词网格分词方法是基于统计的方法,它具有比较高的分词正确率,而且可以比较容易的进行扩展。可以通过加入相应的统计信息来扩展不同的功能。
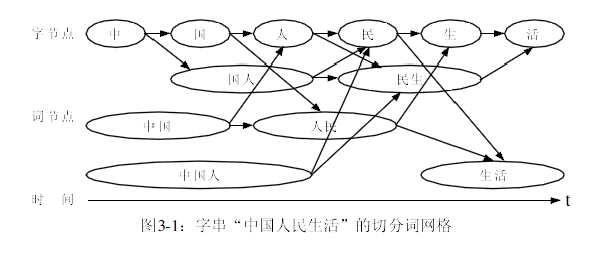
基于词网格分词的第一步是候选词网格构造:利用词典匹配,列举输入句子所有可能的切分词语,并以词网格形式保存。实际上,词网格是一个有向无环图(Directly Acyclic Graph, DAG),它蕴含了输入句子所有可能的切分,其中的每一条路径代表一种切分。图3-1表示的是字串“中国人民生活”的切分词网格,它包含了16种不同的切分情况。第二步计算词网格中的每一条路径的权值,权值通过计算图中每一个节点
(每一个词)的一元统计概率和节点之间的二元统计概率的相关信息。然后根据图搜索算法在图中找到一条权值最小的路径,对应的路径即为最后的分词结果。
出自《计算机自然语言处理》一书
导航页:本博客中中文分词索引页