于L1D被配置成Cache时的大小。使用组区域表示的位置寻找其存放的组,并检查每一个标记区域的每个有效位,这表示了该块存放的地址是否是我们所需求的。标记区域是地址的高字段,表示了数据元素存放的真正的物理位置。Cache将比较标记位在同组的两个块上。

如果组内有一个块的标记匹配了相应的要取地址的标记位,称为“命中”并把该地址数据直接传送给CPU。否则,称为读“缺失”,CPU等待,从二级存储中取的该数据。CPU也可以向L1D中写数据。当CPU存储时,L1D就像与读时一样比较标记位。当寻找到有效的标记,称为写“命中”,该数据直接写到L1D中。否则称为写“缺失”将该数据放在L1D的写缓冲中。该缓冲防止了CPU在写缺失时停转。因为CPU不需要在写操作时返回什么数据,所以它没必要在写向L2时停转。
置换和配置策略
另一项Cache的数据特征时将数据在L1D上驱逐到L2上。因为CPU可以重新定义L1D的目录,所以它必须可以更新其数据的物理地址。这种情况引起了L1D位置的更替。
L1DCache是只读分配Cache。意味着L1D取的其全部的64B数据只有在读操作缺失的时候发生。写缺失只是通过写缓冲写到L2上。其替换策略位是将最近最少使用的块替换掉。这可以保证在L1D中的块都是最常用的。
写操作
数据一致性要求。L1D是写回Cache。写命中直接在L1D中完成。其更新并不马上传递给L2或是存储系统。当Cache块被写入新的数据后,标记一位“脏”位。当该块要被新的块替换掉的时候L1D只将标记了有“脏”比特的数据写回,这个操作也会发生在程序强制将新数据写回的时候。
三、CCS Cache分析工具
1、CCS Cache分析工具简介
TI的Cache分析工具旨在确认Cache效率问题出现的区间,并使之可视化,来促进Cache性能的改善。该工具与模拟平台有关。C55x Cache模拟器,C6713以及C6416设备模拟器使用其可视化工具可以产生轨迹文件。
2、在开发周期中使用工具
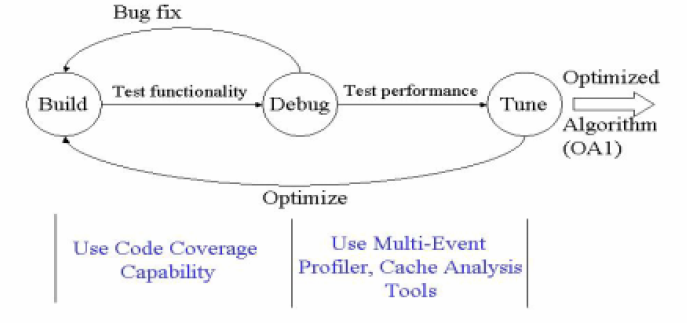
该工具在开发中通过下面两种方式来对内存管理,从而达到提高Cache效率的目的。
a、通过确定的内存地址上下文来展示性能分析。
b、在算法整合后,对检测的处理器和主存显示其性能分析。
二者的关系可用下图表示。
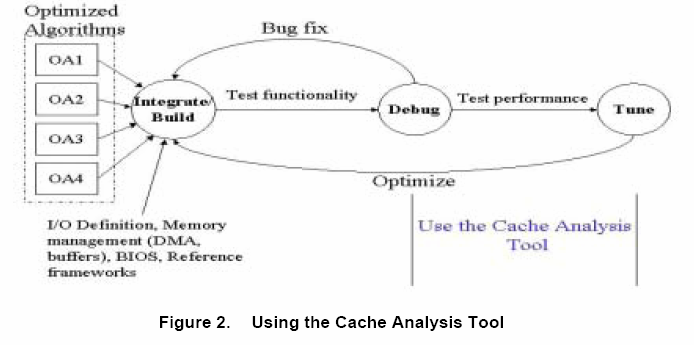
在具体的系统开发周期中,该工具的应用主要有如下三个步骤:
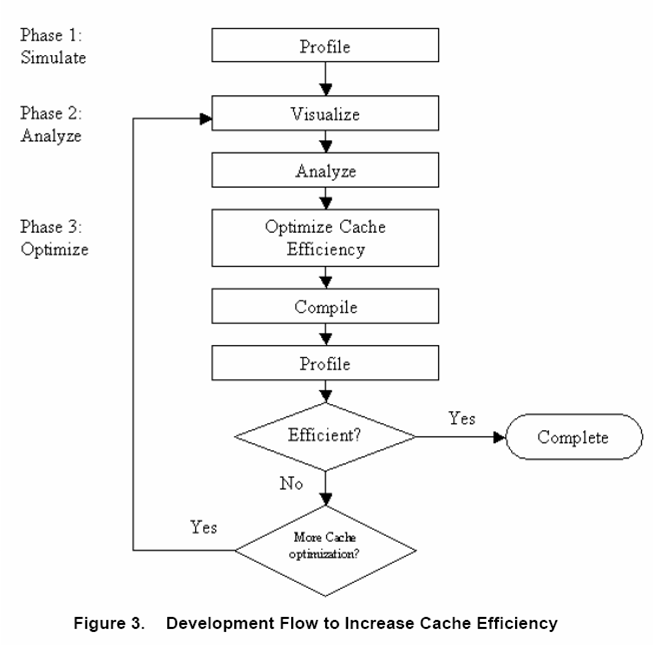
a、在功能化模拟器中产生轨迹文件,使用 Cache分析工具报告Cache事件发生率。为进一步分析代码行为,到阶段b;
b、将上述Cache分析工具的可视化结果进行分析,确认程序和数据发生缺失的区间。进一步改善Cache性能,到阶段c;
c、应用优化技术和转换来改善Cache性能,使用模拟器分析工具检查改善结果。如果算法还不能达到预期效果,重复b、c直到满意。
这个过程可以参看如下图示。
四、实例
1、例子简介
我们使用一个例子来简单介绍Cache工具的使用方法,其效果也是可以看到的。
该例子是对矩阵进行的一系列操作。对于Cache的分析,使用矩阵是最恰当不过的了。
首先我们通过代码的分析来理解该程序的作用。


2、优化过程
通过上述代码的分析,我们知道,在主调函数中,要按列取矩阵B。而在主存中,矩阵的存储是按行优先。这样按行存储的矩阵B将被按行安放在Cache中,而接下来的就是面临着其列数据到来的重配置。当矩阵的维数变大时,这种情况就越发变得明显。也就是引起了矩阵B的很多Cache缺失。
在实验中,我们使用C6455 Simulator (with VCP & TCP), Little Endian来测试。首先在CCS中建立包含如上程序的工程,编译下载程序后,点击Tools->Simulator Analysis,在弹出窗口中右击,选择Analysis setup就可以对感兴趣的内容进行设置了。
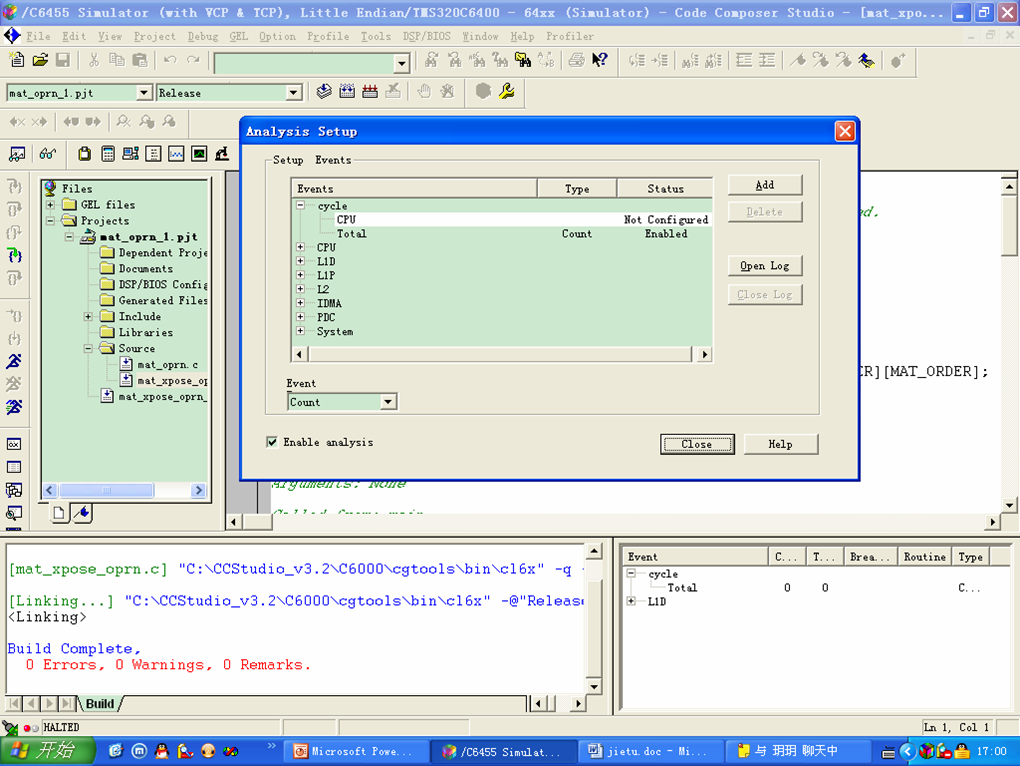
关闭后运行程序,可得到未优化时候的相关内容了。

我们可以通过如下方法得到图形表示。首先在Profile->Setup,在弹出窗口点击一个使之Enable的图标,在Activeties中选择Collect Cache Information Overtime。之后运行程序。结束后,运行结束后,在profile->Tuning->CacheTune,就可以看到图形窗口。
在Setup中还有一些可以选择的项目,可以分析我们所感兴趣的其他方面情况。如函数执行的情况等等。

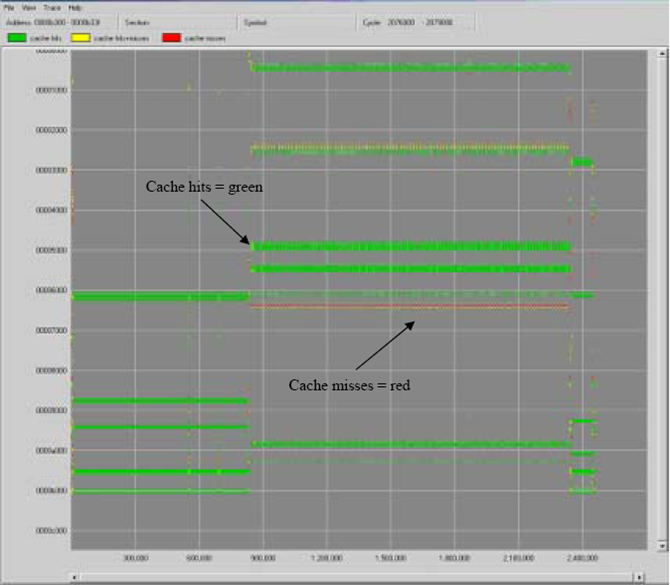
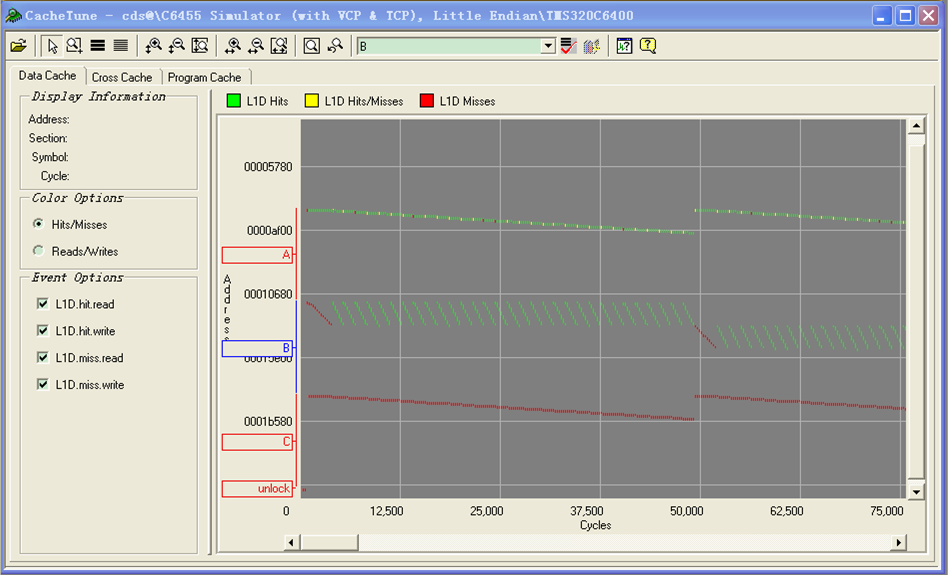
图形的情况。
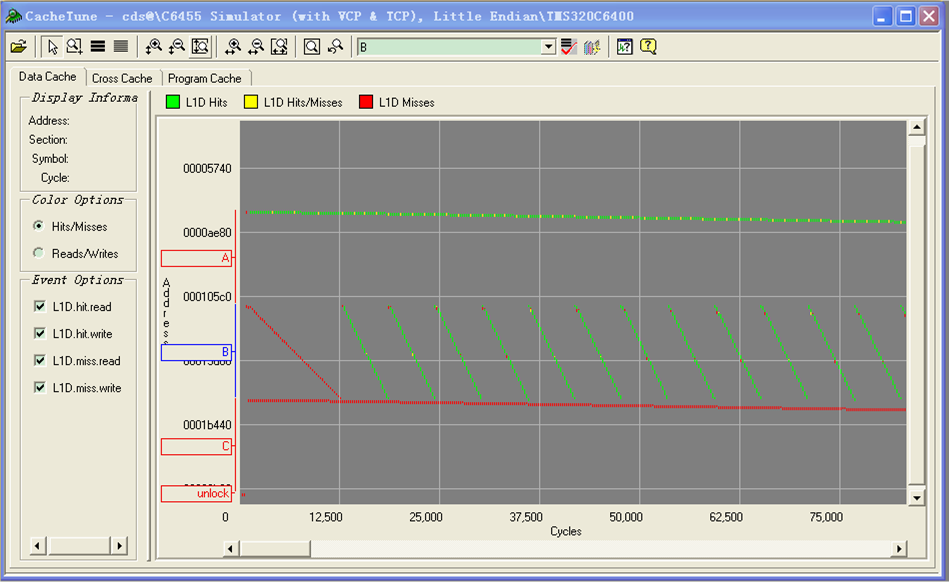
我们针对这种情况进行优化。
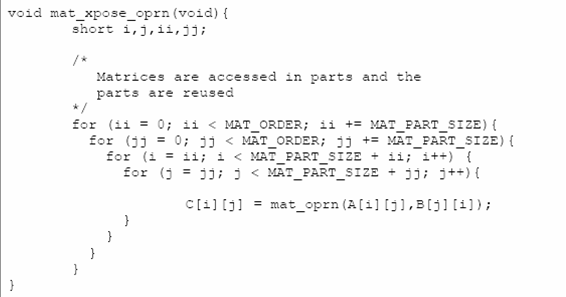
矩阵B按块取数据,Cache中出现的也是可再生的块,在总缺失数上得到了减少。
下图是优化后的结果。
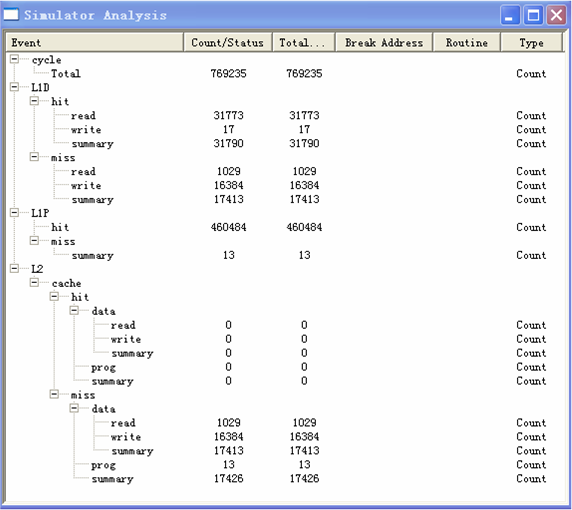
同样的,我们可以得到图形的表示。

五、总结
优化是一个计算机学科经久不衰的话题,对于DSP系统的优化更是我们开发一个数字信号处理系统必不可少的一步。算法的对与错只有在理论才有意义,而作为实时系统的工程开发,优化肯定占据了项目的很大部分。
在DSP系统开发的优化中,可以有很多级别的优化方式,算法的优化,汇编优化(线性汇编)等等。而实时系统的Cache利用也是优化的一个渠道。
该报告通过一个简单的工程,了解了Cache分析的方法。实际的Cache效率提高远不止这样简单。希望能给其他爱好者以启发,共同学习,共同提高。