上周四,增加了一组redo log,下了alter system switch logfile之后,数据库突然down掉。察看日志,发现如下错误:
Errors in file f:"lczhis"dump"bdump"lczhis_arc0_2468.trc:
ORA-19504: failed to create file "F:"LCZHIS"ARCHIVE"ARC001_055776657082840.ARC"
ORA-27040: file create error, unable to create file
OSD-04001: invalid logical block size (OS 512)
ARC0: Error 19504 Creating archive log file to 'F:"LCZHIS"ARCHIVE"ARC001_055776657082840.ARC'
ARCH: Archival stopped, error occurred. Will continue retrying
Thu Oct 16 17:38:26 2008
Errors in file f:"lczhis"dump"bdump"lczhis_arc0_2468.trc:
ORA-16038: log 2 sequence# 282840 cannot be archived
ORA-19504: failed to create file ""
ORA-00312: online log 2 thread 1: 'E:"REDO"REDO02.LOG'
Thu Oct 16 17:38:30 2008
Errors in file f:"lczhis"dump"bdump"lczhis_lgwr_2384.trc:
ORA-00366: log 1 of thread 1, checksum error in the file header
ORA-00312: online log 1 thread 1: 'F:"LCZHIS"REDO"REDO01.LOG'
我试图startup database,结果失败,报如下错误
ALTER DATABASE OPEN
Thu Oct 16 17:39:11 2008
Beginning crash recovery of 1 threads
parallel recovery started with 3 processes
Thu Oct 16 17:39:11 2008
Started redo scan
Thu Oct 16 17:39:11 2008
Errors in file f:"lczhis"dump"udump"lczhis_ora_880.trc:
ORA-00366: log 1 of thread 1, checksum error in the file header
ORA-00312: online log 1 thread 1: 'F:"LCZHIS"REDO"REDO01.LOG'
察看数据库,发现是当前日志。
然后就使出18班武艺,比如:
SQL〉startup mount
SQL〉alter database clear logfile group 1;
SQL> alter database clear unarchived logfile group 1;
SQL> recover database using backup controlfile until cancel;
SQL> alter session set events '10015 trace name adjust_scn level 1';
SQL> alter database open resetlogs;
甚至隐含参数
_allow_resetlogs_corruption=true
_corrupted_rollback_segments=true
_offline_rollback_segments=true
均以失败告终,报如下错误类似:
Media Recovery Log F:"LCZHIS"ARCHIVE"ARC001_055776657082841.ARC
Errors with log F:"LCZHIS"ARCHIVE"ARC001_055776657082841.ARC
ORA-308 signalled during: ALTER DATABASE RECOVER CONTINUE DEFAULT ...
Thu Oct 16 22:34:05 2008
ALTER DATABASE RECOVER CONTINUE DEFAULT
ARCH: Warning. Log sequence in archive filename wrapped
to fix length as indicated by %S in LOG_ARCHIVE_FORMAT.
Old log archive with same name might be overwritten.
Thu Oct 16 22:34:05 2008
Media Recovery Log F:"LCZHIS"ARCHIVE"ARC001_055776657082841.ARC
Errors with log F:"LCZHIS"ARCHIVE"ARC001_055776657082841.ARC
ORA-308 signalled during: ALTER DATABASE RECOVER CONTINUE DEFAULT ...
Thu Oct 16 22:34:05 2008
ALTER DATABASE RECOVER CANCEL
ORA-1547 signalled during: ALTER DATABASE RECOVER CANCEL ...
Thu Oct 16 22:34:44 2008
ALTER DATABASE RECOVER database until cancel
Thu Oct 16 22:34:44 2008
Media Recovery Start
parallel recovery started with 3 processes
Thu Oct 16 22:34:56 2008
ARCH: Warning. Log sequence in archive filename wrapped
to fix length as indicated by %S in LOG_ARCHIVE_FORMAT.
Old log archive with same name might be overwritten.
ORA-279 signalled during: ALTER DATABASE RECOVER database until cancel ...
Thu Oct 16 22:35:36 2008
ALTER DATABASE RECOVER LOGFILE 'F:"lczhis"redo"redo01.log'
Thu Oct 16 22:35:36 2008
Media Recovery Log F:"lczhis"redo"redo01.log
Thu Oct 16 22:35:36 2008
Errors in file f:"lczhis"dump"udump"lczhis_ora_1860.trc:
ORA-00367: checksum error in log file header
ORA-00334: archived log: 'F:"LCZHIS"REDO"REDO01.LOG'
Errors with log F:"lczhis"redo"redo01.log
ORA-367 signalled during: ALTER DATABASE RECOVER LOGFILE 'F:"lczhis"redo"redo01.log' ...
Thu Oct 16 22:35:36 2008
ALTER DATABASE RECOVER CANCEL
ORA-1547 signalled during: ALTER DATABASE RECOVER CANCEL ...
Thu Oct 16 22:36:46 2008
周五晚上失眠,本打算switch logfile之后再备份的,这下可好,8年的资料呀,网上可用的方法试个边,均失败。按说当前日志损坏应该不难,怎么就这么个结果呢。打电话给沈阳的一位专家,计划用最后一根稻草—dul。
突然想到一个问题,之前在上这套san时,好像当LUN超过2T时,在LUN上建库会失败,其原因是redo log 无法建立,是否是这个原因呢?记得当时已经找盘阵原厂解决了这个问题。
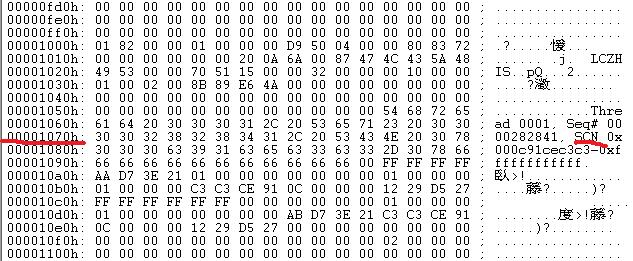
用UltraEdit打开损坏的redo log 1及其他库完好的redo log,发现问题所在,
图一
图二
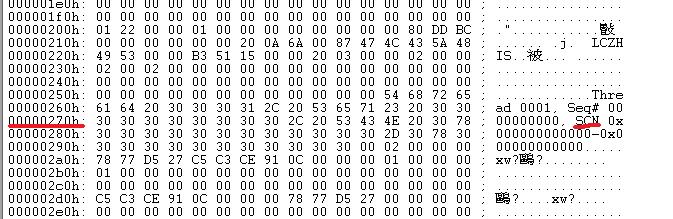
SCN的存储地址不同,我检查了好几台库的log,发现正常的都是图二的样子,这说明,我在这个盘阵上修复库失败的原因,不是方法不对,而是盘阵无法建立正常的redo log及archive log。
赶快让负责SAN的同事,将一个未超过两T的LUN划给我这台数据库,然后将所有数据库复制到新的LUN上,修改盘符,将原来的F盘改为D,而将新的LUN改为F,然后再用以上武艺,仍然失败,1.3T的数据,COPY了整整一天才完,结果失败,是否我真要用DUL了?
我复制的是在发现数据库down 掉之后我备份的那份,不死心,决定将原库直接复制过来,再试一次,过程如下:
1. 复制Down掉的原库所有文件到新的LUN
2. 删掉所有日志文件
3. SQL〉startup mount
4. SQL〉recover database using backup controlfile until cancel;
5. SQL〉cancel
6. SQL> alter database open resetlogs;
数据库竟然open了,真是太兴奋了。
至于第一次用新LUN失败的原因,估计是当时备份的数据库文件有误。
备份重于一切。
如果预算允许,尽量买大厂出的盘阵,那些便宜货,经过的测试少,真是害人。