一、Servlet输出乱码
1. 用servlet.getOutStream字节流输出中文,假设要输出的是String str ="ooxx是中国的,无耻才是日本的"。
1.1 若是本地服务器与本地客户端这种就不用说了,直接可以out.write(str.getBytes())可以输出没有问题。因为服务器中用str.getBytes()是采用默认本地的编码,比如GBK。而浏览器也解析时也用本地默认编码,两者是统一的,所以没有问题。
1.1 若服务器输出时用了, out.write(str.getBytes("utf-8"))。而本地默认编码是GBK时(比例在中国),那么用浏览器打开时就会乱码。因为服务器发送过来的是utf-8的1010数据,而客户端浏览器用了gbk来解码,两者编码不统一,肯定是乱码。当然,你也可以自己将客户端浏览器的编码手工调用下(IE菜单是:查询View->编码encoding->utf-8),但是这种操作很烂,最好由服务器输出响应头告诉,浏览器用哪种编码来解码。所以要在服务器的servlet中,增加response.setHeader("content-type","text/html;charset=utf-8"),当然也可直接用简单的response.setContentType("text/hmtl;charset=utf-8")。两种的操作是一样一样的。
2. 用servlet.getWirter字符流输出中文,假设要输出的是String str ="ooxx是中国的,无耻才是日本的"。
2.1 若写成out.print(str)输出时,客户端浏览器显示的将全是多个?????的字符,代表在编码表中肯定就找不到相应的字符来显示。原因是:servlet.getWriter()得到的字符输出流,默认对字符的输出是采用ISO-8859-1,而ISO-8859-1肯定是不支持中文的。所以肯定要首先要做的第一件事:是要将服务器对象输出字符能支持中文的。其次服务器向客户端写回的响应头要告诉客户端是用了哪种编码表进行编码的。而实现这两个需求,只需要response.setContentType("text/hmtl;charset=utf-8")。就搞定了。特别注意:response.setContentType("text/html;charset=utf-8")要放在PrintOut
out = response.getWriter()代码的前面,否则只是有告诉客户端用什么码表编码的功能,而服务器端还是用ISO-8859-1编码了。再特别提示下:在同一Servlet中的doGet或doPost方法中,不能既用response.getOutputStream又用response.getWriter,因为这两种response的响应输出字节流与字符流是冲突的,只能用其一。
二、Servlet文件下载,中文乱码情况。
关键是下载时响应头 content-disposition中attachment;filename=文件名。这个文件名filename不能是含有中文字符串的,要用URLEncoding编码进行编码,才能进行进行http的传输。如下代码示例:
- //获取文件的URL地址
- String realPath = getServletContext().getRealPath("/ooxx是中国的无耻才是日本的历史证据.jpg");
- //获取文件名: ooxx是中国的无耻才是日本的历史证据.jpg
- String fileName = realPath.substring(realPath.lastIndexOf("\\")+1);
- //指示响应流的类型不是text/html而是二进制流数据以指示下载
- response.setContentType("application/octet-stream");
- //注意这里一般都用URLEncoder的encode方法进行对文件名进行编码
- String enFileName = URLEncoder.encode(fileName, "utf-8");
- //enFileName文件名若含有中文必须用URLEncoding进行编码
- response.setHeader("content-disposition", "attachment;filename="+enFileName);
- //文件读取与输出,模板代码了...
- InputStream in = new FileInputStream(realPath);
- OutputStream out = response.getOutputStream();
- int len = -1;
- byte[] buf = new byte[1024];
- while((len=in.read(buf))!=-1){
- out.write(buf, 0, len);
- }
- in.close();
三、Servlet的response增加addCookie,cookie中value的中文码问题解决方法。
关于cookie的原理,见http://blog.csdn.net/chenshufei2/article/details/8009992。
若想将cookie中存放中文的值,必须用Base64编码后,发给客户浏览器端进入存储。而下次客户端浏览访问是带回来的cookie中的值,是经过Base64编码的,所以需要用Base64解码即可。 Base64编码主要是解决将特殊字符进行重新编码,编码成a-b、A-B、0-9、+与/,字符52,10个数字与一个+,一个/ 共64个字符。它的原理是将原来3个字节的内容编码成4个字节。主要是取字节的6位后,在前面补00组成一个新的字节。所以这样原来的3个字节共24,被编码成4个字节32位了。
具体代码示例如下:
- response.setContentType("text/html;charset=utf-8");
- request.setCharacterEncoding("utf-8");
- String getUserName = request.getParameter("username");
- PrintWriter out = response.getWriter();
- String username = null;
- //获取客户端提交过来的cookie数组。
- Cookie[] cookies = request.getCookies();
- for (int i = 0; cookies != null && i < cookies.length; i++) {
- //遍历cookie数组,找到含有username的key的cookie。
- if (Constant.USER_INFO.equals(cookies[i].getName())) {
- username = cookies[i].getValue();
- //得到cookie的值后必须,进行Base64解码,因为前次生成cookie时,value是经过Base64编码。
- username = Base64Coder.decode(username); //进行Base64解码
- }
- }
- out.print(username + ",恭喜您登录成功......"+getUserName); //username从Cookie中得出来,getUserName从请求参数中
- System.out.println(username+"------------");
- String remember = request.getParameter("remember");
- //中文必须要进行 base64进行加码,才能作为cookie的值
- getUserName = Base64Coder.encode(getUserName);
- //将编码后的中文username的作为cookie的value
- Cookie cookie = new Cookie(Constant.USER_INFO, getUserName);
- cookie.setPath(getServletContext().getContextPath());
- if(null != remember){ //若选择中了,则将Cookie写进去,若没有选择中,则将以前的Cookie都置成空
- cookie.setMaxAge(Integer.MAX_VALUE); //设置Cookie是Integer最大数,好似有70多年的存效吧。呵呵
- }else{
- cookie.setMaxAge(0); //设置成cookie马上失效,maxAge是cookie的存活时间
- }
- response.addCookie(cookie);
四、获取请求参数乱码
GET方式的乱码:
如<a href=”/demo5/servlet/RD2?name=中国”>CN</a>,直接用request.getParameter得到的字符串strCN将会乱码,这也是因为GET方式是用http的url传过来的默认用iso-8859-1编码的,所以首先得到的strCn要再用iso-8859-1编码得到原文后,再进行用utf-8(看具体页面的charset是什么utf-8或gbk)进行解码即可。new String(strCn.getBytes(“ISO-8859-1”),“UTF-8”);
- String strCn = request.getParameter("name");
- String name = new String(strCn.getBytes(“ISO-8859-1”),“UTF-8”);
这种方式操作比较麻烦的是,有一个参数要用iso-8859-1编码一次再解码一次。
POST方式的乱码:只需要request.setCharacterEncoding("UTF-8"):即可。
- request.setCharacterEncoding("UTF-8");
- String name = request.getParameter("name");
推荐阅读:深度剖析Java的字符编码
http://geeklu.com/2009/12/dive-into-the-charset-of-java/
Java中的String在JVM运行时都是Unicode编码的
字符集
在计算机的世界里,我们需要表示太多太多的字符,为了计算机能够正确的显示这些字符,我们将这些字符编码,使得字符和一系列的代号一一对应。当我们的系统按照一种编码方式去读取一个文件的时候,会自动的将里面的编码转换成相应的字符显示在屏幕上。(我们这里并不讨论如何将字符在显示器上通过点阵的方式显示的这个过程) 中文由于其字符数多,其编码方式自然比西方的字符复杂。所以在编写代码,软件使用的过程中,我们经常碰到中文乱码的相关问题。
g.cn的首页是UTF-8的编码(浏览器会首先根据接受到的html自动检测其编码),这个时候如果我们强行以GB2312的编码来解析页面的话就会显示如上的乱码。 这是为什么呢??? 首先我们请求一个网址,服务器返回的内容是以指定字符集编码的字节传到浏览器端的,浏览器再按照一定的编码方式去解析这些字节。但是如果传来的正确的字节的编码方式和你解析字节的编码方式不一致,那么就会乱码。
下面我们先介绍几种日常使用中经常碰到的编码。
在我们的日常使用中,我们会碰到iso 8859-1,gb2312,gbk,gb18030,big5,unicode等字符集或者说字符编码,这些都是同一个层次的概念,有些同学可能会问,那UTF-8,UTF-16呢?其实unicode是比较特殊的,虽然通过unicode编码,每一个字符对应一个唯一编码,但是其在计算机上的实现方式却可以有好几种,Unicode的实现方式称为Unicode转换格式(Unicode
Translation Format,简称为UTF),所以说UTF-8或者UTF-16只是Unicode编码的一种实现方式。下面我们单独对几个编码进行讲解下:
- ISO 8859-1 正式编号为ISO/IEC 8859-1:1998,又称Latin-1或“西欧语言”,是国际标准化组织内ISO/IEC 8859的第一个8位字符集。它以ASCII为基础,在空置的0xA0-0xFF的范围内,加入96个字母及符号,藉以供使用附加符号的拉丁字母语言使用。曾推出过 ISO 8859-1:1987 版。ISO-8859-1是单字节编码。
- GBK(国标扩展) 全名为汉字内码扩展规范,英文名Chinese Internal Code Specification。K 即是“扩展”所对应的汉语拼音(KuoZhan11)中“扩”字的声母。GBK是对GB2312的扩展,这样GBK在支持简体中文的同时也支持繁体中文。现时中华人民共和国官方强制使用GB18030标准.
- Unicode 再来说说Unicode吧,在java或者javascript中我们构造一个“中文”的unicode串的时候一般是使用”\u4E2D\u6587”来表示,占两个字节。UTF-8则是可变长字符编码,比如一般的英文字符只需要一个字节,而中文则每个字符占用三个字节。而UTF-16两个字节为一个编码单元(固定的),所以从字节的角度来看无法和ASCII实现兼容,且UTF-16存在大尾序和小尾序的两种不同的存储形式。
字符编码贯穿java代码编译运行的始终
下面是我们需要考虑的问题:
- 源文件的编码
- 编译时的指定的编码参数(Eclipse会根据你源文件的编码格式自动选用相应的编译编码参数)
- 系统的默认编码(可以通过System.getProperty(“file.encoding”)来获取)
- 控制台终端显示所设置的编码
- 运行时JVM中的String都是Unicode编码
首先我们通过一个简单的java代码的编译运行来说明编码在这个过程中的使用
1 |
package com.lukejin.stringtest; |
2 |
import java.io.UnsupportedEncodingException; |
3 |
4 |
public class StringTest |
5 |
public static void main(String[]args) throws UnsupportedEncodingException{ |
6 |
String"ab中文"; |
7 |
System.out.println(chinese); |
8 |
} |
9 |
} |
这个代码看起来非常简单。 假设源文件的编码格式是GBK,那么当你通过相关可以查看二进制格式的软件查看的时候你可以发现如下编码 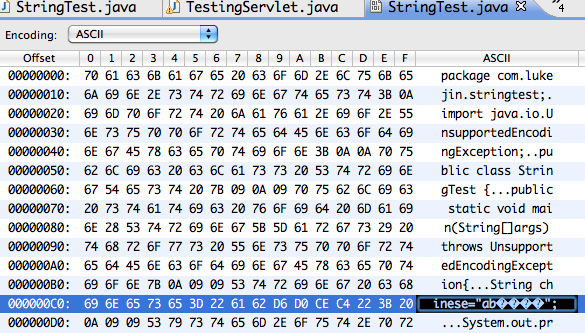
这时我们可以知道”中文”的GBK编码为 D6 D0 CE C4(GBK编码一个中文占两个字节)
在使用Eclipse编译之后(eclipse编译时帮你自动添加了编译参数 -encoding gbk),你可以通过二进制编辑器打开编译后的class 
这是编译之后的”中文”已经被转换成UTF-8的编码了三个字节表示一个中文字符。 E4 B8 AD E6 96 87
那么在JVM中运行的时候是怎么一种情形呢? 首先chinese是一个正确的”ab中国”的Unicode字符串, System.out.println(chinese); 这句会将chinese按照系统默认的编码encode成字节流送到输出流里, 然后终端里会对输出的流里的字节按照终端的编码进行decode得到字符
和编码有关的两个方法
关于String的编码有两个比较重要的方法需要提及
getBytes(String charset)
new String(byte[] bytes,String charset)
这两个方法都是相对于String而言,即相对于Unicode字符串而言。 这里我们就来详细讲解下这两个函数的功能, GetBytes是将字符串中的一个个字符char按照charset对应的编号进行编码,得到的是编码后的字节数组,这是一个encode的过程, 而new String(byte[] bytes,String charset) 是将byte数组按照charset去解码,将解出来的一个个字符用unicode字符存储,并返回这个unicode字符串。
下面以实例和图的方式展示上面的过程
假设String a=”中文”;//当然你可以以unicode的形式写成String a=”\u4E2D\u6587″; Byte[] bs = A.getBytes(“gbk”)

String b= new String(bs,”iso-8859-1″);//如果这里使用gbk编码进行解码的话,会自然的得到原来的a

可以看出这个时候已经为乱码了,不过由于没有信息丢失,所以还是可以恢复成中文的。 恢复的过程为 String c = new String(b.getBytes(“iso-8859-1″),”gbk”); 这个过程可以参考上面的两个图进行思考。 首先b按照iso-8859-1进行编码得到”D6D0 CEC4” ”D6D0 CEC4”按照GBK进行解码得到字符串”中文” “中文” 分别使用unicode进行表示(由于java中String都是unicode),所以b为”中文”(”\u4E2D\u6587″)
Web编程中常见的编码问题
那为什么我们需要在java中进行所谓的转码呢? 关键原因就是我们构造字符串的时候使用了错误的字符集。 比如前台传过来的是gbk编码的字节流bytes,但是服务器端却错误的以iso-8859-1的字符集解码成字符。 这个过程相当于 new String(bytes,”iso-8859-1”); 当然很多时候这个过程不是由我们来写的,而是由servlet框架来完成,当然你可以改变这个字符集的值。
我们Servlet后台发送响应给前台,这里会有一个编码的概念,就是你输出的内容的编码,以及设置的让接受端浏览器以什么样的编码来解码。 比如我们可以在通过在response.getWriter();之前使用
response.setContentType(“text/html; charset=utf8″);
这样的语句来设置输出的编码,其实这个语句起两个作用,
第一,设置了输出内容的编码方式 比如我们有一个a这个字符串,那么将它发送到浏览器的时候肯定都是字节流,那些字节是这样的a.getBytes(你上面这个设置的编码) 第二,发送给浏览器的response的报头中的编码设置成这个编码,使得浏览器可以以正确的编码去解码字节数组。
当然Servlet 2.4版本以后,提供了setCharacterEncoding这个一个单独的方法可以单独设置编码的。这个你可以通过阅读相关web容器的源码得知。 这两个方法都必须在 response.getWriter();之前作用才起作用,且响应的字节流编码字符集和response的header的contentType的charset是一致的。
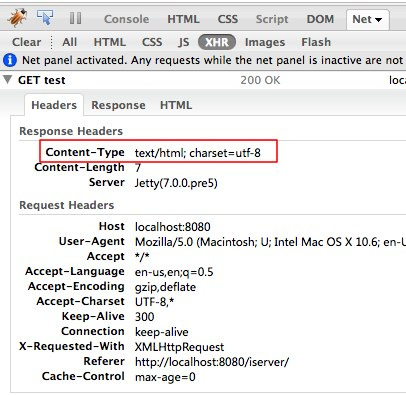
这里举一个我碰到的问题: 后台有一个Servlet是前台的一个JQuery的ajax调用的,返回一个包含中文的字符串,由于历史原因,得到字符串是以iso-8859-1解码的得到String a.且系统的默认编码是iso-8859-1编码的,如果我们将这个a直接在控制台上print出来,却发现能够正确的输出中文,(心想:奇怪了,不应该出现中文?)其实原理是这样的,输出到控制台经过如下两个步骤, 首先1.将错误的String按照iso-8859-1进行编码成bytes,这个bytes和正确的gbk编码的bytes是一致的,这个时候我们的SecureCRT设置的编码是GBK,所以能够正确的显示中文,也就是我们以GBK的方式去解码一个iso8859-1的编码,歪打正着,中文反而能显示了。
现在回到Web上来思考,由于response写出的字节编码和浏览器解析的编码是一致的(如果不一致,我们可以模拟控制台的方式) 所以我们必须先做一个转换 String b = new String(a.getBytes(“iso-8859-1″),”gbk”) 这样,b中的字符串就是正确的字符串, 这个时候我们只要以支持中文的编码送到客户端的浏览器就可以了
response.setContentType(“text/html;charset=utf-8″); out = response.getWriter(); out.write(str);
很多时候,一些同学烦扰乱码还和javascript相关,这个主要的原因是,其实在js的运行时的内部,String也是以Unicode进行编码的,(或者准确的说时utf-16)。 所以在进行ajax的使用的过程中,同学们容易遇到一些乱码问题的困扰。需要注意的是服务器端返回给ajax的字节只要保证是正确的编码就可以了。(比如中文的话,只要保证是相应中文的正确的gbk,utf-8等编码)
乱码的总结
在Java运行时的世界里,乱码产生(编译时产生的这里不管)的源头存在于两个地方,其实也就是我上面提及的两个函数(当然有时候是框架帮我们调用了其中的某个函数,所以你得到的已经是一个由网络上传过来的字节数组转换后的String了),
getBytes(String charset) 如果按照指定的charset去对一个unicode String进行编码,但是发现这个编码体系里(比如iso-8859-1)没有这个字符,那么就会编码成3F(其实就是一个问号),这样就造成了信息的丢失了,是不可以恢复的。 new String(byte[] bytes,String charset) 如果对一个字节数组按照指定的字符集去解码,但是字符集突然对其中一段编码不认识的时候,例如某一段字节数组按照UTF-8解码的时候,不认识了,到了unicode字符串这边就是”\uFFFD”,其实这个东西叫做’REPLACEMENT
CHARACTER’,显示的是一个问号
具体可以查看 Unicode Character ‘REPLACEMENT CHARACTER’ (U+FFFD) 所以这个地方也肯定发生了信息的丢失,无法恢复的。如果大家想不明白的可以直接按照上面的图类似的想法。 所以我们碰到的乱码往往是下面的情况
- 一种编码的文件以另一种编码的方式去解析读取,这样肯定出现乱码,这在我们的操作系统里打开文件的时候经常出现。
- 以错误的编码方式对传过来的字节流进行了解码。所以得到了错误的unicode字符串。
- 以和控制台不一致的编码对正确的unicode字符串进行编码,并送至控制台显示。会出现乱码