社会计算课程作业是写个推荐系统,闲来无事,就把写的这个推荐系统和大家分享下!
我所使用的方法是svd(矩阵奇异值分解),通俗的说就是这样的一个公式
A=UV
就是将原来的矩阵分解成为两个矩阵的乘积的形式,其中 A为mn,而对应的U就是mt,V就是tn,为什么要这么做的?
我们来从数据进行分析下,我们以一个电影推荐系统为例子,
通常我们拿到的数据是这样的一个表格
|
|
movie_1 |
movie_2 |
movie_3 |
movie_4 |
|
user_1 |
4.0 |
|
1.0 |
|
|
user_2 |
|
3.0 |
|
|
表格中有用户对相应的电影的打分情况,分值1~5,分值越高,表示用户越喜欢该电影。
但显然,实际中的表格要比我的这个行(用户)和列(电影)多的多,同时我们也知道用户不可能对每一部电影都有评价(他没有精力去看过每一部电影),在这个表格的情况下,我们的工作就是根据一种预测模型,将空缺的项给填充上,而填充之后我们就可以根绝这个预测的结果对用户进行影片的推荐了。这就是一个最基本的推荐系统。
那么,如何来对这个表格进行预测呢?
事实上,我就使用了svd算法,这个表格就是一个矩阵,我们设为A,我要用两个矩阵的乘积UV来实现我这个功能,那么这么做的物理意义是怎么样的呢?
我个人是这样理解的
|
|
动作 |
喜剧 |
国产 |
欧美 |
悬疑 |
|
user_1 |
|
|
|
|
|
|
user_2 |
|
|
|
|
|
矩阵 U
|
|
动作 |
喜剧 |
国产 |
欧美 |
悬疑 |
|
movie_1 |
|
|
|
|
|
|
movie_2 |
|
|
|
|
|
|
movie_3 |
|
|
|
|
|
|
movie_4 |
|
|
|
|
|
矩阵
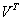
通过这两个矩阵的分解,我们就可以得到了与物理意义的两个矩阵,我们让这两个矩阵的乘积尽量的逼近原来的矩阵,从而我们就可以得到原来的矩阵中empty元素的值了。
我们现在知道了具体的想法,就要想方设法的实现这个矩阵分解,那么如何实现矩阵分解呢?
这就涉及到一些数学知识了,我们想让我们的矩阵乘积和原始矩阵尽量的接近,那么我们就要优化的函数也就是
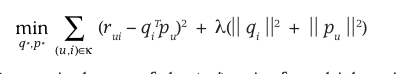
这个公式中,rui表示的是原始矩阵A中u行i列的元素,而qi表示的V矩阵的第i列,pu表示的U矩阵的u行,而公式的后面部分是为了防止过拟合用的。
其实仔细看这个公式接可以发现,它就是用的最小二乘法,而最小二乘法的原理就是认为我们的预测结果值和真实值之间的误差是服从高斯分布的,关于这个内容,有兴趣的同学可以查看NG老师机器学习公开课!
言归正传,下面就是我们写程序对这个公式进行最优化处理了,这里我们是求最小值,则我们是使用梯度下降的方法,通过一些数学证明可以看到在二次目标函数的情况下,局部最优解就是全局最优解(这个我这里就不往下介绍了,有兴趣的同学可以查看最优化方法这门课程)。而梯度下降的话,如果我们每次更新迭代的时候都计算已知矩阵的每一项的误差的然后在求和的话,显然这个计算量是太大了,所以我们要引入随即梯度下降的方法,对数据迭代更新只是每次对一个数据进行处理,把所有的数据都处理完了就是一次完整的迭代!(一开始我写程序用的是梯度下降,迭代一次需要很久很久....引入随即梯度下降之后,用python写的程序每次迭代几秒中..........)。
至此,关于这个算法的一个粗浅的介绍就算是完成了,代码我在github整理下,然后把连接再给大家发上来!