1.下列哪一种叙述是正确的()
A. abstract修饰符可修饰字段、方法和类
B.抽象方法的body部分必须用一对大括号{ }包住
C.声明抽象方法,大括号可有可无
D.声明抽象方法不可写出大括号
答案:D
abstract不能修饰字段,抽象方法不用实现,不能用{}.
2.指出正确的表达式 C
A byte=128;
B Boolean=null;
C long l=0xfffL;
D double=0.9239d;
3.public class Person{ C
static int arr[] = new int[5];
public static void main(String a[]) {
System.out.println(arr[0]); }
}
A、编译时将产生错误 B、编译时正确,运行时将产生错误 C、输出零 D、输出空
4.不能用来修饰interface的有:()A C D
A.private B.public C.protected D.static
JSP共有以下9种基本内置组件
1、request对象 客户端请求,此请求会包含来自GET/POST请求的参数通过它才能了 解到客户的需求,然后做出响应。
2、response对象 响应客户请求的有关信息
3、session对象 它指的是客户端与服务器的一次会话,从客户端连到服务器的一个 WebApplication开始,直到客户端与服务 器断开连接为止。
4、out对象 它是JspWriter类的实例,是向客户端输出内容常用的对象
5、page对象 它是指向当前JSP页面本身,有点象类中的this指针,它是 java.lang.Object类的实例
6、application对象 它实现了用户间数据的共享,可存放全局变量。它开始于服务器的启动,直到服务器的关闭
7、exception对象 它是一个例外对象,当一个页面在运行过程中发生了例外,就产生这个对象。
8、pageContext对象 它提供了对JSP页面内所有的对象及名字空间的访问
9、config对象 它是在一个Servlet初始化时,JSP引擎向它传递信息用的
6.jsp有哪些动作?作用分别是什么?
答:JSP共有以下6种基本动作
jsp:include:在页面被请求的时候引入一个文件。
jsp:useBean:寻找或者实例化一个JavaBean。
jsp:setProperty:设置JavaBean的属性。
jsp:getProperty:输出某个JavaBean的属性。
jsp:forward:把请求转到一个新的页面。
jsp:plugin:根据浏览器类型为Java插件生成OBJECT或EMBED标记
7.post与get的区别?
1.post传输数据时,不在URL中显示出来,而get方法要在URL中显示
2.post传输数据量大,而get传输数据小
3.post向服务器传数据,get从服务器取数据
4.post方式要比get方式安全
8.函数cast(2.5 as int)/2 的执行结果是:1.5
9.FLOOR——对给定的数字取整数位
SQL> select floor(2345.67) from dual;
FLOOR(2345.67)
--------------
2345
CEIL-- 返回大于或等于给出数字的最小整数
SQL> select ceil(3.1415927) from dual;
CEIL(3.1415927)
---------------
4
ROUND——按照指定的精度进行四舍五入
SQL> select round(3.1415926,4) from dual;
ROUND(3.1415926,4)
------------------
3.1416
TRUNC——按照指定的精度进行截取一个数
SQL> select trunc(3.1415926,4) from dual;
ROUND(3.1415926,4)
------------------
3.1415
10.在oracle的聚合函数中,合计函数、最大值函数、最小值函数、平均值函数分别是 count 、max、min、avg
11.数据库系统的核心是 数据库管理系统
12.
| 构造方法 | 普通成员变量 | 普通方法 | 静态方法 | 变量访问类型 | |
| 抽象类 | 可以 | 可以 | 可以 | 可以 | 任意 |
| 接口 | 不可以 | 不可以 | 不可以 | 不可以 | 只能为 public static |
1.但接口中的抽象方法只能是public类型的,并且默认即为public
abstract类型
2.接口中定义的变量只能是public
static类型,并且默认为public static类型
3. 接口更多的是在系统框架设计方法发挥作用,主要定义模块之间的通信,而抽象类在代码实现方面发挥作用,可以实现代码的重用
13.&与&&的区别
&按位与 &&逻辑与
&两边都要判断
&&只要前面是false就输出false,而不继续判断后面
14.error和exception有什么区别?
error:系统级错误或程序不必处理的异常,比如:内存资源不足 这种错误无能为力
exception:需要捕捉或需要程序处理的异常,因为程序设计瑕疵或外部输入引起的异常,程序必须处理
exception 分为: 运行时异常:因为错误的操作引起的
受检查异常:程序可以自我的处理
15.JavaScript标准中规定了6种类型:Undefined,Null,Boolean,String,Number,Object
16.String,StringBuffer,StringBuilder区别:
执行速度:Stringbuilder->StringBuffer->String
String:不可改变
Stringbuffer和StringBuilder可以改变
StringBuffer单线程
线程安全 可以实现同步 StringBuilder多线程 线程不安全
17.WebService是一种跨编程语言和跨操作系统平台的远程调用技术。
18.B/S
与C/S的联系与区别?
C/S
Client/Server 局域网内高性能的数据库交互,安装专用客户端软件。
B/S
Browser/Server 浏览器与数据库进行交互。
20.IOC和AOP的概念以及在spring中是如何应用的
IOC
控制反转 容器通过配置文件注入就是IOC的思想。 利用反射机制实例化类
AOP
面向切面编程 在不修改代码的情况下,给程序动态同意添加的一种技术。 利用动态代理机制
21.简述RBAC(Role-Based Access Control)
基于角色的访问控制(Role-Based Access Control)作为传统访问控制(自主访问,强制访问)的有前景的代替受到广泛的关注。在RBAC中,权限与角色相关联,用户通过成为适当角色的成员而得到这些角色的权限。
22.解决hibernate 1+n 问题?
1.延迟加载 2.默认fetch=“select” 把fetch设置成“join” 但失去了延迟加载的特性
Hibernate的两个类设置了manyToOne(oneToMany)之后,在查询的时候,由于N 对1的一方默认的fetch=FetchType.EAGER,所以会把被关联
的对象一起取出来
解决方法一:设置fetch=FetchType.LAZY,这种方法在合适的时候(具体使用到对象时)还是会发出select语句。
解决方法二:
//List<Student> students= (List<Student>)session.createCriteria(Student.class).list();
List<Student> students= (List<Student>)session.createQuery("from Student").list();
也就是用session.createCriteria()做查询,而不是用createQuery。
解决方法三:使用BatchSize(size=5)方法,他会发出1+N/5条select语句。
解决方法四:使用join fetch做外连接查询。from Topic t left join fetch t.category c
23.写一个单例模式的类出来:
public class Singleton {
private static Singleton instance = null;
public static synchronized Singleton getInstance() {
//这个方法比上面有所改进,不用每次都进行生成对象,只是第一次
//使用时生成实例,提高了效率!
if (instance==null)
instance=new Singleton();
return instance; }
}
24.写出冒泡排序:
冒泡排序法:关键字较小的记录好比气泡逐趟上浮,关键字较大的记录好比石块下沉,每趟有一块最大的石块沉底。
算法本质:(最大值是关键点,肯定放到最后了,如此循环)每次都从第一位向后滚动比较,使最大值沉底,最小值上升一次,最后一位向前推进(即最后一位刚确定的最大值不再参加比较,比较次数减1)
复杂度: 时间复杂度 O(n2)
,空间复杂度O(1)
/**
* 冒泡排序
*
*/
public class Bubble {
public static void main(String[] args) {
int[] array = { 49, 38, 65, 97, 76, 13, 27 };
buddleSort(array);
for (int i = 0; i < array.length; i++) {
System.out.println(array[i]);
}
}
public static void buddleSort(int[] array) {
int temp;
for (int i = 0; i < array.length; i++) {//趟数
for (int j = 0; j < array.length - i - 1; j++) {//比较次数
if (array[j] > array[j+1]) {
temp = array[j];
array[j] = array[j+1];
array[j+1] = temp;
}
}
}
}
}
25.策略模式:定义了算法族,并分别封装起来,让它们之间可以相互替换。
观察者模式:定义了对象间一对多依赖
26.CI服务器:持续集成服务器
struts2 虽然方法之间也是独立的,但action的变量时共享的,比较混乱
2.拦截器 不依赖于servlet容器 过滤器 依赖servlet容器
3.拦截器 可以被调用多次 过滤器 在容器初始化时只能被调用一次
4.拦截器 只对action请求起作用 过滤器 对所有的请求都起作用
5.拦截器 可以访问action上下文、值栈里的对象 过滤器 不可以
2.BeanWrapper:提供统一的get及set方法
3.ApplicationContext:提供spring框架的实现,包括BeanFactory的所有功能
线程安全就是说多线程访问同一代码,不会产生不确定的结果。编写线程安全的代码是低依靠线程同步。
线程不安全就是不提供数据访问保护,有可能出现多个线程先后更改数据造成所得到的数据是脏数据
38.hashmap为什么线程不安全
当然了如果只是读,没有写肯定没有并发的问题了。改换Hashtable或者ConcurrentHashMap肯定也是没有问题了
addEntry 导致线程不安全
39.hibernate获取数据连接的过程
session.connection();
2、通过ConnectionProvider来获得连接
ConnectionProvider cp = ConnectionProviderFactory.newConnectionProvider (cfg.getProperties());
cp.getConnection();
ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。 2. 对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。 3. 对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据
3.运行状态(Running)4. 阻塞状态(Blocked)
5. 死亡状态(Dead)
text的区别是什么?
normal:表示普通索引
unique:表示唯一的,不允许重复的索引,如果该字段信息保证不会重复例如身份证号用作索引时,可设置为unique
full textl: 表示 全文搜索的索引。 FULLTEXT 用于搜索很长一篇文章的时候,效果最好。用在比较短的文本,如果就一两行字的,普通的 INDEX 也可以。
总结,索引的类别由建立索引的字段内容特性来决定,通常normal最常见。
INDEX, UNIQUE 这3种是一类
PRIMARY 主键。 就是 唯一 且 不能为空。
INDEX 索引,普通的
UNIQUE 唯一索引。 不允许有重复。
FULLTEXT 是全文索引,用于在一篇文章中,检索文本信息的。
2.全注解事务
在windows控制台窗口下执行:
netstat -nao | findstr "9010"
TCP 127.0.0.1:9010 0.0.0.0:0 LISTENING 3017
你看到是PID为3017的进程占用了9010端口,如果进一步你想知道它的进程名称,你可以使用如下命令:
tasklist | findstr "3017"
如果你想杀死这个进程,你当然可以用前面描述的那种方法,在任务管理器里把它KILL了,但如果你喜欢高效一点,那么用taskkill命令就可以了。
taskkill /pid 3017
2、Linux
netstat -pan | grep 9010
2)分区速度的提升类似建了索引,所以如果需要分区的字段已经建了索引,一般没有必要在做分区;
3)mysql的表分区还有一个重要的功能就是可以将表的各分区放到不同的磁盘上,以增加表容量;
4)range分区比hash分区的查询性能高;
6) 视图负责将结果显示到客户端
2)Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储。
3)虚拟内存--Redis当物理内存用完时,可以将一些很久没用到的value 交换到磁盘
4)过期策略--memcache在set时就指定,例如set key1 0 0 8,即永不过期。Redis可以通过例如expire 设定,例如expire name 10
5)分布式--设定memcache集群,利用magent做一主多从;redis可以做一主多从。都可以一主一从
6)存储数据安全--memcache挂掉后,数据没了;redis可以定期保存到磁盘(持久化)
7)灾难恢复--memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复
8)Redis支持数据的备份,即master-slave模式的数据备份。
2)如果两个对象相同,就是适用于equals(java.lang.Object) 方法,那么这两个对象的hashCode一定要相同;
3)如果对象的equals方法被重写,那么对象的hashCode也尽量重写,并且产生hashCode使用的对象,一定要和equals方法中使用的一致,否则 就会违反上面提到的第2点;
4)两个对象的hashCode相同,并不一定表示两个对象就相同,也就是不一定适用于equals(java.lang.Object) 方法,只能够说明这两个对象在散 列存储结构中,如Hashtable,他们“存放在同一个篮子里”。
内部最核心的就是IOC了,动态注入,让一个对象的创建不用new了,可以自动的生产,这其实就是利用java里的反射,反射其实就是在运行时动态的去创建、调用对象,Spring就是在运行时,跟xml Spring的配置文件来动态的创建对象,和调用对象里的方法的 。
Spring还有一个核心就是AOP这个就是面向切面编程,可以为某一类对象 进行监督和控制(也就是 在调用这类对象的具体方法的前后去调用你指定的 模块)从而达到对一个模块扩充的功能。这些都是通过 配置类达到的。
Spring目的:就是让对象与对象(模块与模块)之间的关系没有通过代码来关联,都是通过配置类说明管理的(Spring根据这些配置 内部通过反射去动态的组装对象)
要记住:Spring是一个容器,凡是在容器里的对象才会有Spring所提供的这些服务和功能。
Spring里用的最经典的一个设计模式就是:模板方法模式。(这里我都不介绍了,是一个很常用的设计模式), Spring里的配置是很多的,很难都记住,但是Spring里的精华也无非就是以上的两点,把以上两点跟理解了 也就基本上掌握了Spring.
Garbage Collector)
并行垃圾回收器(Parallel Garbage Collector)
并发标记扫描垃圾回收器(CMS Garbage Collector)
G1垃圾回收器(G1 Garbage Collector)
1)HEAD
2)PUT
3)DELETE
4)POST
5)OPTIONS
CREATE :PUT
READ:GET
UPDATE:POST
DELETE:DELETE
d.innerHTML="俄方圣诞歌 IE11考核得分<span style=\"color:#333333;background-color:#FFFFFF;\">";
document.body.appendChild( document.createTextNode( d.innerText||d.textContent ));
//把得到的文本拼接到body //d.textContent是用来适配firefox浏览器的
首先想说说IoC(Inversion of Control,控制倒转)。这是spring的核心,贯穿始终。所谓IoC,对于spring框架来说,就是由spring来负责控制对象的生命周期和对象间的关系。传统的程序开发,在一个对象中,如果要使用另外的对象,就必须得到它(自己new一个,或者从JNDI中查询一个),使用完之后还要将对象销毁(比如Connection等),对象始终会和其他的接口或类藕合起来。
Spring所倡导的开发方式就是如此,所有的类都会在spring容器中登记,告诉spring你是个什么东西,你需要什么东西,然后spring会在系统运行到适当的时候,把你要的东西主动给你,同时也把你交给其他需要你的东西。所有的类的创建、销毁都由 spring来控制,也就是说控制对象生存周期的不再是引用它的对象,而是spring。对于某个具体的对象而言,以前是它控制其他对象,现在是所有对象都被spring控制,所以这叫控制反转。
IoC的一个重点是在系统运行中,动态的向某个对象提供它所需要的其他对象。这一点是通过DI(Dependency Injection,依赖注入)来实现的。比如对象A需要操作数据库,以前我们总是要在A中自己编写代码来获得一个Connection对象,有了 spring我们就只需要告诉spring,A中需要一个Connection,至于这个Connection怎么构造,何时构造,A不需要知道。在系统运行时,spring会在适当的时候制造一个Connection,然后像打针一样,注射到A当中,这样就完成了对各个对象之间关系的控制。A需要依赖
Connection才能正常运行,而这个Connection是由spring注入到A中的,依赖注入的名字就这么来的。那么DI是如何实现的呢? Java 1.3之后一个重要特征是反射(reflection),它允许程序在运行的时候动态的生成对象、执行对象的方法、改变对象的属性,spring就是通过反射来实现注入的。
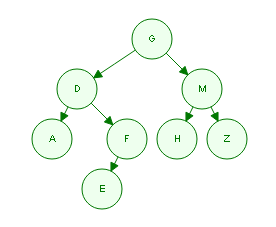
PreOrder: GDAFEMHZ 前序遍历 中左右
InOrder: ADEFGHMZ 中序遍历 左中右
PostOrder: AEFDHZMG 后序遍历 左右中
67.mysql索引的数据结构
二叉树
68.InnoDB和myiasm的区别
在 Innodb 中如果通过主键来访问数据效率是非常高的,而如果是通过 Secondary Index 来访问数据的话, Innodb 首先通过 Secondary Index 的相关信息,通过相应的索引键检索到 Leaf Node之后,需要再通过 Leaf Node 中存放的主键值再通过主键索引来获取相应的数据行。MyISAM 存储引擎的主键索引和非主键索引差别很小,只不过是主键索引的索引键是一个唯一且非空 的键而已。而且 MyISAM 存储引擎的索引和 Innodb 的 Secondary Index 的存储结构也基本相同,主要的区别只是
MyISAM 存储引擎在 Leaf Nodes 上面出了存放索引键信息之外,再存放能直接定位到 MyISAM 数据文件中相应的数据行的信息(如 Row Number ),但并不会存放主键的键值信息
69.mysql优化方案
1)慢查询 :
分析MySQL语句查询性能的方法除了使用 EXPLAIN 输出执行计划,还可以让MySQL记录下查询超过指定时间的语句,我们将超过指定时间的SQL语句查询称为“慢查询”。
2)连接数
3) key_buffer_size
在mysql数据库中,mysql key_buffer_size是对MyISAM表性能影响最大的一个参数(注意该参数对其他类型的表设置无效)
4) 临时表
当工作在十分大的表上运行时,在实际操作中你可能会需要运行很多的相关查询,来获得一个大量数据的小的子集,不是对整个表运行这些查询。而是让MsSQL每次找出所需的少数记录,将记录选择到一个临时表可能更快些,然后对这些表运行查询。
5)open
table情况
Open_tables 当前打开的表数目 302 。table_open_cache 1024 。所有现在没必要对缓存进行调整。
7)进程使用情况
8)查询缓存(query
cache)
9)排序使用情况
10)文件打开数(open_files)
11)表锁情况
12)表扫描情况
70.JVM工作原理和特点
JVM工作原理和特点主要是指操作系统装入JVM是通过jdk中Java.exe来完成,通过下面4步来完成JVM环境.
1)创建JVM装载环境和配置
2)装载JVM.dll
3)初始化JVM.dll并挂界到JNIENV(JNI调用接口)实例
4)调用JNIEnv实例装载并处理class类。
71.spring用到的设计模式
1.工厂模式,这个很明显,在各种BeanFactory以及ApplicationContext创建中都用到了;
2.模版模式,这个也很明显,在各种BeanFactory以及ApplicationContext实现中也都用到了;JdbcTemplate的回调
3.代理模式,在Aop实现中用到了JDK的动态代理;
4.策略模式,第一个地方,加载资源文件的方式,使用了不同的方法,比如:ClassPathResourece,FileSystemResource, ervletContextResource,UrlResource但他们都有共同的借口Resource;
第二个地方就是在Aop的实现中,采用了两种不同的方式,JDK动态代理和CGLIB代理;
5.单例模式,这个比如在创建bean的时候。
72.网站高并发 大流量访问的处理及解决方法
1)使用缓存
2)那么可以尝试优化数据库的查询SQL.避免使用 Select * from这样的语句,每次查询只返回自己需要的结果,避免短时间内的大,尽量做到"所查即所得"
,遵循以小表为主,附表为辅,查询条件先索引,先小后大的原则,提高查询效率.
3)控制大文件的下载 加一个文件服务器
4)使用不同主机分流主要流量
5) 使用流量分析统计软件
73.阻塞I/O存在一些缺点
1)当客户端多时,会创建大量的处理线程。且每个线程都要占用栈空间和一些CPU时间
2) 阻塞可能带来频繁的上下文切换,且大部分上下文切换可能是无意义的。
74.非阻塞式I/O(NIO)
1)由一个专门的线程来处理所有的
IO 事件,并负责分发。
2)事件驱动机制:事件到的时候触发,而不是同步的去监视事件。
3)线程通讯:线程之间通过 wait,notify 等方式通讯。保证每次上下文切换都是有意义的。减少无谓的线程切换。

75.JAVA中复制数组的方法
以下是归纳的JAVA中复制数组的方法:
1)使用FOR循环,将数组的每个元素复制或者复制指定元素,不过效率差一点
2)使用clone方法,得到数组的值,而不是引用,不能复制指定元素,灵活性差一点
3)使用System.arraycopy(src, srcPos, dest, destPos, length)方法,推荐使用
76.Hashmap遍历的两种方式
效率高:
Map map = new HashMap();
Iterator iter = map.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
Object key = entry.getKey();
Object val = entry.getValue();
}
效率低:
Map map = new HashMap();
Iterator iter = map.keySet().iterator();
while (iter.hasNext()) {
Object key = iter.next();
Object val = map.get(key);
}
77.SpringMVC和Struts2 对比


78.TCP三次握手
TCP是因特网中的传输层协议,使用三次握手协议建立连接,下面是TCP建立连接的全过程。

79.socket建立过程
建立Socket连接至少需要一对套接字,其中一个运行于客户端,称为ClientSocket ,另一个运行于服务器端,称为ServerSocket 。
套接字之间的连接过程分为三个步骤:服务器监听,客户端请求,连接确认。
1。服务器监听:服务器端套接字并不定位具体的客户端套接字,而是处于等待连接的状态,实时监控网络状态,等待客户端的连接请求。
2。客户端请求:指客户端的套接字提出连接请求,要连接的目标是服务器端的套接字。为此,客户端的套接字必须首先描述它要连接的服务器的套接字,指出服务器端套接字的地址和端口号,然后就向服务器端套接字提出连接请求。
3。连接确认:当服务器端套接字监听到或者说接收到客户端套接字的连接请求时,就响应客户端套接字的请求,建立一个新的线程,把服务器端套接字的描述发给客户端,一旦客户端确认了此描述,双方就正式建立连接。而服务器端套接字继续处于监听状态,继续接收其他客户端套接字的连接请求。
80.JVM结构

81.堆内作用
所有通过new创建的对象的内存都在堆中分配,其大小可以通过-Xmx和-Xms来控制。
82.
1. HashMap
1) hashmap的数据结构
Hashmap是一个数组和链表的结合体(在数据结构称“链表散列“),如下图示:

当我们往hashmap中put元素的时候,先根据key的hash值得到这个元素在数组中的位置(即下标),然后就可以把这个元素放到对应的位置中了。如果这个元素所在的位子上已经存放有其他元素了,那么在同一个位子上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。
2)使用
Map map = new HashMap();
map.put("Rajib Sarma","100");
map.put("Rajib Sarma","200");//The value "100" is replaced by "200".
map.put("Sazid Ahmed","200");
Iterator iter = map.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
Object key = entry.getKey();
Object val = entry.getValue();
}
83.HashTable和HashMap区别
第一,继承不同。
public class Hashtable extends Dictionary implements Map public class HashMap extends AbstractMap implements Map
第二
Hashtable 中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用Hashtable,但是要使用HashMap的话就要自己增加同步处理了。
第三
Hashtable中,key和value都不允许出现null值。
在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示 HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。
第四,两个遍历方式的内部实现上不同。
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
第五
哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
第六
Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
84.ArrayList和Vector的区别
ArrayList和Vector都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢,Vector由于使用了synchronized方法(线程安全),通常性能上较ArrayList差
85.ArrayList和LinkedList的区别
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
86.Linux下如何查看系统负载
top
87.linux下如何查看内存(free查看总的使用情况,ps或者top类似于进程管理器查看具体的使用情况) 硬盘使用情况(df)
88.js、ajax、dom、xpath的关系(ajax不是新技术,是一些技术的整合,前段采用js,dom可以使得html像xml一样按照节点访问,xpath用于查找xml节点)
89.Http中Get和Post的区别(Get用于查一些信息类似于sql中的select,post用于修改服务端的一些内容类似于update)
90.cookie和session的区别(cookie是保存在客户端的一些用户输入,session是保存在服务端的用户输入)
91.MySQL存储引擎 InnoDB与MyISAM的区别
基本的差别:MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持。MyISAM类型的表强调的是性能,其执行数度比InnoDB类型更快,但是不提供事务支持,而InnoDB提供事务支持以及外部键等高级数据库功能。
以下是一些细节和具体实现的差别:
1.InnoDB不支持FULLTEXT类型的索引。
2.InnoDB 中不保存表的具体行数,也就是说,执行select count(*) from table时,InnoDB要扫描一遍整个表来计算有多少行,但是MyISAM只要简单的读出保存好的行数即可。注意的是,当count(*)语句包含 where条件时,两种表的操作是一样的。
3.对于AUTO_INCREMENT类型的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中,可以和其他字段一起建立联合索引。
4.DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除。
5.LOAD TABLE FROM MASTER操作对InnoDB是不起作用的,解决方法是首先把InnoDB表改成MyISAM表,导入数据后再改成InnoDB表,但是对于使用的额外的InnoDB特性(例如外键)的表不适用。
另外,InnoDB表的行锁也不是绝对的,假如在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表,例如update table set num=1 where name like “%aaa%”
主要差别:两种类型最主要的差别就是Innodb 支持事务处理与外键和行级锁。而MyISAM不支持.所以MyISAM往往就容易被人认为只适合在小项目中使用。
92.背包问题-贪心法
http://blog.csdn.net/lzwglory/article/details/48267945
93 nio和堵塞I/o的区别
Java NIO非堵塞应用通常适用用在I/O读写等方面,我们知道,系统运行的性能瓶颈通常在I/O读写,包括对端口和文件的操作上,过去,在打开一个I/O通道后,read()将一直等待在端口一边读取字节内容,如果没有内容进来,read()也是傻傻的等,这会影响我们程序继续做其他事情,那么改进做法就是开设线程,让线程去等待,但是这样做也是相当耗费资源的。
Java
NIO非堵塞技术实际是采取Reactor模式,或者说是Observer模式为我们监察I/O端口,如果有内容进来,会自动通知我们,这样,我们就不必开启多个线程死等,从外界看,实现了流畅的I/O读写,不堵塞了。
NIO主要原理和适用。
NIO 有一个主要的类Selector,这个类似一个观察者,只要我们把需要探知的socketchannel告诉Selector,我们接着做别的事情,当有事件发生时,他会通知我们,传回一组SelectionKey,我们读取这些Key,就会获得我们刚刚注册过的socketchannel,然后,我们从这个Channel中读取数据,放心,包准能够读到,接着我们可以处理这些数据。
Selector内部原理实际是在做一个对所注册的channel的轮询访问,不断的轮询(目前就这一个算法),一旦轮询到一个channel有所注册的事情发生,比如数据来了,他就会站起来报告,交出一把钥匙,让我们通过这把钥匙来读取这个channel的内容。
package cn.nio;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
/**
* NIO服务端
* @author 小路
*/
public class NIOServer {
//通道管理器
private Selector selector;
/**
* 获得一个ServerSocket通道,并对该通道做一些初始化的工作
* @param port 绑定的端口号
* @throws IOException
*/
public void initServer(int port) throws IOException {
// 获得一个ServerSocket通道
ServerSocketChannel serverChannel = ServerSocketChannel.open();
// 设置通道为非阻塞
serverChannel.configureBlocking(false);
// 将该通道对应的ServerSocket绑定到port端口
serverChannel.socket().bind(new InetSocketAddress(port));
// 获得一个通道管理器
this.selector = Selector.open();
//将通道管理器和该通道绑定,并为该通道注册SelectionKey.OP_ACCEPT事件,注册该事件后,
//当该事件到达时,selector.select()会返回,如果该事件没到达selector.select()会一直阻塞。
serverChannel.register(selector, SelectionKey.OP_ACCEPT);
}
/**
* 采用轮询的方式监听selector上是否有需要处理的事件,如果有,则进行处理
* @throws IOException
*/
@SuppressWarnings("unchecked")
public void listen() throws IOException {
System.out.println("服务端启动成功!");
// 轮询访问selector
while (true) {
//当注册的事件到达时,方法返回;否则,该方法会一直阻塞
selector.select();
// 获得selector中选中的项的迭代器,选中的项为注册的事件
Iterator ite = this.selector.selectedKeys().iterator();
while (ite.hasNext()) {
SelectionKey key = (SelectionKey) ite.next();
// 删除已选的key,以防重复处理
ite.remove();
// 客户端请求连接事件
if (key.isAcceptable()) {
ServerSocketChannel server = (ServerSocketChannel) key
.channel();
// 获得和客户端连接的通道
SocketChannel channel = server.accept();
// 设置成非阻塞
channel.configureBlocking(false);
//在这里可以给客户端发送信息哦
channel.write(ByteBuffer.wrap(new String("向客户端发送了一条信息").getBytes()));
//在和客户端连接成功之后,为了可以接收到客户端的信息,需要给通道设置读的权限。
channel.register(this.selector, SelectionKey.OP_READ);
// 获得了可读的事件
} else if (key.isReadable()) {
read(key);
}
}
}
}
/**
* 处理读取客户端发来的信息 的事件
* @param key
* @throws IOException
*/
public void read(SelectionKey key) throws IOException{
// 服务器可读取消息:得到事件发生的Socket通道
SocketChannel channel = (SocketChannel) key.channel();
// 创建读取的缓冲区
ByteBuffer buffer = ByteBuffer.allocate(10);
channel.read(buffer);
byte[] data = buffer.array();
String msg = new String(data).trim();
System.out.println("服务端收到信息:"+msg);
ByteBuffer outBuffer = ByteBuffer.wrap(msg.getBytes());
channel.write(outBuffer);// 将消息回送给客户端
}
/**
* 启动服务端测试
* @throws IOException
*/
public static void main(String[] args) throws IOException {
NIOServer server = new NIOServer();
server.initServer(8000);
server.listen();
}
}
94.快速排序
快速排序 对冒泡排序的一种改进,若初始记录序列按关键字有序或基本有序,蜕化为冒泡排序。使用的是递归原理,在所有同数量级O(n longn) 的排序方法中,其平均性能最好。就平均时间而言,是目前被认为最好的一种内部排序方法
基本思想是:通过一躺排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
三个指针: 第一个指针称为pivotkey指针(枢轴),第二个指针和第三个指针分别为left指针和right指针,分别指向最左边的值和最右边的值。left指针和right指针从两边同时向中间逼近,在逼近的过程中不停的与枢轴比较,将比枢轴小的元素移到低端,将比枢轴大的元素移到高端,枢轴选定后永远不变,最终在中间,前小后大。
需要两个函数:
① 递归函数 public static void quickSort(int[]n ,int left,int right)
② 分割函数(一趟快速排序函数) public static int partition(int[]n ,int left,int right)
/** * 快速排序 * */ public class QuickSort { public static void main(String[] args) { int[] array = { 49, 38, 65, 97, 76, 13, 27 }; quickSort(array, 0, array.length - 1); for (int i = 0; i < array.length; i++) { System.out.println(array[i]); } } public static void quickSort(int[] array, int left, int right) { int middleIndex; if (left < right) { middleIndex = getMiddle(array, left, right);//获得中间的位置 quickSort(array, left, middleIndex - 1);//遍历左面的 quickSort(array, middleIndex + 1, right);//遍历右面的 } } public static int getMiddle(int[] array, int left, int right) { int middleValue = array[left]; int middleIndex = left; while (left < right) { while (left < right && array[right] >= middleValue) {//右在上面否则遍历错误,因为起始的中轴在左面 right--; } array[left] = array[right]; while (left < right && array[left] <= middleValue) { left++; } array[right] = array[left]; } if (left == right) {//如果左右相等第一次遍历完成 middleIndex = left;//left、right都可以 array[middleIndex] = middleValue;//把中间值放到空缺位置 } return middleIndex; } }
95.简单选择排序:
简单选择排序:(选出最小值,放在第一位,然后第一位向后推移,如此循环)第一位与后面每一个逐个比较,每次都使最小的置顶,第一位向后推进(即刚选定的第一位是最小值,不再参与比较,比较次数减1)
复杂度: 所需进行记录移动的操作次数较少 0--3(n-1) ,无论记录的初始排列如何,所需的关键字间的比较次数相同,均为n(n-1)/2,总的时间复杂度为O(n2);
空间复杂度 O(1)
算法改进:每次对比,都是为了将最小的值放到第一位,所以可以一比到底,找出最小值,直接放到第一位,省去无意义的调换移动操作。也可以换一个方向,最后一位与前面每一个比较,每次使最大值沉底,最后一位向前推进。
/**
*
* 简单选择
*/
public class SimpleSelectSort {
public static void main(String[] args) {
int[] array = { 49, 38, 65, 97, 76, 13, 27 };
selectSort(array);
for (int i = 0; i < array.length; i++) {
System.out.println(array[i]);
}
}
public static void selectSort(int[] array){
int minIndex;
int tempValue;
for(int i=0;i<array.length-1;i++){//最后一位已经排好序不用再排了
minIndex=i;
for(int j=i+1;j<array.length;j++){//从下一位开始找出最小位的下标
if(array[j]<array[minIndex]){
minIndex=j;
}
}
if(minIndex!=i){//如果最小值没有变化不互调位置
tempValue=array[minIndex];
array[minIndex]=array[i];
array[i]=tempValue;
}
}
}
}
96.直接插入排序
直接插入排序(Straight Insertion Sorting)的基本思想:在要排序的一组数中,假设前面(n-1) [n>=2] 个数已经是排好顺序的,现在要把第n个数插到前面的有序数中,使得这n个数也是排好顺序的。如此反复循环,直到全部排好顺序。
复杂度:时间复杂度 O(n2) ,空间复杂度O(1)
稳定性: 插入排序是稳定的,排序前后两个相等元素相对次序不变(能保证排序前2个相等的数其在序列的前后位置顺序和排序后它们两个的前后位置顺序相同。在简单形式化一下,如果Ai = Aj, Ai原来在位置前,排序后Ai还是要在Aj位置前。)
结构的复杂性及适用情况:是一种简单的排序方法,不仅适用于顺序存储结构(数组),而且适用于链接存储结构,不过在链接存储结构上进行直接插入排序时,不用移动元素的位置,而是修改相应的指针。
哨兵的作用
算法中引进的附加记录R[0]称监视哨或哨兵(Sentinel)。
哨兵有两个作用:
① 进人查找(插入位置)循环之前,它保存了R[i]的副本,使不致于因记录后移而丢失R[i]的内容;
② 它的主要作用是:在查找循环中"监视"下标变量j是否越界。一旦越界(即j=0),因为R[0].key和自己比较,循环判定条件不成立使得查找循环结束,从而避免了在该循环内的每一次均要检测j是否越界(即省略了循环判定条件"j>=1")。
注意:
① 实际上,一切为简化边界条件而引入的附加结点(元素)均可称为哨兵。
【例】单链表中的头结点实际上是一个哨兵
② 引入哨兵后使得测试查找循环条件的时间大约减少了一半,所以对于记录数较大的文件节约的时间就相当可观。对于类似于排序这样使用频率非常高的算法,要尽可能地减少其运行时间。所以不能把上述算法中的哨兵视为雕虫小技,而应该深刻理解并掌握这种技巧。
package com.sort3;
/**
* 直接插入
*
*/
public class StraightInsertionSort {
public static void main(String[] args) {
int[] array = { 49, 38, 65, 97, 76, 13, 27 };
straightInsertionSort(array);
for (int i = 0; i < array.length; i++) {
System.out.println(array[i]);
}
}
public static void straightInsertionSort(int[] array) {
for (int i = 0; i < array.length - 1; i++) {// 在倒数第二位的时候就已经排好序了
int j = i;// i之前的顺序是正确
int sentryValue = array[j + 1];
while (j >= 0 && array[j] > sentryValue) {// 当有小值的时候,前面排好序的向后移
array[j + 1] = array[j];
j--;
}
if(j!=i){
array[j + 1] = sentryValue;
}
}
}
}
97.希尔排序
希尔排序(缩小增量排序)基本思想:算法先将要排序的一组数按某个增量d(n/2,n为要排序数的个数)分成若干组,每组中记录的下标相差d。对每组中全部元素进行直接插入排序,然后再用一个较小的增量(d/2)对它进行分组,在每组中再进行直接插入排序。当增量减到1时,进行直接插入排序后,排序完成。
复杂度:平均时间复杂度O(n1.25) 空间复杂度 O(1)
实例图 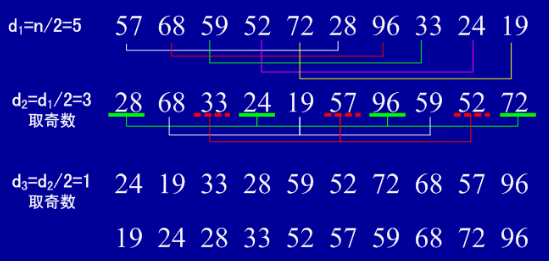
增量序列的选择
Shell排序的执行时间依赖于增量序列。
好的增量序列的共同特征:
① 最后一个增量必须为1;
② 应该尽量避免序列中的值(尤其是相邻的值)互为倍数的情况。
有人通过大量的实验,给出了目前较好的结果:当n较大时,比较和移动的次数约在nl.25到1.6n1.25之间。
Shell排序的时间性能优于直接插入排序
希尔排序的时间性能优于直接插入排序的原因:
①当文件初态基本有序时直接插入排序所需的比较和移动次数均较少。
②当n值较小时,n和n2的差别也较小,即直接插入排序的最好时间复杂度O(n)和最坏时间复杂度0(n2)差别不大。
③在希尔排序开始时增量较大,分组较多,每组的记录数目少,故各组内直接插入较快,后来增量di逐渐缩小,分组数逐渐减少,而各组的记录数目逐渐增多,但由于已经按di-1作为距离排过序,使文件较接近于有序状态,所以新的一趟排序过程也较快。
因此,希尔排序在效率上较直接插人排序有较大的改进。
稳定性: 希尔排序是不稳定的。
/**
* 希尔排序
*
*/
public class ShellSort {
public static void main(String[] args) {
int[] array = { 49, 38, 65, 97, 76, 13, 27 };
shellSort(array);
for (int i = 0; i < array.length; i++) {
System.out.println(array[i]);
}
}
public static void shellSort(int[] array) {
double increment = array.length;// 增量长度
int dk;// 确定增量长度
int k;// 替换参数防止遍历错误
while (true) {
increment = (int) Math.ceil(increment / 2);
dk = (int) increment;// 确定增量长度
for (int i = 0; i < dk; i++) {
for (int j = i; j < array.length - dk; j += dk) {// j不以0开始,以i开始可以减少遍历次数
k = j;
int sentryValue = array[k + dk];// 哨兵位
while (k >= 0 && array[k] > sentryValue) {
array[k + dk] = array[k];
k -= dk;
}
if (k != j) {// 如果这轮没有换位,就不需要把哨兵位补上去
array[k + dk] = sentryValue;
}
}
}
if (dk == 1) {// 增量为1的时候结束
break;
}
}
}
}
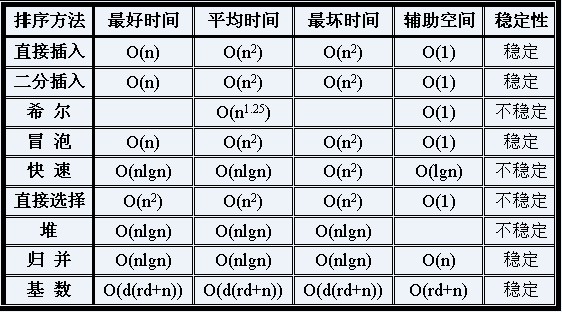
98.排序算法分析
冒择入希快归堆

99.二分查找法
public class BinarySearch {
public static void main(String[] args) {
int[] src = new int[] { 1, 3, 5, 7, 8, 9 };
System.out.println(binarySearch(src, 3));
}
public static boolean binarySearch(int[] array, int desc) {
int low = 0;
int high = array.length - 1;
while (low <= high) {
int middle = (low + high) / 2;
if (array[middle] == desc) {
return true;
} else if (array[middle] > desc) {
high = middle - 1;
} else if (array[middle] < desc) {
low = middle + 1;
}
}
return false;
}
}
/**
* 二分查找又称折半查找,它是一种效率较高的查找方法。
【二分查找要求】:1.必须采用顺序存储结构 2.必须按关键字大小有序排列。
*
*/
public class BinarySearch {
public static void main(String[] args) {
int[] src = new int[] {1, 3, 5, 7, 8, 9};
System.out.println(binarySearch(src, 3));
System.out.println(binarySearch(src,3,0,src.length-1));
}
/**
* * 二分查找算法 * *
*
* @param srcArray
* 有序数组 *
* @param des
* 查找元素 *
* @return des的数组下标,没找到返回-1
*/
public static int binarySearch(int[] array,int desc){
int low=0;
int high=array.length-1;
while(low<=high){
int middle=(low+high)/2;
if(desc==array[middle]){
return desc;
}else if(desc>array[middle]){
low=middle+1;
}else if(desc<array[middle]){
high=middle-1;
}
}
return -1;
}
/**
*二分查找特定整数在整型数组中的位置(递归)
*@paramdataset
*@paramdata
*@parambeginIndex
*@paramendIndex
*@returnindex
*/
public static int binarySearch(int[] array,int desc,int low,int high){
int middle=(low+high)/2;
if(low>high||desc<array[low]||desc>array[high]){
return -1;
}
if(desc>array[middle]){
return binarySearch(array,desc,middle+1,high);
}else if(desc<array[middle]){
return binarySearch(array,desc,low,middle-1);
}else{
return desc;
}
}
}
100.MySQL的btree索引和hash索引的区别
mysql最常用的索引结构是btree(O(log(n))),但是总有一些情况下我们为了更好的性能希望能使用别的类型的索引。hash就是其中一种选择,例如我们在通过用户名检索用户id的时候,他们总是一对一的关系,用到的操作符只是=而已,假如使用hash作为索引数据结构的话,时间复杂度可以降到O(1)。不幸的是,目前的mysql版本(5.6)中,hash只支持MEMORY和NDB两种引擎,而我们最常用的INNODB和MYISAM都不支持hash类型的索引。
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
可能很多人又有疑问了,既然 Hash 索引的效率要比 B-Tree 高很多,为什么大家不都用 Hash 索引而还要使用 B-Tree 索引呢?任何事物都是有两面性的,Hash 索引也一样,虽然 Hash 索引效率高,但是 Hash 索引本身由于其特殊性也带来了很多限制和弊端,主要有以下这些。
(1)Hash 索引仅仅能满足"=","IN"和"<=>"查询,不能使用范围查询。
由于 Hash 索引比较的是进行 Hash 运算之后的 Hash 值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的 Hash 算法处理之后的 Hash 值的大小关系,并不能保证和Hash运算前完全一样。
(2)Hash 索引无法被用来避免数据的排序操作。
由于 Hash 索引中存放的是经过 Hash 计算之后的 Hash 值,而且Hash值的大小关系并不一定和 Hash 运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;
(3)Hash 索引不能利用部分索引键查询。
对于组合索引,Hash 索引在计算 Hash 值的时候是组合索引键合并后再一起计算 Hash 值,而不是单独计算 Hash 值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash 索引也无法被利用。
(4)Hash 索引在任何时候都不能避免表扫描。
前面已经知道,Hash 索引是将索引键通过 Hash 运算之后,将 Hash运算结果的 Hash 值和所对应的行指针信息存放于一个 Hash 表中,由于不同索引键存在相同 Hash 值,所以即使取满足某个 Hash 键值的数据的记录条数,也无法从 Hash 索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
(5)Hash 索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
对于选择性比较低的索引键,如果创建 Hash 索引,那么将会存在大量记录指针信息存于同一个 Hash 值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下
101.memcached对item的过期时间有什么限制?
item对象的过期时间最长可以达到30天。memcached把传入的过期时间(时间段)解释成时间点后,一旦到了这个时间点,memcached就把item置为失效状态,这是一个简单的观察者机制。