一个中文博客:http://blog.sina.com.cn/s/blog_6849f0730100we95.html
排序方法详解(文档):
Proc rank 计算 观测值对应数值型变量的秩次
语法:
Proc rank <options>;
By <descending> variable-1 <descending> variable-n
<notsorted> ;*分组变量;
Var data-set-variables(s);*设定待排序求秩变量;
Ranks new-variable(s);*含秩次的变量;
Options中求秩排序的方法:
1.1FRACTION
computes fractional ranks by dividing each rank by the number of observations having nonmissing values of the ranking variable
TIES=HIGH is the default with the FRACTION option. With TIES=HIGH, fractional ranks are considered values of a right-continuous empirical cumulative distribution function.
1.2NPLUS1
computes fractional ranks by dividing each rank by the denominator n+1, where n is the number of observations having nonmissing values of the ranking variable.
2.GROUPS=number-of-groups
assigns group values ranging from 0 to number-of-groups minus 1. Common specifications are GROUPS=100 for percentiles, GROUPS=10 for deciles, and GROUPS=4 for quartiles. For example, GROUPS=4 partitions the original
values into four groups, with the smallest values receiving, by default, a quartile value of 0 and the largest values receiving a quartile value of 3.
The formula for calculating group values is
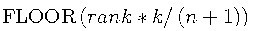
where FLOOR is the FLOOR function, rank is the value's order rank, k is the value of GROUPS=, and n is the number of observations having nonmissing values of the ranking variable.
If the number of observations is evenly divisible by the number of groups, each group has the same number of observations, provided there are no tied values at the boundaries of the groups. Grouping observations
by a variable that has many tied values can result in unbalanced groups because PROC RANK always assigns observations with the same value to the same group.
3.NORMAL=BLOM | TUKEY | VW
computes normal scores from the ranks. The resulting variables appear normally distributed. The formulas are

where ri is the rank of the ith observation, and
n is the number of nonmissing observations for the ranking variable.
VW stands for van der Waerden. With NORMAL=VW, you can use the scores for a nonparametric location test. All three normal scores are approximations to the exact expected order statistics for the normal distribution,
also called normal scores. The BLOM version appears to fit slightly better than the others (Blom 1958; Tukey 1962).
4. PERCENT
divides each rank by the number of observations that have nonmissing values of the variable and multiplies the result by 100 to get a percentage.
5. SAVAGE
computes Savage (or exponential) scores from the ranks by the following formula (Lehman 1998):
TIES=HIGH | LOW | MEAN
specifies how to compute normal scores or ranks for tied data values.
HIGH
assigns the largest of the corresponding ranks (or largest of the normal scores when NORMAL= is specified).
LOW
assigns the smallest of the corresponding ranks (or smallest of the normal scores when NORMAL= is specified).
MEAN
assigns the mean of the corresponding rank (or mean of the normal scores when NORMAL= is specified).