https://github.com/nathanmarz/storm/wiki/Transactional-topologies
http://xumingming.sinaapp.com/736/twitter-storm-transactional-topolgoy/
Storm guarantees data processing by providing an at least once processing guarantee. The most common question asked about Storm is "Given that tuples can be replayed, how do you do things like counting on top of Storm? Won't you overcount?"
Storm 0.7.0 introduces transactional topologies, which enable you to get exactly once messaging semantics for pretty much any computation. So you can do things like counting in a fully-accurate, scalable, and fault-tolerant way.
Storm默认的reliable特性支持at least once processing guarantee.
这个在某些场景下明显是不够的, 比如计数, 不断的replay必然导致计数不准, 那么需要支持exactly once semantics.
Storm 0.7就提供transactional topology特性来支持, 其实这个和DRPC一样, Storm只是提供一种特殊的topology的封装, 当然transactional topology更复杂.
Design
Design 1
这里说transactional topologies为了提供strong ordering, 这个要求是要强于之前说的exactly once semantics.
对于每个transaction有唯一的transaction id来标识, 对于第一种design, 每个transaction就是一个tuple
拿计数作为例子, 每个tuple产生的number, 最终需要累加到数据库里面
不使用transactional, 重复replay一个tuple, 必然会导致该tuple的number被反复累加到数据库
怎么处理? 其实想法很简单, 引入transaction的概念, 并在累加number到数据库的同时记下该transactioin id.
这样如果replay该tuple, 只需要对比transaction id就知道该transaction已经累加过, 可以直接ignore
看到这里, 就知道保持strong ordering的重要性, 强顺序意味着, 如果当前的transaction失败, 会反复被replay, 直到成功才继续下一个transaction.
这意味着, 在数据库我们只需要记录latest的transaction id, 而不是累加过的所有transaction id, 实现上会简单许多.
但是design1的问题是效率太低, 完全线性的处理tuple, 无法利用storm的并发能力, 而且数据库的负载很高, 每个tuple都需要去操作数据库
The core idea behind transactional topologies is to provide a strong ordering on the processing of data.
The simplest manifestation of this, and the first design we'll look at, is processing the tuples one at a time and not moving on to the next tuple until the current tuple has been successfully processed by the topology.
Each tuple is associated with a transaction id. If the tuple fails and needs to be replayed, then it is emitted with the exact same transaction id. A transaction id is an integer that increments for every tuple, so the first tuple will have transaction id 1, the second id 2, and so on.
There is a significant problem though with this design of processing one tuple at time. Having to wait for each tuple to be completely processed before moving on to the next one is horribly inefficient. It entails a huge amount of database calls (at least one per tuple), and this design makes very little use of the parallelization capabilities of Storm. So it isn't very scalable.
Design 2
Design2的想法很简单, 用batch tuple来作为transaction的单位, 而不是一个tuple.
这样带来的好处是, batch内部的tuple可以实现并行, 并且以batch为单位去更新数据库, 大大减少数据库负载.
但本质上和Design1没有区别, batch之间仍然是串行的, 所以效率仍然比较低
Instead of processing one tuple at a time, a better approach is to process a batch of tuples for each transaction.
So if you're doing a global count, you would increment the count by the number of tuples in the entire batch. If a batch fails, you replay the exact batch that failed.
Instead of assigning a transaction id to each tuple, you assign a transaction id to each batch, and the processing of the batches is strongly ordered. Here's a diagram of this design:

Design 3 (Storm's design)
这个设计体现出storm的创意, 将topology的过程分为processing和commit, processing就是进行局部的计算和统计, 只有commit时才会把计算的结果更新到全局数据集(数据库)
那么对于processing阶段完全没有必要限制, 只要保证在commit的时候按照顺序一个个commit就ok.
比如对于计数, 不同的batch的局部计数过程没有任何限制, 可以完全并行的完成, 但是当需要将计数结果累加到数据库的时候, 就需要用transaction来保证只被累加一次
processing和commit阶段合称为transaction, 任何阶段的失败都会replay整个transaction
A key realization is that not all the work for processing batches of tuples needs to be strongly ordered. For example, when computing a global count, there's two parts to the computation:
- Computing the partial count for the batch
- Updating the global count in the database with the partial count
The computation of #2 needs to be strongly ordered across the batches, but there's no reason you shouldn't be able to pipeline the computation of the batches by computing #1 for many batches in parallel. So while batch 1 is working on updating the database, batches 2 through 10 can compute their partial counts.
Storm accomplishes this distinction by breaking the computation of a batch into two phases:
- The processing phase: this is the phase that can be done in parallel for many batches
- The commit phase: The commit phases for batches are strongly ordered. So the commit for batch 2 is not done until the commit for batch 1 has been successful.
The two phases together are called a "transaction".
Many batches can be in the processing phase at a given moment, but only one batch can be in the commit phase.
If there's any failure in the processing or commit phase for a batch, the entire transaction is replayed (both phases).
Design details
为了实现上面的Design3, storm在transactional topologies里面默默的做了很多事
管理状态, 通过Zookeeper去记录所有transaction相关的状态信息
协调transactions, 决定应该执行那个transaction的那个阶段
Fault检测, 使用storm acker机制来detect batch是否被成功执行, 并且storm在transactional topology上对acker机制做了比较大的优化, 用户不用自己去acking或anchoring, 方便许多
提供batch bolt接口, 在bolt接口中提高对batch的支持, 比如提供finishbatch接口
最后, transactional topology要求source queue具有replay an exact batch的能力, 这儿说kafka是很好的选择
不过我很好奇, 为什么要由source queue来提供batch replay的功能, 好的设计应该是batch对source queue透明, spout自身控制batch的划分和replay, 这样不可以吗?
When using transactional topologies, Storm does the following for you:
- Manages state: Storm stores in Zookeeper all the state necessary to do transactional topologies.
This includes the current transaction id as well as the metadata defining the parameters for each batch. - Coordinates the transactions: Storm will manage everything necessary to determine which transactions should be processing or committing at any point.
- Fault detection: Storm leverages the acking framework to efficiently determine when a batch has successfully processed, successfully committed, or failed.
Storm will then replay batches appropriately. You don't have to do any acking or anchoring -- Storm manages all of this for you. - First class batch processing API: Storm layers an API on top of regular bolts to allow for batch processing of tuples.
Storm manages all the coordination for determining when a task has received all the tuples for that particular transaction.
Storm will also take care of cleaning up any accumulated state for each transaction (like the partial counts).
Finally, another thing to note is that transactional topologies require a source queue that can replay an exact batch of messages. Technologies like Kestrel can't do this. Apache Kafka is a perfect fit for this kind of spout, and storm-kafka in storm-contrib contains a transactional spout implementation for Kafka.
The basics through example
You build transactional topologies by using TransactionalTopologyBuilder. Here's the transactional topology definition for a topology that computes the global count of tuples from the input stream. This code comes from TransactionalGlobalCount in storm-starter.
MemoryTransactionalSpout spout = new MemoryTransactionalSpout(DATA, new Fields("word"), PARTITION_TAKE_PER_BATCH); TransactionalTopologyBuilder builder = new TransactionalTopologyBuilder("global-count", "spout", spout, 3); builder.setBolt("partial-count", new BatchCount(), 5) .shuffleGrouping("spout"); builder.setBolt("sum", new UpdateGlobalCount()) .globalGrouping("partial-count");
首先需要使用TransactionalSpout, MemoryTransactionalSpout被用来从一个内存变量里面读取数据(DATA), 第二个参数制定数据的fields, 第三个参数指定每个batch的最大tuple数量
接着, 需要使用TransactionalTopologyBuilder, 其他和普通的topology看上去没有不同, storm的封装做的很好
下面通过processing和commit阶段的bolt来了解对batch和transaction的支持
首先看看BatchCount, processing阶段的bolt, 用于统计局部的tuple数目
public static class BatchCount extends BaseBatchBolt { Object _id; BatchOutputCollector _collector; int _count = 0; @Override public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, Object id) { _collector = collector; _id = id; } @Override public void execute(Tuple tuple) { _count++; } @Override public void finishBatch() { _collector.emit(new Values(_id, _count)); } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("id", "count")); } }
BatchCount继承自BaseBatchBolt, 表明其对batch的支持, 主要反应在finishBatch函数, 而普通的bolt的不同在于, 只有在finishBatch的时候才会去emit结果, 而不是每次execute都emit结果
在prepare时, 多出个id, a TransactionAttempt object, 并且从output定义看出, 所有emit的tuple第一个参数必须是id(TransactionAttempt)
The
TransactionAttemptcontains two values: the "transaction id" and the "attempt id"(表示被replay次数).The "transaction id" is the unique id chosen for this batch and is the same no matter how many times the batch is replayed.
The "attempt id" is a unique id for this particular batch of tuples and lets Storm distinguish tuples from different emissions of the same batch. Without the attempt id, Storm could confuse a replay of a batch with tuples from a prior time that batch was emitted.
All tuples emitted within a transactional topology must have the TransactionAttempt as the first field of the tuple. This lets Storm identify which tuples belong to which batches. So when you emit tuples you need to make sure to meet this requirement.
其实这里的BaseBatchBolt, 是通用的batch基类, 也可以用于其他的需要batch支持的场景, 比如DRPC, 只不过此处的id类型变为RPC id
如果只是要support tansactional topology场景, 可以直接使用BaseTransactionalBolt
public abstract class BaseTransactionalBolt extends BaseBatchBolt<TransactionAttempt> { }
继续看, commit阶段的bolt, UpdateGlobalCount, 将统计的结果累加到全局数据库中
UpdateGlobalCount之间继承自BaseTransactionalBolt, 所以此处prepare的参数直接是TransactionAttempt attempt(而不是object id)
并且比较重要的是实现ICommitter接口, 表明这个bolt是个commiter, 意味着这个blot的finishBatch函数需要在commit阶段被调用
另一种把bolt标识为committer的方法是, 在topology build的时候使用setCommitterBolt来替代setBolt
First, notice that this bolt implements the ICommitter interface. This tells Storm that the finishBatch method of this bolt should be part of the commit phase of the transaction.
So calls to finishBatch for this bolt will be strongly ordered by transaction id (calls to execute on the other hand can happen during either the processing or commit phases).
An alternative way to mark a bolt as a committer is to use the setCommitterBolt method in TransactionalTopologyBuilder instead of setBolt.
public static class UpdateGlobalCount extends BaseTransactionalBolt implements ICommitter { TransactionAttempt _attempt; BatchOutputCollector _collector; int _sum = 0; @Override public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, TransactionAttempt attempt) { _collector = collector; _attempt = attempt; } @Override public void execute(Tuple tuple) { _sum+=tuple.getInteger(1); } @Override public void finishBatch() { Value val = DATABASE.get(GLOBAL_COUNT_KEY); Value newval; if(val == null || !val.txid.equals(_attempt.getTransactionId())) { newval = new Value(); newval.txid = _attempt.getTransactionId(); if(val==null) { newval.count = _sum; } else { newval.count = _sum + val.count; } DATABASE.put(GLOBAL_COUNT_KEY, newval); } else { newval = val; } _collector.emit(new Values(_attempt, newval.count)); } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("id", "sum")); } }
storm会保证commiter里面的finishBatch被顺序执行, 并且在finishBatch里面, 需要check transaction id, 确保只有新的transaction的结果才被更新到全局数据库.
The code for finishBatch in UpdateGlobalCount gets the current value from the database and compares its transaction id to the transaction id for this batch. If they are the same, it does nothing. Otherwise, it increments the value in the database by the partial count for this batch.
A more involved transactional topology example that updates multiple databases idempotently can be found in storm-starter in the TransactionalWords class.
Transactional Topology API
Bolts
There are three kinds of bolts possible in a transactional topology:
- BasicBolt: This bolt doesn't deal with batches of tuples and just emits tuples based on a single tuple of input.
- BatchBolt: This bolt processes batches of tuples.
executeis called for each tuple, andfinishBatchis called when the batch is complete. - BatchBolt's that are marked as committers: The only difference between this bolt and a regular batch bolt is when
finishBatchis called. A committer bolt hasfinishedBatchcalled during the commit phase. The commit phase is guaranteed to occur only after all prior batches have successfully committed, and it will be retried until all bolts in the topology succeed the commit for the batch.
上面列出可能遇到的3种bolt, 下面的例子给出不同blot的区别,

红线标出的都是commiter, 这里有两个commiter, 分别是B和D
A的输出分别输出到B和C
B可以先执行execute(processing), 但不能直接执行finishBatch, 因为需要等待storm调度, 必须等前面的batch commit完后, 才能进行commit
所以C也无法立刻执行finishBatch, 因为需要等从B过来的tuple
对于D, 原文说它会在commit阶段接收所有的batch tuple, 所以可以直接commit, 这个怎么保证?
Notice that even though Bolt D is a committer, it doesn't have to wait for a second commit message when it receives the whole batch. Since it receives the whole batch during the commit phase, it goes ahead and completes the transaction.
Committer bolts act just like batch bolts during the commit phase.
The only difference between committer bolts and batch bolts is that committer bolts will not call finishBatch during the processing phase of a transaction.
Acking
Notice that you don't have to do any acking or anchoring when working with transactional topologies. Storm manages all of that underneath the hood. The acking strategy is heavily optimized.
Failing a transaction
由于封装的比较好, 不需要用户去ack或fail tuple, 那么怎么去fail一个batch?
抛出FailedException, Storm捕获这个异常会replay Batch, 而不会crash
When using regular bolts, you can call the fail method on OutputCollector to fail the tuple trees of which that tuple is a member.
Since transactional topologies hide the acking framework from you, they provide a different mechanism to fail a batch (and cause the batch to be replayed).
Just throw a FailedException. Unlike regular exceptions, this will only cause that particular batch to replay and will not crash the process.
Transactional spout
Transactional spout和普通的spout完全不同的实现, 本身就是一个mini的topology, 分为coordinator spout和emitter bolt
The TransactionalSpout interface is completely different from a regular Spout interface. A TransactionalSpout implementation emits batches of tuples and must ensure that the same batch of tuples is always emitted for the same transaction id.
A transactional spout looks like this while a topology is executing:
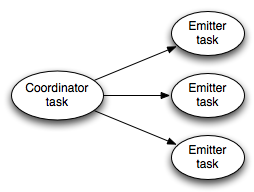
The coordinator on the left is a regular Storm spout that emits a tuple whenever a batch should be emitted for a transaction. The emitters execute as a regular Storm bolt and are responsible for emitting the actual tuples for the batch. The emitters subscribe to the "batch emit" stream of the coordinator using an all grouping.
The need to be idempotent with respect to the tuples it emits requires a TransactionalSpout to store a small amount of state. The state is stored in Zookeeper.
下面是transactional spout的工作流程,
首先coordinator spout只会有一个task, 并会产生两种stream, batch stream和commit stream
它会决定何时开始某transaction processing阶段, 此时就往batch stream里面发送包含TransactionAttempt的tuple
它也决定何时开始某transaction commit阶段(当通过acker知道processing阶段已经完成的时候, 并且所有prior transaction都已经被commit), 此时就往commit steam里面发送一个包含TransactionAttempt的tuple作为通知, 所有commtting bolt都会预订(通过setBolt的all grouping方式)commit stream, 并根据收到的通知完成commit阶段.
对于commit阶段和processing阶段一样, 通过acker来判断是成功还是fail, 前面说了transactional topology对acker机制做了较大的优化, 所以所有acking和anchoring都由storm自动完成了.
对于emitter bolt, 可以并发的, 并且以all grouping的方式订阅coordinator的batch stream, 即所有emitter都会得到一样的batch stream, 使用几个emitter取决于场景.
对于topology而言, emitter bolt是真正产生数据的地方, 当coordinator开始某batch的processing过程, 并往batch steam放tuple数据时, emitter bolt就会从batch stream收到数据, 并转发给topology
Here's how transactional spout works:
- Transactional spout is a subtopology consisting of a coordinator spout and an emitter bolt
- The coordinator is a regular spout with a parallelism of 1
- The emitter is a bolt with a parallelism of P, connected to the coordinator's "batch" stream using an all grouping
- When the coordinator determines it's time to enter the processing phase for a transaction, it emits a tuple containing the TransactionAttempt and the metadata for that transaction to the "batch" stream
- Because of the all grouping, every single emitter task receives the notification that it's time to emit its portion of the tuples for that transaction attempt
- Storm automatically manages the anchoring/acking necessary throughout the whole topology to determine when a transaction has completed the processing phase. The key here is that *the root tuple was created by the coordinator, so the coordinator will receive an "ack" if the processing phase succeeds, and a "fail" if it doesn't succeed for any reason (failure or timeout).
- If the processing phase succeeds, and all prior transactions have successfully committed, the coordinator emits a tuple containing the TransactionAttempt to the "commit" stream.
- All committing bolts subscribe to the commit stream using an all grouping, so that they will all receive a notification when the commit happens.
- Like the processing phase, the coordinator uses the acking framework to determine whether the commit phase succeeded or not. If it receives an "ack", it marks that transaction as complete in zookeeper.
从后面的讨论, 可以知道transactional spout的batch replay是依赖于source queue的
比如, 对于kafka这种数据是分布在partition上的queue, 需要使用partitioned transactional spout, 用于封装对从不同partition读数据的过程
Partitioned Transactional Spout
A common kind of transactional spout is one that reads the batches from a set of partitions across many queue brokers. For example, this is how TransactionalKafkaSpout works. An
IPartitionedTransactionalSpoutautomates the bookkeeping work of managing the state for each partition to ensure idempotent replayability.
对于Transactional spout, 并不会象普通tuple一样由spout缓存和负责replay, 只会记下该batch数据在source queue的位置(应该是zookeeper), 当需要replay的时候, Transactional spout会从新去source queue去读batch然后replay.
这样的问题是过于依赖source queue, 而且会导致transaction batch无法被replay(比如由于某个partition fail)
这个问题如何解决? 可以参考原文, 比较好的方法, 是fail当前和后续所有的transaction, 然后重新产生transaction的batch数据, 并跳过失败部分
个人决定这个设计不太好, 过于依赖source queue
为何不在spout缓存batch数据, 虽然这样对于比较大的batch可能有效率问题, 或者会限制同时处理的batch数目, 但重新从source queue读数据来replay也会有很多问题...