卡尔曼滤波
卡尔曼滤波是一种高效率的递归滤波器(自回归滤波器),
它能够从一系列的不完全及包含噪声的测量(英文:measurement)中,估计动态系统的状态。
目录[隐藏] |
[编辑]应用实例
卡尔曼滤波的一个典型实例是从一组有限的,包含噪声的,对物体位置的观察序列(可能有偏差)预测出物体的位置的坐标及速度。在很多工程应用(如雷达、计算机视觉)中都可以找到它的身影。同时,卡尔曼滤波也是控制理论以及控制系统工程中的一个重要课题。
例如,对于雷达来说,人们感兴趣的是其能够跟踪目标。但目标的位置、速度、加速度的测量值往往在任何时候都有噪声。卡尔曼滤波利用目标的动态信息,设法去掉噪声的影响,得到一个关于目标位置的好的估计。这个估计可以是对当前目标位置的估计(滤波),也可以是对于将来位置的估计(预测),也可以是对过去位置的估计(插值或平滑)。
[编辑]命名
这种滤波方法以它的发明者鲁道夫.E.卡尔曼(Rudolph
E. Kalman)命名,但是根据文献可知实际上Peter Swerling在更早之前就提出了一种类似的算法。
斯坦利.施密特(Stanley Schmidt)首次实现了卡尔曼滤波器。卡尔曼在NASA埃姆斯研究中心访问时,发现他的方法对于解决阿波罗计划的轨道预测很有用,后来阿波罗飞船的导航电脑便使用了这种滤波器。
关于这种滤波器的论文由Swerling (1958)、Kalman (1960)与 Kalman and Bucy (1961)发表。
目前,卡尔曼滤波已经有很多不同的实现.卡尔曼最初提出的形式现在一般称为简单卡尔曼滤波器。除此以外,还有施密特扩展滤波器、信息滤波器以及很多Bierman, Thornton 开发的平方根滤波器的变种。也许最常见的卡尔曼滤波器是锁相环,它在收音机、计算机和几乎任何视频或通讯设备中广泛存在。
[编辑]基本动态系统模型
卡尔曼滤波建立在线性代数和隐马尔可夫模型(hidden
Markov model)上。其基本动态系统可以用一个马尔可夫链表示,该马尔可夫链建立在一个被高斯噪声(即正态分布的噪声)干扰的线性算子上的。系统的状态可以用一个元素为实数的向量表示。
随着离散时间的每一个增加,这个线性算子就会作用在当前状态上,产生一个新的状态,并也会带入一些噪声,同时系统的一些已知的控制器的控制信息也会被加入。同时,另一个受噪声干扰的线性算子产生出这些隐含状态的可见输出。
为了从一系列有噪声的观察数据中用卡尔曼滤波器估计出被观察过程的内部状态,我们必须把这个过程在卡尔曼滤波的框架下建立模型。也就是说对于每一步k,定义矩阵Fk, Hk, Qk,Rk,有时也需要定义Bk,如下。

卡尔曼滤波模型假设k时刻的真实状态是从(k − 1)时刻的状态演化而来,符合下式:
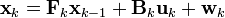
其中

时刻k,对真实状态 xk的一个测量zk满足下式:
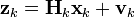
其中Hk是观测模型,它把真实状态空间映射成观测空间,vk 是观测噪声,其均值为零,协方差矩阵为Rk,且服从正态分布。
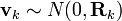
初始状态以及每一时刻的噪声{x0, w1, ..., wk, v1 ... vk} 都认为是互相独立的.
实际上,很多真实世界的动态系统都并不确切的符合这个模型;但是由于卡尔曼滤波器被设计在有噪声的情况下工作,一个近似的符合已经可以使这个滤波器非常有用了。更多其它更复杂的卡尔曼滤波器的变种,在下边讨论中有描述。
[编辑]卡尔曼滤波器
卡尔曼滤波是一种递归的估计,即只要获知上一时刻状态的估计值以及当前状态的观测值就可以计算出当前状态的估计值,因此不需要记录观测或者估计的历史信息。卡尔曼滤波器与大多数滤波器不同之处,在于它是一种纯粹的时域滤波器,它不需要像低通滤波器等频域滤波器那样,需要在频域设计再转换到时域实现。
卡尔曼滤波器的状态由以下两个变量表示:
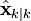 ,在时刻k 的状态的估计;
,在时刻k 的状态的估计; ,误差相关矩阵,度量估计值的精确程度。
,误差相关矩阵,度量估计值的精确程度。
卡尔曼滤波器的操作包括两个阶段:预测与更新。在预测阶段,滤波器使用上一状态的估计,做出对当前状态的估计。在更新阶段,滤波器利用对当前状态的观测值优化在预测阶段获得的预测值,以获得一个更精确的新估计值。
[编辑]预测
-
 (预测状态)
(预测状态)  (预测估计共变异数)
(预测估计共变异数)
可参考:http://www.cs.unc.edu/~welch/media/pdf/kalman_intro.pdf
[编辑]更新
-
 (测量余量,measurement
(测量余量,measurement
residual)  (测量余量共变异数)
(测量余量共变异数) (卡尔曼增益)
(卡尔曼增益) (更新的状态估计)
(更新的状态估计) (更新的共变异数估计)
(更新的共变异数估计)
使用上述公式计算仅在最优卡尔曼增益的时候有效。使用其他增益的话,公式要复杂一些,请参见推导。
[编辑]不变量(Invariant)
如果模型准确,而且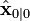 与
与 的值准确的反映了最初状态的分布,那么以下不变量就保持不变:所有估计的误差均值为零
的值准确的反映了最初状态的分布,那么以下不变量就保持不变:所有估计的误差均值为零
![\textrm{E}[\textbf{x}_k - \hat{\textbf{x}}_{k|k}] = \textrm{E}[\textbf{x}_k - \hat{\textbf{x}}_{k|k-1}] = 0](http://upload.wikimedia.org/wikipedia/zh/math/c/9/2/c9203d41067d91d378d6856103fedfd2.png)
![\textrm{E}[\tilde{\textbf{y}}_k] = 0](http://upload.wikimedia.org/wikipedia/zh/math/b/5/a/b5a54dc85106b58adbb9909c0b3fb1a3.png)
且 共变异数矩阵 准确的反映了估计的共变异数:

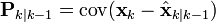

请注意,其中![\textrm{E}[\textbf{a}]](http://upload.wikimedia.org/wikipedia/zh/math/c/8/f/c8f5b976bcd4b542e5704261b9cb3d2f.png) 表示a的期望值,
表示a的期望值, ![\textrm{cov}(\textbf{a}) = \textrm{E}[\textbf{a}\textbf{a}^T]](http://upload.wikimedia.org/wikipedia/zh/math/1/a/8/1a81fb041af0656bb2d5dfc71466b067.png) 。
。
[编辑]实例
考虑在无摩擦的、无限长的直轨道上的一辆车。该车最初停在位置 0 处,但时不时受到随机的冲击。我们每隔Δt秒即测量车的位置,但是这个测量是非精确的;我们想建立一个关于其位置以及速度的模型。我们来看如何推导出这个模型以及如何从这个模型得到卡尔曼滤波器。
因为车上无动力,所以我们可以忽略掉Bk 和uk。由于F、H、R 和Q 是常数,所以时间下标可以去掉。
车的位置以及速度(或者更加一般的,一个粒子的运动状态)可以被线性状态空间描述如下:

其中 是速度,也就是位置对于时间的导数。
是速度,也就是位置对于时间的导数。
我们假设在(k − 1)时刻与k时刻之间,车受到ak的加速度,其符合均值为0,标准差为σa的正态分布。根据牛顿运动定律,我们可以推出

其中

且

我们可以发现
-
![\textbf{Q} = \textrm{cov}(\textbf{G}a) = \textrm{E}[(\textbf{G}a)(\textbf{G}a)^{T}] = \textbf{G} \textrm{E}[a^2] \textbf{G}^{T} = \textbf{G}[\sigma_a^2]\textbf{G}^{T} = \sigma_a^2 \textbf{G}\textbf{G}^{T}](http://upload.wikimedia.org/wikipedia/zh/math/0/e/c/0ec2936f75d8424cbc2de843a269cec8.png) (因为 σa 是一个标量).
(因为 σa 是一个标量).
在每一时刻,我们对其位置进行测量,测量受到噪声干扰.我们假设噪声服从正态分布,均值为0,标准差为σz。

其中

且
![\textbf{R} = \textrm{E}[\textbf{v}_k \textbf{v}_k^{T}] = \begin{bmatrix} \sigma_z^2 \end{bmatrix}](http://upload.wikimedia.org/wikipedia/zh/math/9/1/a/91af04d30a1712b8237b2d4fc82e50a9.png)
如果我们知道足够精确的车最初的位置,那么我们可以初始化

并且,我们告诉滤波器我们知道确切的初始位置,我们给出一个协方差矩阵:

如果我们不确切的知道最初的位置与速度,那么协方差矩阵可以初始化为一个对角线元素是B的矩阵,B取一个合适的比较大的数。

此时,与使用模型中已有信息相比,滤波器更倾向于使用初次测量值的信息。
[编辑]推导
[编辑]推导后验协方差矩阵
按照上边的定义,我们从误差协方差开始推导如下:

代入

再代入 

与 
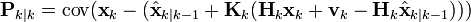
整理误差向量,得

因为测量误差vk 与其他项是非相关的,因此有

利用协方差矩阵的性质,此式可以写作

使用不变量Pk|k-1以及Rk的定义 这一项可以写作 :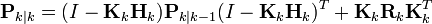 这一公式对于任何卡尔曼增益Kk都成立。如果Kk是最优卡尔曼增益,则可以进一步简化,请见下文。
这一公式对于任何卡尔曼增益Kk都成立。如果Kk是最优卡尔曼增益,则可以进一步简化,请见下文。
[编辑]最优卡尔曼增益的推导
卡尔曼滤波器是一个最小均方误差估计器,后验状态误差估计(英文:a posteriori state
estimate)是

我们最小化这个矢量幅度平方的期望值,![\textrm{E}[|\textbf{x}_{k} - \hat{\textbf{x}}_{k|k}|^2]](http://upload.wikimedia.org/wikipedia/zh/math/3/b/4/3b40022edea8b7435f22199f63727849.png) ,这等同于最小化后验估计协方差矩阵 Pk|k的迹(trace)。将上面方程中的项展开、抵消,得到:
,这等同于最小化后验估计协方差矩阵 Pk|k的迹(trace)。将上面方程中的项展开、抵消,得到:
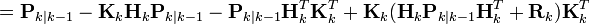

当矩阵导数是 0 的时候得到Pk|k的迹(trace)的最小值:

此处须用到一个常用的式子, 如下:
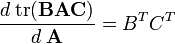
从这个方程解出卡尔曼增益Kk:


这个增益称为最优卡尔曼增益,在使用时得到最小均方误差。
[编辑]后验误差协方差公式的化简
在卡尔曼增益等于上面导出的最优值时,计算后验协方差的公式可以进行简化。在卡尔曼增益公式两侧的右边都乘以 SkKkT 得到
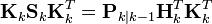
根据上面后验误差协方差展开公式,
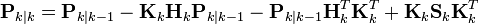
最后两项可以抵消,得到
-
 .
.
这个公式的计算比较简单,所以实际中总是使用这个公式,但是需注意这公式仅在使用最优卡尔曼增益的时候它才成立。如果算术精度总是很低而导致数值稳定性出现问题,或者特意使用非最优卡尔曼增益,那么就不能使用这个简化;必须使用上面导出的后验误差协方差公式。
[编辑]与递归Bayesian估计之间的关系
假设真正的状态是无法观察的马尔可夫过程,测量结果是从隐性马尔可夫模型观察到的状态。
根据马尔可夫假设,真正的状态仅受最近一个状态影响而与其它以前状态无关。

与此类似,在时刻 k 测量只与当前状态有关而与其它状态无关。

根据这些假设,隐性马尔可夫模型所有状态的概率分布可以简化为:

然而,当卡尔曼滤波器用来估计状态x的时候,我们感兴趣的机率分布,是基于目前为止所有个测量值来得到的当前状态之机率分布

[编辑]信息滤波器
[编辑]非线性滤波器
基本卡尔曼滤波器(The basic Kalman filter)是限制在线性的假设之下。然而,大部份非平凡的(non-trial)的系统都是非线性系统。其中的“非线性性质”(non-linearity )可能是伴随存在过程模型(process model)中或观测模型(observation model)中,或者两者兼有之。
[编辑]扩展卡尔曼滤波器
在扩展卡尔曼滤波器(Extended Kalman Filter,简称EKF)中状态转换和观测模型不需要是状态的线性函数,可替换为(可微的)函数。

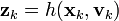
函数 f 可以用来从过去的估计值中计算预测的状态,相似的,函数 h可以用来以预测的状态计算预测的测量值。然而 f 和 h 不能直接的应用在协方差中,取而代之的是计算偏导矩阵(Jacobian)。
在每一步中使用当前的估计状态计算Jacobian矩阵,这几个矩阵可以用在卡尔曼滤波器的方程中。这个过程,实质上将非线性的函数在当前估计值处线性化了。
这样一来,卡尔曼滤波器的等式为:
预测

使用Jacobians矩阵更新模型


更新

{kind=link}
预测
如同扩展卡尔曼滤波器(EKF)一样, UKF的预测过程可以独立于UKF的更新过程之外,与一个线性的(或者确实是扩展卡尔曼滤波器的)更新过程合并来使用;或者,UKF的预测过程与更新过程在上述中地位互换亦可。
[编辑]应用
[编辑]参见
- 快速卡尔曼滤波
- 比较: 维纳滤波及 the multimodal Particle
filter estimator.
[编辑]外部连接
- An Introduction
to the Kalman Filter, SIGGRAPH 2001 Course, Greg Welch and Gary Bishop - Kalman filtering chapter from Stochastic
Models, Estimation, by Peter Maybeck - Kalman Filter webpage, with lots of links
- Kalman Filtering
- The unscented Kalman
filter for nonlinear estimation - Kalman Filters, thorough introduction
to several types, together with applications to Robot Localization
[编辑]参考文献
- Gelb A., editor. Applied optimal estimation. MIT Press, 1974.
- Kalman, R. E. A New Approach to Linear Filtering and Prediction Problems, Transactions of the ASME - Journal of Basic Engineering Vol. 82: pp. 35-45 (1960)
- Kalman, R. E., Bucy R. S., New Results in Linear Filtering and Prediction Theory, Transactions of the ASME - Journal of Basic Engineering Vol. 83: pp. 95-107 (1961)
- [JU97] Julier, Simon J. and Jeffery K. Uhlmann. A New Extension of the Kalman Filter to nonlinear Systems. In The Proceedings of AeroSense: The 11th International Symposium on Aerospace/Defense Sensing,Simulation and Controls,
Multi Sensor Fusion, Tracking and Resource Management II, SPIE, 1997.
- Harvey, A.C. Forecasting, Structural Time Series Models and the Kalman Filter. Cambridge University Press, Cambridge, 1989.