SQLite的原子提交原理
2013/1/18版本:
之前的一个Android项目用到SQLite,有一个数据库损坏的问题一直搞不明白,老大推荐了一下这篇文章,看了之后明白不少。原英文地址中的一些内容有更新,我也就捡其中的一些自己看着比较吃力段落重新翻译了一下,顺便补充了一些英文版更新内容,很多地方并没有完全吃透,只是看了个大概,有些地方或许翻译有差错,欢迎指正。
距离原译者的时间近五年,2013/1/18凌晨于杭州,裹着被子,很冻手,敲键盘都不准,难免会有错别字。向原译者致敬!
以下是原译者的摘要:
摘要:
本文源自:http://www.sqlite.org/atomiccommit.html,2007/11/28的版本
本人正在做一个项目,在项目中定义了自己的文件格式,为了做到停电或程序崩溃不损坏这些文件原有的数据,故针对操作的原子性做一些思考,后来看到sqlite的这篇文章,与自己的实现方式作了一些对比。故顺手在研究此文章的时候将大意译成了中文。毕竟只是一时顺手之作,应该存在不少的误读与错误,请多多包涵,此文章的原始地址在http://chensheng.net/p/sqlite/auto_commit_zh_cn.html,本文可以转载,但请保留出处,以便他人能够方便找到我在修改此文可能的错误之后重新发布的版本。如果发现错误请发mail给我erehw#163.com。
本文描述了sqlite为保证数据库文件不被损坏而采取的种种手段,对于一些小型应用值得借鉴。其实在我看来,我自己实现这种方式似乎都有些不必要,也可以直接利用sqlite或者berkeley
db即可。
2008-1-29于杭州,时日江南一片暴雪,众多机场车站都处于凝滞状态。感谢众多在此次雪灾之中作出贡献的人们。
1.0 简介
“原子提交”是SQLite这种支持事务的数据库的一个重要特性。原子提交意味着某个事务中数据库的变化会完整完成或者根本不完成。原子提交意味着不同的写入分别写入到数据库的不同部分就似同时发生在同一个时间点一样。
实际上硬件会连续的写到海量存储器中,只是写一个扇区所用的时间非常少。所以,同时或瞬间写入到数据文件的不同部分成为可能。SQLite的原子提交逻辑会使得一个事务中的变化就象同时发生的一样。
事务的原子是SQLite的重要特性,即使事务由于操作系统出错或掉电发生中断也能保持其原子性。
本文描述了SQLite实现原子操作的技术。
2.0 硬件设定
在这往篇文章中,我们把海量存储特指定为“硬盘”,即使它可能是flash memory.
我们假定硬盘是以扇区为单位进行整块写入的。我们不能单独修改硬盘的小于扇区的部分。如果需要修改硬盘小于扇区的部分,你也必须整个读入此部分所在扇区,对此扇区进行修改,然后将整个扇区写回硬盘。
在传统的Spinning disk中,扇区是最小的传输单元---无论是读还是写。然而,对于flash memory,每次读的最小数目通常都远小于最小写操作数目。SQLite 只关心写操作的最小数目,因此在本文中,当我们说“扇区”的时候,就是指单次写入的最少字节总数。
SQLite 3.3.14以前的版本,我们假定任何情况下,一个扇区是512字节。这是一个编译时设定的值,而且从没针对更大数进行测试过。当磁盘驱动器内部使用的是以512字节为单位的扇区时,512字节的假定显得非常合理。然而,现在的磁盘都已经发展到4k每扇区了。同样, flash memory 的扇区大小通常都大于512字节。因此,从3.3.14版本开始,SQLite有一个函数去获取文件系统的扇区真实大小。在当前的实现中(3.5.0),这个函数仍然简单的返回512—因为在win32及unix环境下,没有标准方法去取得扇区的真实大小。但这个方法在人们需要针对他们应用进行调整的时候是非常有意义的。
SQLite并不假定扇区写操作是原子的。然而,我们假定扇区写操作是线性的。所谓“线性”是指,当开始扇区写操作时,硬件从前一个扇区的结束点开始,然后一字节一字节的写入,直到此扇区的结束点。这个写操作可能是从尾向头写,也可能是从头向尾写。如果在一个扇区写入操作时发生掉电故障,这个扇区可能会一部分已经修改完成,还有一部分还没来得及进行修改。SQLite的关键设定是这样的:如果一个扇区的任何部分发生修改,那么不是它开始的部分发了变化,就是它结束部分发生了变化。所以硬件从来都不会从一个扇区的中间部分开始写入。我们不知道这个假定是否总是真实的,但无论如何,看起来还是蛮合理的。
上段中,SQLite并没有假定扇区写操作是原子的。在SQLite3.5.0版本中,新增了一个VFS(虚拟文件系统)接口。SQLite通过VFS与实际的文件系统进行交互。SQLite已经为windows及unix编写了一个缺省的VFS实现。并且可以让用户在运行时实现一个自定义的VFS实现。VFS接口有一个方法叫:xDeviceCharacteristics.此方法读取实际的文件系统各种特性。xDeviceCharacteristics方法可以指明扇区写操作是原子的,如果确实指定扇区写是原子的,SQLite是不会放过这等好处的。但在windows及unix中,缺省xDeviceCharacteristics的实现并没有指明扇区写是原子的,所以这些优化通常会忽略掉了。
SQLite假定操作系统会对写进行缓冲,因此写入请求返回时,有可能数据还没有真实的写入到存储中。SQLite 同时还假定这种写操作会被操作系统记录。因此, SQLite需要在关键点做"flush" 或 "fsync" 函数调用。SQLite假定flush或fsync在数据没有真实的写入到硬盘之前是不会返回的。不幸的是,我们知道在一些windows及unix版本中,缺少flush或fsync的真正实现。这使得SQLite在写入一个提交发生掉电故障后数据文件得到损坏。然而,这不要紧,SQLite能够做一些测试或补救。SQLite假定操作系统会是广告中那样漂亮运行。如果这些都不是问题,那么剩下的只期望你家的电源不要间歇性的休息。
SQLite假定文件增长方式是指新分配的文件空间,刚分配的时候是随机内容,后来才被填入实际的数据。换而言之,文件先变大,然后再填充其内容。这是一悲观假定,因而SQLite不得不做一些额外的操作来防止因断电发生的破坏数据文件—发生在文件大小已经增大,而文件内容还没完全填入之间的掉电。VFS的xDeviceCharacteristics可以指明文件系统是否总是先写入数据然后才更变文件大小的。(这就是那个:SQLITE_IOCAP_SAFE_APPEND属性,如果你想查看代码的话)
当xDeviceCharacteristics方法指示了文件内容先写入然后才改变文件大小的话,SQLite会减少一些相当的数据保护及错误处理过程,这将大大减少一个提交磁盘IO操作。然而在当前的版本,windows及unix的VFS实现并没有这样假定。
SQLite假定文件删除从用户进程角度来讲是原子的。也就说当SQLite要求删除一个文件,也在这删除的过程中间,断电了,一旦电源恢复,只有下列二种情况之一分发生:文件仍然存在,所有内容都没有发生变化;或者文件已经被删除掉了。如果电源恢复之后,文件只发生了部分删除,或者部分内容发生了变化或清除,或者文件只是清空,那么数据库还有用才怪呢。
SQLite假定发现或修改由于宇宙射线,热噪声,量子波动,设备驱动bug等等其他可能所引发的错误,都由操作系统或硬件来完成。SQLite并不为此类问题增加任何数据冗余处理。SQLite假定在写入之后去读取所获得的数据,是与写入的数据完全一致的!
3.0 单个文件提交
我们着手观察SQLite在针对一个数据库文件时,为保证一个原子提交所采取的步骤。关于在多个数据库文件之间为防止电源故障损坏数据库及保证提交的原子性所采用的技术及具体的文件格式在下一节进行讨论。
3.1 初始状态
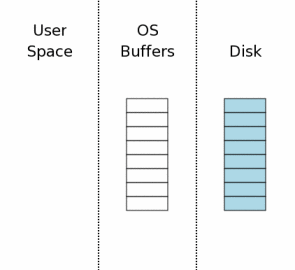
当一个数据库第一次打开时计算机的状态示意图如右图所示。图中最右边("Disk”标注)表示保存在存储设备中的内容。每个方框代表一个扇区。蓝色的块表示这个扇区保存了原始资料。图中中间区域是操作系统的磁盘缓冲区。在我们的案例开始的时候,这些缓存是还没有被使用—因此这些方框是空白的。图中左边区域显示SQLite用户进程的内存。因为这个数据库联接刚刚打开,所以还没有任何数据记录被读入,所以这些内存也是空的。
3.2 申请一个读锁
SQLite在可以写数据库之前,它必须先读这个数据库,看它是否已经存在了。即使只是增加添加新的数据,SQLite仍然必须从sqlite_master表中读取数据库格式,这样才知道如何分析INSERT语句,知道在哪儿保存新的信息。
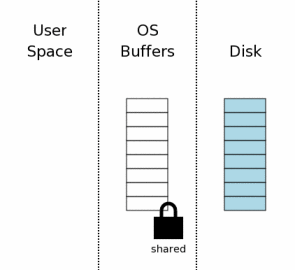
为了从数据库文件读取,第一步是获得一个数据库文件的共享锁。一个“共享”锁允许多个数据库联接在同一时刻从这个数据库文件中读取信息。“共享”锁将不允许其他联接针对此数据库进行写操作。这是必然的,如果一个联接在向数据库写入数据的同时,我们去读到信息,也可能读到的一部分数据是修改之前的,而另一部分数据是修改之后的。这将使得另外联接的修改操作看起来是非原子的。
请注意共享锁只是针对操作系统的磁盘缓存,并非磁盘本身。通常文件锁只是操作系统内核的一些标识(详情要根据具体的操作系统)。因此,一旦操作系统崩溃或者停电,锁会立即消失。当然创建该锁的进程消失,该锁也会随之而去。
3.3 从数据库里面读取信息
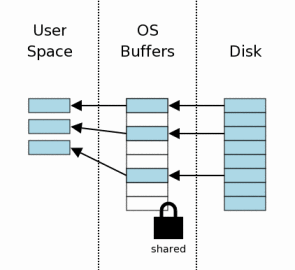
当共享锁取得之后,我们就可以开始从数据库文件中读取信息了。在当前环节,我们已经假定了系统缓存是空的,所以信息必须首先从硬盘读取到系统缓存中去,然后从系统缓存中传递到用户空间。针对之后的读取,部分或者全部数据都可能可以从操作系统缓存中取得,所以只需要传递到用户空间即可。
一般的,数据库文件只有部分被读取。这个例子中,8页中只有3页被读取。一个典型应用中,一个数据库文件拥有成千上万页,一个查询通常读取到的页码数量只占总数一个很小的百分比。
3.4 申请一个Reserved Lock
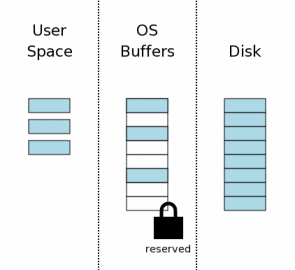
在修改一个数据库之前,SQLite首先得拥有一个针对数据库文件的“Reserved”锁。Reserved锁类似于共享锁,它们都允许其他数据库连接读取信息。单个Reserved
锁能够与其他进程的多个共享锁一起协作。然后一个数据库文件同时只能存在一个Reserved 。因此只能有一个进程在某一时刻尝试去写一个数据库文件。
Reserved 锁的存在是宣告一个进程将打算去更新数据库文件,但还没有开始。因为还没有开始修改,因此其他进程可以读取数据,但不应该去尝试修改该数据库。
3.5 生成一个回滚日志文件
在修改数据库文件之前,SQLite会生成一个单独的回滚日志文件,并在其中写进将被修改的页的原始数据。回滚日志文件意味它将包含了所有可以将数据库文件恢复到原始状态的数据。
回滚日志文件有一个小的头部(图中绿色标记部分)记录了数据库文件的原始大小。因此,如果一旦即使数据库文件变大,我们还是会知道它原始大小。数据库文件中被修改的页码及他们的内容都被写进了回滚日志文件中。
当一个新文件刚被创建,大部分的桌面操作系统(windows,linux,macOSX)实际并不会马上写入数据到硬盘。此文件还只是存在于操作系统磁盘缓存中。这个文件还不会立即写到存储设备中,一般都会有一些延迟,或者到操作系统相当空闲的时候。用户的对于文件生成感觉是要远远快(先)于其真实的发生磁盘I/O操作。右图中我们用图例说明了这一点,当新的回滚日志文件创建之后,它还只是出现在操作系统磁盘缓存之中,还没真实在写入到硬盘之上。
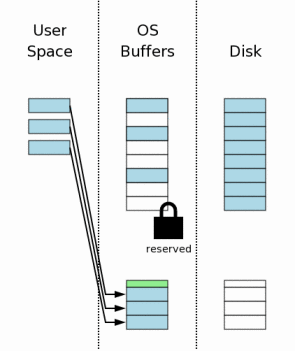
3.6 修改用户空间中的数据页
当原始的数据已经被保存到回滚日志文件中之后,用户内存的数据就可以被修改了。任何一个数据库联接都有其他私有用户内存空间,所以用户内存空间发生的变化只有当前数据库联接才可见。
其他数据库联接仍然可以读取那些存在于操作系统磁盘缓存中还没有被修改的数据。所以即使一个联接忙于某些修改,其他进程还可以读取原始数据到它们各自的空间中去。
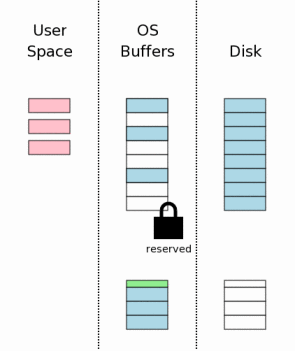
3.7 刷新回滚日志文件到存储设备中
接下来的步骤是将回滚日志文件刷新到硬盘中去。接下来我们会看到,这是一个紧要步骤用来保证我们可以从突然掉电中救回数据。这个步骤将要花费大量的时间—因为通常写入到硬盘是一个耗时操作。.
这个步骤通常要比简单的直接刷新这个回滚文件到硬盘要复杂一些。在大部分的操作系统中,二个单独的flush是必须的。第一个flush处理日志文件的内容部分。接下来,将日志文件的页码总数写入到日志文件头部,然后将日志头部flsuh到硬盘中。至少为什么我们要做一个头部修改及做一个额外的flush操作的原因我们会在后面的章节解释。
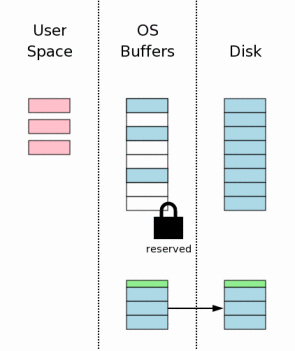
3.8 获得一个独享(Exclusive)锁
在修改数据库文件本身之前,我们必须取得一个针对此数据库文件的独享锁。取得此锁的过程是分二步走的。首先SQLite取得一个“临界”(Reserved)锁,然后将此锁提升成一个独享锁。
一个临界锁允许其他所有已经取得共享锁的进程从数据库文件中继续读取数据。但是它会阻止新的共享锁的生成。也就说,临界锁将会防止因大量连续的读操作而无法获得写入的机会。这些读取者可能有一打,也可能上百,甚至于上千。任何一个读取者在开始读取之前都要申请一个共享锁,然后开始读取它需要的数据,然后释放共享锁。然而存在这样一种可能:如果有太多的进程来读取同一个数据文件,在老的进程释放它的共享锁之前总是会有新的进程申请共享锁,因此不会存在某一时刻这个数据库文件上没有共享锁的存在,也因此写入者不会拥有取得一个独享锁的机会。临界锁的概念可以使现有的读取者完成他们的读取,同时阻止新的读取者读取,最后所有的读取者都读完之后,这个临界锁就可以被提升为独享锁了。
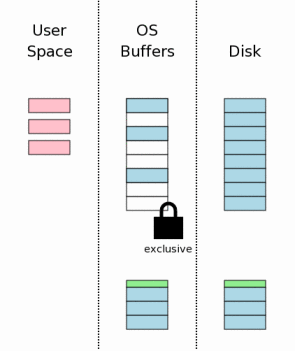
3.9 将变更写入到数据库文件中
一旦独享锁在手,我们知道再也没有其他进程在读取此数据库文件了,此时修改此文件是安全的了。通常,这些变更只会发生在操作系统磁盘缓存中,并不会全部写入到磁盘中去。
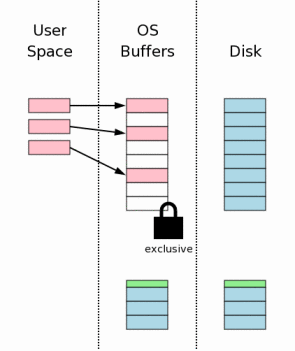
3.10 刷新变更到存储
一个附加的flush操作是必要的,这样才可以保证针对此文件的变化真正的写入到永久存储器中。这也是一个重要的步骤,将可以保证数据在掉电之后也将是完整无损的。然而,因为写入到磁盘所固有的慢,这个步骤同上面3.7节将日志文件flush到磁盘中一样,占据了SQLIite事务提交操作的绝大部分时间。
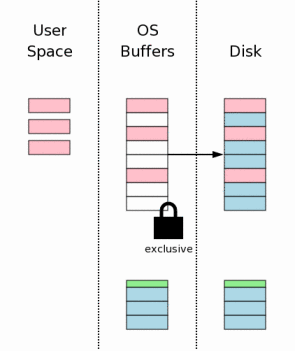
3.11 删除回滚日志文件
当数据变更已经安全的写入到硬盘之后,回滚日志文件就没有必要再存在了,因此立即删除之。如果在删除之前又掉电了或者系统崩溃了,恢复进程(在后面将会提到)会将日志文件的内容写回到数据库文件中—即使这个数据库没有发生变化。如果删除之后系统崩溃或者又停电了,看起来好象所有变化都已经写入到磁盘。因此,SQLite判断数据库文件是否完成了变更是依赖于回滚日志文件是否存在。
删除一个文件实际上不是一个原子操作,但从用户进程的角度来看,它是一个原子操作。一个进程总是可以向操作系统询问某个文件存在否,而它得到的答案只有“YES”和“NO”二种。在一个事务提交的中间,系统崩溃或又停了,之后,SQLite会向操作系统咨询回滚日志文件存在与否,如果存在,则这个事务是没有完成,被中断了,需要对数据库文件进行回滚。如果日志文件不存在,意味着事务已经提交ok了。.
事务存在的可能性依赖于是否有回滚日志文件。删除一个文件对于一个用户进程来说是原子性的。因此,整个事务看起来也是一个原子操作。.
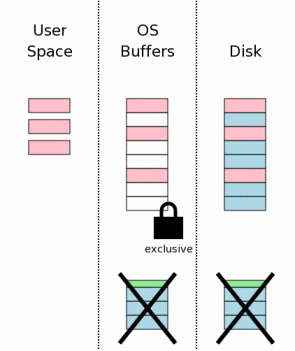
3.12 释放锁
事务提交最后一个步骤是释放独享锁,其他进程就又可以立即访问数据库文件了。
右图中,我们指明了当锁被释放的时候用户空间所拥有的信息已经被清空了.对于老版本的SQLite你可这么认为。但最新的SQLite会保存些用户空间的缓存不会被清空—万一下一个事务开始的时候,这些数据刚好可以用上呢。重新利用这些内存要比再次从操作系统磁盘缓存或者硬盘中读取要来得轻松与快捷得多,何乐而不为呢?在再次使用这些数据之前,我们必须先取得一个共享锁,同时我们还不得不去检查一下,保证还没有其他进程在我们拥有共享锁之前对数据库文件进行了修改。数据库文件的第一页中有一个计数器,数据库文件每做一次修改,这个计数器就会增长一下。我们可以通过检查这个计数器就可得知是否有其他进程修改过数据库文件。如果数据库文件已经被修改过了,那么用户内存空间的缓存就不得不清空,并重新读入。大多数情况下,这种情况不大会发生,因此用户空间的内存缓存将是有效的,这对于性能提高来说作用是显著的。
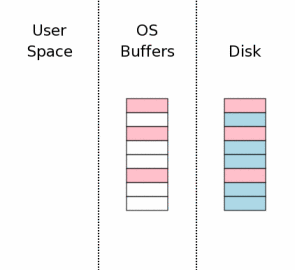
4.0 回滚
原子提交被设定是瞬间发生的。但上面的描述已经指出了其实这个过程是要花费不少时间的。如果在上面的提交过程中,计算机的电源被拉掉的情况下,为了保证变更是瞬间发生的事情,我们将“回滚”这些变化,将数据库文件恢复到事务开始之前的状态。
4.1 摊上事儿了!
假设掉电发生在上面3.10步骤中。电源恢复之后,当前的状态可能如右图所示。我们打算修改数据库文件中的三页但只有一页被成功写入,其他一页只部分写入,还有一页根本就没有写入。
这时,回滚日志文件是完整的。这是关键因素。上面3.7步骤做flush操作的理由是将任何变更写入到数据库文件之前要绝对保证回滚日志文件已经安全、完整的写入到了永久存储中。
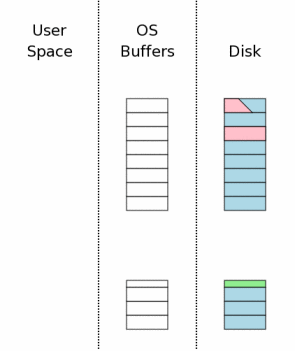
4.2 HotRollback Journals
上面3.2节已经描述了,所有SQLite进程尝试访问数据库文件之前,都得必须取得一个共享锁。但现在却被告知有一个回滚日志文件存在。SQLite会进行检查看这个日志文件是否是一个“hot journal”。A hot journal是指需要被用来进行处理以使数据库回复到健壮的初始状态的。hot journal的存在意味着早先的进程在一个事务中间发生了系统崩溃或掉电故障。
回滚日志是一个“hot” 的先天条件
l 回滚日志文件存在
l 回滚日志非空
l 这时数据库文件没有独享锁
l 回滚日志文件头部没有包括主日志文件的名字(5.5节)或者包含了主日志文件名称而且主日志文件存在
“hot”日志文件存在指明先前的进程尝试去提交一个事务,但由于种种原因在完成提交以前,事务被中止了。同时指明了数据库文件的状态是需要通过回滚来修复的,修复之后才可以被正常使用。
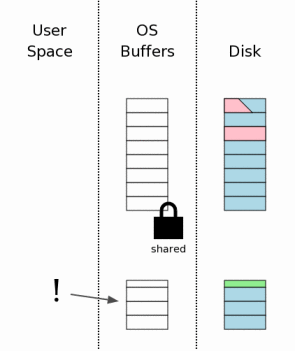
4.3 取得数据库的一个独享锁
为了处理“hot”日志文件首先是要取得一个数据库的独享锁。这将防止2个或多个进程在同一时刻来尝试回滚同一个“hot”日志文件。
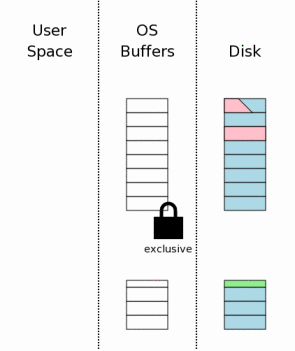
4.4 回滚没有完成的变更
一旦进程获得一个独享锁,它就被允许更新数据库文件。然后从日志文件中读取原始的内容,并写回到数据库文件中。是否还记得在这个被中止的事务的开始的时候,数据库文件原始大小已经被写进了日志文件的头部。SQLite使用这些信息来截断数据库文件,让文件恢复到原始大小—如果这个没有完成的事务使得数据库变大了。最后,数据库文件大小及内容肯定与这个被中断事务开始之前是一样的了。
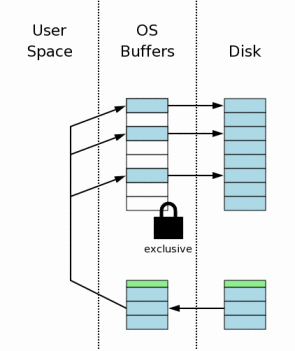
4.5 删除hot日志文件
当日志文件中的所有数据都被放回至数据库文件之后(并且做了flush),此日志文件就可以被删除了。
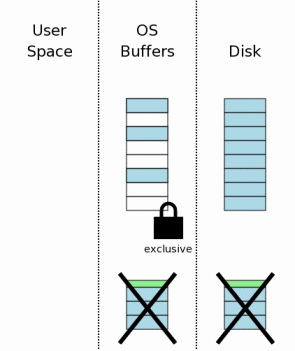
4.6 如果一切正常,没有什么未完成的写操作
恢复过程最后的步骤就是将独享锁降格成共享锁。一旦到了这里,数据库已经回到被中断事务开始的时状态。既然这个恢复操作已经完成,自动,自然而又透明,似乎被中断的事务从没有发生过一样!
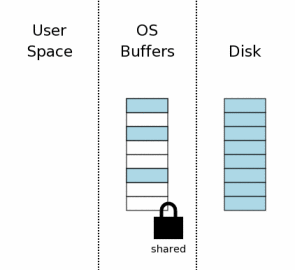
5.0 多文件提交
SQLite允许单个数据库联接通过使用ATTACH DATABASE命令同时与2个或多个数据库文件交互。在一个事务中,多个数据库文件被修改,所有文件的更新是原子性的。换而言之,要么所有文件被修改好了,要么什么也没有发生。针对多个文件的原子提交是要比仅针对单个文件的处理复杂一些。本节描述SQLite是如何完成这有魔术色彩的工作的。
5.1 每个数据库文件单独拥有日志文件
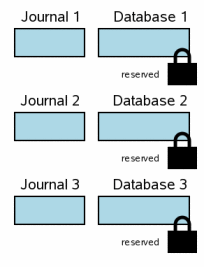
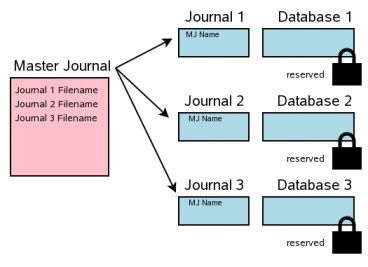
当一个事务涉及到多个数据库文件时,每个数据库文件都会有其相应的独立的回滚日志文件,并且每个数据库都是分别加锁的。下图显示了某个事务中修改了三个不同的数据库文件。这种情况与3.6步骤处理单个文件的事务还是有一些类似的。每个数据库文件有一个独享锁。针对每个数据库,要被修改页的原始内容被写入它们相应的回滚日志文件,但日志文件的内容还没有被flush到硬盘中。这时针对数据库的变更还没有发生,虽然有可能用户空间的数据已经发生了变化。
简单的说,下图已经简化了它们之前的状态。蓝色仍然指明是原始内容,而粉红是新的内容。但日志文件及数据库单独的页我们没有指示出来,同时我们也没有指明信息在操作系统磁盘缓存与硬盘中信息的差异。所有这些因素在一个多文件提交的场合下仍然起作用。这些因素会占据图中许多位置,但并没有增加新的信息,因此它们在此图中被省略掉了。
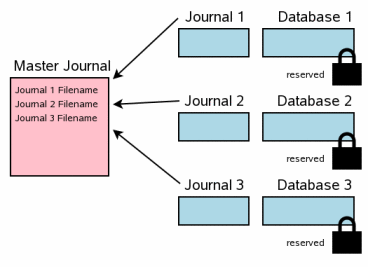
5.2 主日志文件
多文件提交的下一步是生成“主日志”文件。主日志文件的名称是与原始的数据库文件名 (数据库指的是用sqlite3_open的,而不是ATTACHed等辅助数据库),再加上文本"-mjHHHHHHHH"。附加的HHHHHHHH是一个随机32位16进数。每一个新的主日志文件会有一个变化的随机数HHHHHHHH后缀。
(注意:前面计算主日志文件名的算法是与SQLite3.5.0是一致的,但这不是SQLite规范的一部分,或许在新版本中发生变化)
不同于回滚日志文件,主日志文件并不包含任何数据库文件的页的原始内容。主日志文件包含了此事务所涉及的数据库的回滚日志文件的全路径。
当主日志文件已经创建完成之后,它会被立即flush到硬盘,这个操作早于任何其他操作。在unix下面,这个主日志文件所在目录也被同步到了硬盘,保证掉电以后主日志文件显示在此目录中。
5.3 更新回滚日志文件头
接下来在每一个回滚日志文件的头部需要记录主日志文件的全路径。当一个回滚日志文件被创建时,用来存储主日志文件名的空间已经被保留在每一个日志文件的开始部分。
在主日志文件名写入到日志名头部之前与之后都要进行一次Flush日志文件内容到硬盘。做二回flush很重要。幸运的是第二次的flush相对而言代价不是那么昂贵,因为一般的日志文件只有一页发生变化(第一页)
这一步与3.7节的单个文件事务提交场景类似。
5.4 修改数据库文件
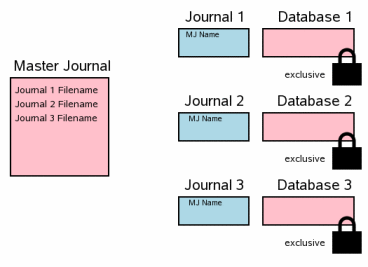
一旦所有的回滚日志文件已经flush到了硬盘中,就已经很安全的进行数据库文件更新了。我们在修改数据库文件之前必须得到所有数据库的独享锁。当所有的修改都完成的时候,flsuh数据库文件到硬盘是非常重要的。这将防止因系统崩溃或掉电而导致数据库损坏。
这个步骤与单个文件提交过程中3.8,3.9及3.10步骤是一致的。
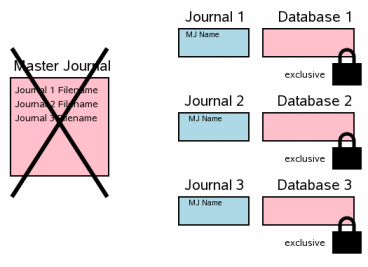
5.5 删除主日志文件
接下来的步骤是删除主日志文件。对于多文件事务提交,这是一个要点。这个步骤与上面3.11中单个文件的事务提交场景是相呼应的。
这时,如果发生系统崩溃或者又停电了,当系统重新运行的时候,即使回滚日志文件存在,这个事务不会被回滚。不同点在于回滚日志文件中主日志文件路径。当系统重启的时候,如果回滚日志文件没有主日志文件名(针对于单文件提交)或者主日志文件仍然存在的时候,SQLite才会将这些日志文件视为”hot”,并将回滚日志文件的内容放回到数据库文件中去。
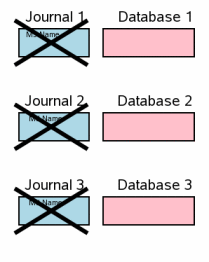
5.6 清除回滚日志
多文件事务提交的最后一步是删除单独的回滚日志文件,释放数据库文件的独享锁,其他进程就可以看到数据库的变化;这与上面3.12是相一致的。
这时事务已经提交完成了。所以删除日志的时间点并不是很紧急。当前的实现是删除某个回滚日志文件,并释放相应的数据库锁,然后处理另一个日志文件。以后有可能改为删除所有日志文件之后才释放所有的锁。日志文件删除只要是在其相对应的锁释放之前就没有任何问题。
6.0原子操作的一些实现细节
3.0节大致描述了SQLite中原子提交是如何工作的。但它略过了许多重要的细节。下面的这些部分将尝试补充说明这些地方。
6.1 总是记录整个扇区
当数据库文件的原始代码被写入到日志文件时(参见3.5节),SQLite总是写入完整的扇区,即使数据文件页大小是小于一个扇区。由于历史上的原因,SQLite的扇区大小原先是固定为512字节,此外由于最小的页大小是512字节,因此这从来都不是一个问题。自SQLite3.3.14版本以来,SQLite便有可能使用最小扇区大于512字节的海量存储设备。所以,自从3.3.14版本开始,只要一个扇区中的任何一页被写进到回滚日志文件中,那么同一扇区中的所有节都会写入到日志文件中去。
将扇区中的所有页都写入日志文件中去是很重要的,它将可以防止因为在写一个扇区时发生掉电故障而导致数据库损坏。假充页1,2,3,4都是保存扇区1中,页2被修改了。为了将这种变更写回到页2中,实际的硬件设备将也会同时重写页1,3及4的内容—这是因为硬件必须以扇区为单元作写操作。如果一个写操作正在进行的时候,由于电源的原因,发生了中断,这样,页1,3,4中会有1页或者多页数据是不完整,不正确的。因此为了防止这种损坏,数据库文件的同一扇区中的所有页都必须写入到日志文件中去。
6.2 写日志文件时垃圾的处理
当向一个日志文件追加数据时,SQLite总是悲观的假定文件会首先变大,变大的部分会填之一些无效的垃圾数据,在此之后正确的数据才会取代这些垃圾。换而言之,SQLite假定文件先改变大小,然后内容才会写进来。如果在文件大小增大之后,在内容还没有写完之前发生掉电故障,那么这些日志文件就会留下一些垃圾数据在其中。下次当电源恢复,另一个SQLite进程就会看到这些保存了垃圾数据的日志文件,并同时会把这些垃圾数据回滚到数据库文件中去,然后整个数据库就玩完了。
SQLite采用了两种预防措施。第一种,SQLite会在日志文件的头部记录下该日志文件中包含的页的数量。这个数量初始值是0。所以在尝试回滚一个不完整(或不正确)的回滚日志文件时,处理回滚的进程会看到该日志只包含0个页面,那么它就会不对数据库作任何改变。提交之后前,日志文件会被flush到硬盘中以确保所有的内容都同步到硬盘,同时没有任何垃圾内容留在其中,然后日志文件头部的页总数值才会置成真实有效的数据(原先数值是0)。日志文件的头部总是存放在区别于所有的页数据之外的独立扇区中,以此来保证它可被单独修改并且flush,即使发生掉电也不会危及数据页。请注意,日志文件会被flush两次:第一次写页数据,第二次是将页面数量写入到文件头部中。
前面的章节描述了当synchronouspragma设置成”full”发生的事情。
PRAGMAsynchronous=FULL;
缺省的synchronous设置是“full”,所以上面描述是通常会发生的情形。然而,如果synchronous设置成“normal”,那SQLite只会flush日志文件一次,就是在页面数量写入之后。这将意味着会有数据损坏的风险。因为有可能被修改的页面数量(非0)比所有的页数据更早一步写入到硬盘中。也数据的写入请求虽然会先被发起,但SQLite假定底层的文件系统可能会对写入请求重新排序,所以有可能页面数量会先写到磁盘中,即使是它的写请求是在最后。所以作为第二个预防手段,SQLite会为日志文件中的每一页数据使用一个32位的校验和,当回滚数据时(节4.4),这些值用来验证这些页是否有效。一旦发现有不正确的校验和时,那么就会放弃回滚。要注意的是,校验值并不确保页面数据百分百的正确,有极小的可能会出现即便数据错误校验和也是正确的。但使用校验和还是能使出错的可能性降到少之又少。
注意,如果synchronous设置成full时校验和不是必须的。只有当synchronous设置成normal时,我们才使用这些校验和。不过,这些校验和是没有坏处的,所以无论synchronous设是什么,它们都包括在日志文件里了。
6.3 提交前缓存溢出
节3.0描述的提交过程都假设所有的数据库变更在提交前都适合用户的内存大小。这是通常情况。但有时一个非常大的修改在事务提交前会超出用户空间的内存缓存大小。在这种情况下,事务完成之前,缓存必须先将数据先写入到数据库中。
在缓存溢出开始时,这个数据库联接的状态如3.6节提到的。原始的页数据已经被写入到回滚日志文件中了,修改的部分还保存在用户内存中。要处理这种缓存溢出,SQLite会执行3.7节到3.9节的内容。换言之,回滚日志被flush到硬盘,独享锁已经申请到,修改已经被写入到数据库了。但剩余的步骤会推迟到这个事务被真正提交。新的日志文件头会追加到回滚日志文件尾部(处于它自己单独的扇区中),独享锁仍然保留,但其他处理则回到3.6节.当这个事务提交时,或者另外的缓存溢出发生, 3.7节及3.9节会再次发生(3.8节在第二次或以后过程中被省略掉,因为独享锁已经拿到了)。
一次缓存溢会使数据库的临界锁提升为独享锁。这将减少并发。一次缓存溢出也会导致额外的硬盘flush(fsync)操作,这些操作比较慢,因此缓存溢出会严重降低性能。因此,应该尽可能的避免缓存溢出。
7.0 优化
性能分析显示,在大部分的操作系统和环境下面,SQLite主要耗时是在磁盘IO上面。如果我们能够减少磁盘IO数量就会显著的提高SQLite的性能。本节将描述SQLite在不影响提交原子性的前提下,为减少磁盘IO数量所采用的一些技术。
7.1 在事务间保存缓存
事务提交处理过程中,节3.12指出一旦共享锁被释放,用户空间所有的缓存的数据库内容镜像都必须得抛弃。这是因为如果没有一个共享锁,其他进程就可以随便修改数据库的内容,所以任何一块数据库数据在用户空间的缓存都可能会过期无效。因此,每一个新的事务会尝试去重新读取它以前读取过的数据。这并不像听起来这样糟糕,因为第一次读取过的数据还可能存在于操作系统的磁盘缓存中。所以这个读实际上只是一次数据从内核空间到用户空间的复制。但尽管这样,这还是需要占用cpu时间的。
自从SQLite3.3.14开始,新增了一个机制用来减少一些不必要的数据重复读取操作。最新的SQLite中,用户空间的页面缓存在用户锁释放之后仍然保留。之后,当要开始一个新事务,在取得一个共享锁之后,SQLite会尝试检查在此期间是否有进程对数据进行了修改。如果在锁释放这段时间,数据库发生过任何的变化,那么用户空间的缓存就会被释放。但通常情况下,数据文件是没有被修改过的,因此用户空间的缓存因而得到保留,一些不必要的读取操作从而得到了减免。
为了判断数据库文件是否被修改过,SQLite使用了一个计数器,存于数据库文件头部(处于字节24~27),每针对数据库做一次修改,就会对此值进行一回增长。SQLite会在释放一个锁之前记录一份这个值的。当下回取得锁之后,就会去与原先保存的值进行比较。如果值不一致,则必须清除这些缓存,反之缓存可以重新使用。
7.2 独享访问模式
SQLite从3.3.14版本之后增加一个“独享访问模式”概念。当处于独享访问模式时,SQLite会在一个事务完成之后仍然保留独享锁。这将阻止其他进程访问这个数据库;由于大部分的开发都只有一个进程访问数据库,所以大部分情况下这不是一个严重的问题。独享访问模式的好处可以在三个方面减少磁盘IO数量:
1) 不再需要在每个事务完成之后修改文件头部的变更计数器。这可以为回滚日志及数据库文件减少一次页写入。
2) 没有其他进程会修改数据库,所以不必在一个事务开始的时候去检查变更计数器或者清除掉用户空间的缓存。
3) 当一个事务完成之后,可以采用将日志文件头清零的方式,而不必去删除这个日志文件。这样就避免了修改日志文件的目录项,也不必释放日志文件对应的磁盘扇区。而且,下一个事务可以重写(overwrite)已有日志文件的内容,而不是在新的文件后追加新内容。在大多数的操作系统中,重写操作要远快于追加操作。
上述的第三点优化,将日志文件头清空而不是删除日志文件,不再依赖于一直持有一个独享锁。在理论上,我们可以在任何时刻做这项优化,并不是只有在独享访问模式时。This optimization can be set independently of exclusive lock modeusing the journal_mode
pragma asdescribed in section 7.6 below.
7.3 不必将空闲页写进日志
SQLite数据库的信息被删除之后,这些被删除的数据所使用的页会被加入到空页链表之中。后来的插入操作会尽量先使用空页链表中的页。
一些空白页包含紧要数据:特别是其他空百页的位置。但是大多数的空白页并不包含有用信息。这类页被称之为“叶子”页。我们可以随意修改这些叶子页的内容而不会影响数据库。
因为叶子页的内容是不重要的,SQLite避免保存这些叶子页的内容到回滚日志文件中去(3.5节)。如果一个叶子页的内容被修改了,那么在事务恢复过程中这些针对叶子页的修改并不会回滚。这不会对数据库产生伤害。同样的,新的空页链表的内容也从不会在节3.9中写回到到数据库,也不会在节3.3从数据库读入。当针对数据库文件的变化包含有空白页时,这种优化可以大量的减少磁盘io操作总数
7.4 单页更新及扇区原子写
从3.5.0开始,新的VFS接口包含了一个新的方法:xDeviceCharacteristics ,它能够读取实际的文件系统可能有的特性。xDeviceCharacteristics会报告是否文件系统能够支持扇区写原子操作。
回想前面,在一般情况下SQLite假定扇区写是线性的,但是非原子的。线性写从另一个扇区结束点开始一字节一字节进行修改,直到扇区的结束点。如果在写一个扇区时,线性写会将修改一个扇区的一部分,而另一部分是没有变动的。在一个扇区原子写的情况下,要么整个扇区被重写了,要么扇区没有发生变化。
我们相信大部分现代磁盘驱动器实现了原子写操作。当停电发生时,磁盘驱动器可以利用电容中的电能,同时(或者)利用盘片旋转的角动量来完成正在进行中的任何操作。然而,在系统写调用与磁盘电子器材之间,存在有太多的层次。因此在unix及win32上面的VFS实现比较安全的选择是,我们假定扇区写操作是非原子性的。On the otherhand, device manufactures with more control over their filesystems might wantto
consider enabling the atomic write property of xDeviceCharacteristics iftheir hardware really does do atomic writes.
当一个扇区写是原子性的,并且扇区大小与页大小是相同,并且一次数据库的变化只是某一个单独的页发生变化时,SQLite会跳过整个日志记录过程,直接简单地将被修改过的数据写回到数据库文件。数据库首页中的变更计数器将会被独立进行修改—因为不会对数据库产生任何影响—即使在计数器更新以前发生停电。.
7.5 FilesystemsWith Safe Append Semantics
SQLite3.5.0中介绍的另一个优化是利用实际磁盘的“安全追加”行为。回想上面,SQLite假定为一个文件追加数据时(特别是针对回滚日志文件),会先增大文件的大小,之后才会把数据内容写入。所以在文件的大小已经变化,而内容还没有写完的情况下发生掉电,那么文件新增部分将会有一些无效的垃圾数据。VFS的xDeviceCharacteristics可以用来指示文件系统是否实现了“安全追加”语义。这意味着在文件大小变大之前会先写入文件内容。这就防止当系统崩溃或掉电后,垃圾数据出现在回滚日志文件中
当文件系统有安全追加特性时,SQLite总是保存一个特别的值:-1来标明日志文件中页总数。页面数量为-1告诉任何尝试进行回滚操作程序页面数量需要从日志文件大小计算得来。同时,这-1值会从不进行修改。所以,在一个提交过程中,我们节省一个flsuh操作及日志文件首页的扇区写入操作。此外,当发生缓存溢出时,也不必要在日志文件后面增加一个新的日志头。我们能够简单的在一个现有的日志文件中添加一些新的页。
7.6持续的回滚日志
在许多系统中删除文件都是一个昂贵的操作。因此作为一个优化方案,SQLite可以通过配置避免3.11节中涉及到的删除操作。在事务提交时,通过将日志文件的文件头长度截为0或是用0重写文件头内容的方法来代替删除日志文件。将长度截为0的做法节省了必须要对文件的所在目录做的修改(因为文件依旧存在于这个目录中)。重写文件头的方案还有另外一个好处,不必更新文件(许多系统中的i节点)的长度,而且不需要处理新释放的磁盘扇区。更进一步讲,下一个事务的日志文件是通过重写已有内容而产生,而不是在文件末尾追加新内容,并且重写操作通常是要比追加操作更快的。
SQLite可以通过将日志模式设置为“PERSIST”使提交事务时使用用0重写日志文件头的方式来代替删除日志文件。例如:
PRAGMA journal_mode=PERSIST;
在很多系统中,使用持续的日志模式会带来显著的性能提升。当然,缺点就是事务提交很久以后,日志文件还会留在磁盘上,占用磁盘空间,导致目录杂乱。删除持续日志文件唯一安全的方法就是提交事务时将日志模式设置为DELETE:
PRAGMA journal_mode=DELETE;
BEGIN EXCLUSIVE;
COMMIT;
注意:因为日志文件可能依然在用(hot),如果使用其它途径删除持续日志文件会导致对应的数据库文件损坏。
从SQLite 3.6.4开始支持 TRUNCATE 日志模式:
PRAGMA journal_mode=TRUNCATE;
截断(truncate)日志模式中,事务提交时将日志文件长度置为0,而不是DELETE模式中的删除文件或是PERSIST模式中的清零文件头。 TRUNCATE模式也有PERSIST模式中不需要更新日志文件和数据库所在目录的好处。因此,截断一个文件通常比删除它要快。TRUNCATE还有一个好处就是它后面不跟系统调用(比如:fsync())来将更新同步回磁盘,当然如果做了会更安全。但是在很多现代的文件系统中,截断操作是原子的同步操作,并且我们认为在遇到断电情况时,截断操作也是安全的。如果你不确定截断操作在你的文件系统上的同步性和原子性,并且断电或宕机时的数据库安全对你很重要,那你应该考虑使用其他的日志模式。
在具有同步文件系统的嵌入式操作系统中,TRUNCATE会导致比PERSIST较慢的行为。提交操作的速度是相同的,但是TRUNCATE操作之后的事务会慢一些,因为重写已存在的内容比在文件尾追加新内容要快。TRUCATE之后新的日志文件总是使用追加操作,而PERSIST则是使用重写操作。
8.0 原子提交行为测试
SQLite的开发者对SQLite在面对电源故障及系统崩溃时所拥有健壮性具有足够的自信。因为自动化的测试过程做了大量的面对模拟的电源故障的SQLite恢复能力测试。我们称之为“崩溃测试”。
SQLite的崩溃测试是使用一个修改过的VFS,它能够模拟种种发生掉电或系统崩溃时文件系统发生的损坏。崩溃测试用的VFS能够模拟未完成的扇区写操作,未完成的写操作造成的页面垃圾,还有无序写操作,一个测试场景中各种种各样的变化。崩溃测试不停地执行事务,让模拟的掉电或系统崩溃发生在不同的各种时刻,造成不同的数据损坏。在模拟的事件之后,任何一次测试重新打开数据库之后,会检测事务是否完成或者没有完成,数据库状态是否正常。
SQLite的这些崩溃测试发现恢复机制的大量细微的BUG(现在都已经修复了)。其中一些BUG是非常模糊的,如果只是单单观察、分析代码所不能发现的。通通过这试验,SQLite的开发者感觉很自信,因为其他的数据库没有采用类似的崩溃测试,很可能他们都包含一些没有被检测出的bug,在一次掉电或者系统崩溃之后会导致数据库损坏。
9.0 会导致完蛋的事情
SQLite的原子提交机制已经被证明是健壮的。但它也可能被一些不完整的操作系统实现所陷害。本节描述一些会在掉电或系统崩溃下会导致SQLite数据损坏的情形
9.1 缺乏文件锁实现
SQLite通过文件系统的锁来实现在同一时刻只有一个进程及一个数据库联接能够修改数据库。文件锁机制由VFS层实现,不同的操作系统具有不同的实现方式。SQLite依赖于这种实现的正确性。如果在某种情况下,二个或更多进程能够在同一时间写同一个数据库文件,这将会没有什么好果子吃的。
我们已经接收到报告说windows的网络文件系统及NFS的锁存在一些微妙的缺陷。我们不能验证这些报告。但是因为网络文件系统本身实现锁很困难,所以我们没有理由怀疑这些报告。首先,既然性能不足,建议你不要在网络文件系统中使用SQLite。但是如果你不得不使用一个网络文件来保存SQLite的数据文件,那们考虑采用其他的锁机制来防止本身的文件锁机制出错时发生多个进程同时写一个数据文件的现象。
苹果MacOSX预装的SQLite版本已经扩展拥有一种可供选择的锁策略可以工作在苹果支持的所有网络文件系统上。这些苹果使用的扩展在多个进程在同时访问数据库文件时工作得很好。不幸的是,这些锁机制并不互相排斥,如果一个进程使用AFP锁去访问文件,而另一个进程(或许是另一台机器)使用dot-file锁去访问这个文件,那么这二个进程可能发生冲突,因为AFP锁并不排斥dot-file锁,反之亦然。
9.2 不完整的磁盘刷新
SQLite 在unix使fsysnc,在win32下面使用FlushFileBuffers,用来将文件内容同步到磁盘中(节3.7及节3.10)。不幸的是,我们也收到报告,在许多平台上,这二者都没有象广告中宣称的那样工作。我们听说FlushFileBuffersc在一些windows版本中,可以通过修改注册表,能够完全禁止其工作。我们也被告之,Linux的一些早先版本,他们的一些文件系统中的fsync完全是一个空操作。即使是FlushFileBuffers及fsync被告之可以工作的系统中,IDE硬盘经常会撒谎说数据已经写入到盘片中,其实还只是存在状态可变的磁盘控制器缓存中。
在Mac你可设置下面项:
PRAGMA fullfsync=ON;
在Mac上设置fullfsync能够保证数据通过flush会真实的写入到盘片中。但fullfsync会导致磁盘控制进行重设。这并不是一般意义上的慢,它还会导致其他磁盘IO降速,所以此项配置并不推荐。
9.3 文件部分地删除
SQLite假设从用户进程角度来看是一个原子操作。当删除过程中发生掉电,当电源恢复之后,SQLite希望看到文件要么完整的存在,要么根本找不到了。如果操作系统不能做到这一点,那事务就可能不是原子性的了。
9.4 写入到文件中的垃圾
SQLite的数据文件是一种普通的磁盘文件,可以由普通用户进行读写。一些流氓进程可能会打开一个SQLite文件,并在其中写入一些混乱的数据。混乱的数据也可能由于操作系统的BUG而写入到一个SQLite的数据文件中。对于这些情况,SQLite无能为力。
9.5 删除掉或更名了“hot”日志文件
如果掉电或系统崩溃导致留下了一个”hot”日志文件在磁盘上。实际上,原来的数据文件再加上留下来的“hot“日志文件, 是SQLite下回打开时发生回滚使用的,这可以恢复SQLite数据的正常状态(节4.2)。SQLite会在数据库所在同一目录下用打开的文件名来寻找可能存在的”hot”日志文件。如果数据文件或者日志文件被移动或者改名,或者删除掉了,那么这些日志文件将不会被回滚,数据库也就可能损坏,无法使用了。
我们常怀疑SQLite发生的恢复失败的例子是这样的:停电了,之后电又恢复了。一个好心的用户或者系统管理管理员开始查看磁盘损坏。他们看到名为"important.data"数据库文件,或许类似的文件。但由于停电,这里也同样有一个日志文件名为"important.data-journal".这个用户删除了这个“hot”日志文件,认为他是清理系统。那于这种情况,除了进行用户培训,没有其他办法。
如果有多个联接(硬或者符号联接)指向一个数据文件,这个日志文件会以被打开的联接文件名相关来创建的。如果系统崩溃之后,数据库以一个新的联接重新打开,这个“hot”日志文件就不会被找到,数据也不会发生回滚。
有时,电源问题会导致文件系统出现毛病,如最新修改的文件名被丢失了,并会转移至类似于"/lost+found"这样的目录中。当这种情况发生的时候,这个hot日志文件就不会被找到,同样恢复也不会发生。SQLite在同步一个日志文件时通过打开并同步日志文件所在目录来尝试阻止这类事件发生。然后,转移文件到"/lost+found"可能会由不相关的其他进程在相同的目录中产生与主数据库文件名相同的不相关文件。既然这都是SQLite所无法控制,所以SQLite没有什么好办法。如果你运行在一种易导致名称空间冲突的文件系统上,那么你最好把每一个SQLite的数据文件放在你私有的子目录中。
10.0 总结及未来的路
即使到了现在,还是有人发现了一些关于原子提交机制失败模式,开发者不得不为此做一些补丁。这样的事情发生得越来越少了,失败模型也变得越来越模糊了。但如果就认为SQLite的原子提交逻辑是没有任何bug,那是相当愚昧的。开发者承诺将尽可能快的修复被发现的bug。
开发者同时在考虑新的优化提交机制的办法。当前的linux,macOSX,win32的VFS实现使用这些系统之上的一些悲观设定。或许在与一些了解这些系统如何工作的专家交流之后,我们或许可能放松一些这些系统上的设定,使其跑得更快些。特别的,我们怀疑的大部分现代文件系统现在已经展现安全追加特性,或许他们都已经支持了扇区的原子操作。但是除非这些得到明确,SQLite仍将采用更安全、保守的方法,作最坏的打算。