1 second
256 megabytes
standard input
standard output
When Sasha was studying in the seventh grade, he started listening to music a lot. In order to evaluate which songs he likes more, he introduced the notion of the song's
prettiness. The title of the song is a word consisting of uppercase Latin letters. The
prettiness of the song is the
prettiness of its title.
Let's define the simple prettiness of a word as the ratio of the number of vowels in the word to the number of all letters in the word.
Let's define the prettiness of a word as the sum of
simple prettiness of all the substrings of the word.
More formally, let's define the function vowel(c) which is equal to
1, if c is a vowel, and to
0 otherwise. Let si be the
i-th character of string
s, and si..j be the substring of word
s, staring at the i-th character and ending at the
j-th character (sisi + 1...
sj,
i ≤ j).
Then the simple prettiness of
s is defined by the formula:
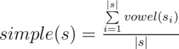
The prettiness of
s equals
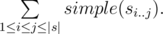
Find the prettiness of the given song title.
We assume that the vowels are I, E, A, O, U, Y.
The input contains a single string s (1 ≤ |s| ≤ 5·105) — the title of the song.
Print the prettiness of the song with the absolute or relative error of at most
10 - 6.
IEAIAIO
28.0000000
BYOB
5.8333333
YISVOWEL
17.0500000
In the first sample all letters are vowels. The
simple prettiness of each substring is 1. The word of length
7 has 28 substrings. So, the
prettiness of the song equals to
28.
我们单独考虑每一个元音字符,对于一个元音字符,先考虑以它为结尾字符的串,设这个字符的位置为i,字符串长度为len
则有 (1 / 2) + ...+ (1 / (i + 1))
再考虑 以它开始的串
有 (1 / 2) + ...+ (1 / (len - i ))
单个字符的串 1个
这个字符在串中间出现:
(1 / 3) + (1 / 4) + ... + (1 / (len - i + 1)) = sum[len - i + 1] - sum[2]
(1 / 4) + (1 / 5) + ... + (1 / (len - i + 2)) = sum[len - i + 2] - sum[3]
...
(1 / (i + 2)) + (1 / (i + 3)) + ... + (1 / len) = sum[len] - sum[i + 1]
各个式子相加: sum[len - i + 1] + ... + sum[len] - (sum[2] + sum[3] + .. + sum[i + 1]) = t[len] - t[len - i - 1] - (t[i + 1] - t[1])
于是只要维护前缀和和它的前缀和就行了
/*************************************************************************
> File Name: cf289E.cpp
> Author: ALex
> Mail: zchao1995@gmail.com
> Created Time: 2015年01月31日 星期六 21时17分58秒
************************************************************************/
#include <map>
#include <set>
#include <queue>
#include <stack>
#include <vector>
#include <cmath>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const double pi = acos(-1);
const int inf = 0x3f3f3f3f;
const double eps = 1e-15;
typedef long long LL;
typedef pair <int, int> PLL;
vector <int> p;
const int N = 5 * 101000;
char str[N];
bool flag[26];
double sum[N];
double t[N];
int main ()
{
memset (flag, 0, sizeof(flag));
flag['A' - 'A'] = 1;
flag['E' - 'A'] = 1;
flag['I' - 'A'] = 1;
flag['O' - 'A'] = 1;
flag['U' - 'A'] = 1;
flag['Y' - 'A'] = 1;
sum[1] = 1;
for (int i = 2; i <= N - 10; ++i)
{
sum[i] = (1.0 / i) + sum[i - 1];
}
t[1] = 1;
for (int i = 2; i <= N - 10; ++i)
{
t[i] = t[i - 1] + sum[i];
}
while (~scanf("%s", str))
{
int len = strlen (str);
double ans = 0;
for (int i = 0; i < len; ++i)
{
if (flag[str[i] - 'A'])
{
ans += sum[i + 1] - 1 + sum[len - i];
ans += t[len] - t[len - i] - t[i + 1] + t[1];
}
}
printf("%.7f\n", ans);
}
return 0;
}