参考:http://www.cnblogs.com/powertoolsteam/archive/2010/09/20/1831638.html
问题:由于utf8编码分为有bom头和无bom头,而有bom头的编码很好判断,如果前三个字节是0xE 0xBB 0xBF,那么就是utf8带bom的编码,如果没有bom头,则不能好快的判断到底是utf8还是ansi编码,因为他们都没有头,且全英文的编码是兼容的,者就是问题所在。
解决方案:
几天前偶尔看到有人发帖子问“如何自动识别判断url中的中文参数是GB2312还是Utf-8编码”
也拜读了wcwtitxu使用巨牛的正则表达式检测UTF8编码的算法。
使用无数或条件的正则表达式用起来却是性能不高。
刚好曾经在项目中有类似的需求,这里把处理思路和整理后的源代码贴出来供大家参考
先聊聊原理:
UTF8的编码规则如下表
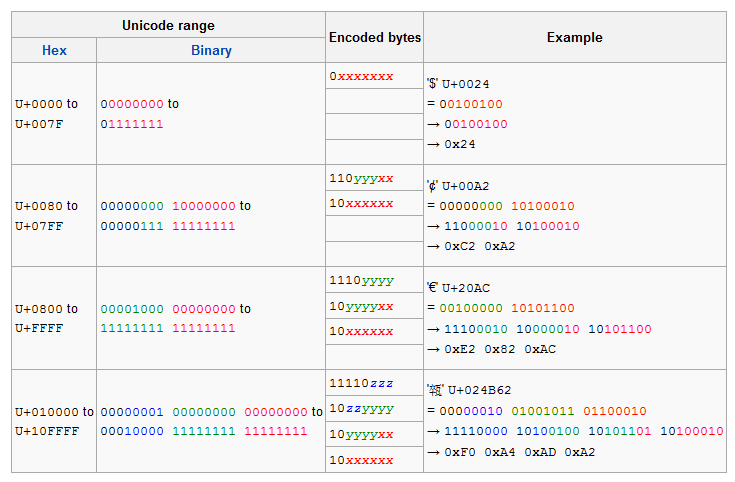
看起来很复杂,总结起来如下:
ASCII码(U+0000 - U+007F),不编码
其余编码规则为
•第一个Byte二进制以形式为n个1紧跟个0 (n >= 2), 0后面的位数用来存储真正的字符编码,n的个数说明了这个多Byte字节组字节数(包括第一个Byte)
•结下来会有n个以10开头的Byte,后6个bit存储真正的字符编码。
因此对整个编码byte流进行分析可以得出是否是UTF8编码的判断。
根据这个规则,我给出的C#代码如下:
////// ///////// /// ////// ///////// ///public static bool IsTextUTF8(ref byte[]{ int encodingBytesCount bool allTextsAreASCIICharstrue; for (int i { byte current if ((current { allTextsAreASCIICharsfalse; } // if (encodingBytesCount { if ((current { // continue; } if ((current { encodingBytesCount current // // while ((current { current encodingBytesCount++; } } else { // return false; } } else { // if ((current { encodingBytesCount--; } else { // return false; } } } if (encodingBytesCount { // // return false; } // return !allTextsAreASCIIChars;} |
再附上单元测试代码:
//////This///to///</summary>[TestClass()]public class EncodingHelperTest{ /// /// ///</summary> [TestMethod()] public void IsTextUTF8Test() { for (int i { List<Char>new List<char>(); chars.Add('中'); List<UnicodeCategory>new List<UnicodeCategory>(); Randomnew Random((int)(DateTime.Now.Ticks for (int j { char chchar)rd.Next(0xFFFF); UnicodeCategory if (uc// uc// uc ) { j--; } else { chars.Add(ch); temp.Add(uc); } } string strnew string(chars.ToArray()); byte[] bool expectedtrue; bool actual; actualref inputStream); Assert.AreEqual(expected,string.Format("UTF8_Assert, inputStream expectedfalse; actualref inputStream); Assert.AreEqual(expected,string.Format("ShiftJIS_Assert, } } /// /// /// [TestMethod] public void IsTextUTF8Test_AllASCII() { string str"ABCDEFGHKLHSJKLDFHJKLHAJKLSHJKLHAJKLSHDJKLAHSDJKLHAJKLSDHJKLASHDJKLHASJKLDHJKLASD"; byte[] bool expectedfalse; bool actual; actualref inputStream); Assert.AreEqual(expected,string.Format("UTF8_Assert, }} |
另:
如果是判断一个文件是否使用了UTF8编码,不一定非用这种方法,因为通常以UTF8格式保存的文件最初两个字符是BOM头,标示该文件使用了UTF8编码。
参考: