昨天在保存一些中文字符到文本文档时,发现一个很奇怪的现象。先看看代码:
#coding=utf-8 import os def write_use_open(filepath): try: file = open(filepath, 'wb') try: content = '中华人民共和国abcd \r\nee ?!>??@@@!!!!!???¥@#%@%#xx学校ada\r\n' print file.encoding print file.newlines print file.mode print file.closed print content file.write(content) finally: file.close() print file.closed except IOError, e: print e if __name__ == '__main__': filepath = os.path.join(os.getcwd(), 'file.txt') write_use_open(filepath)
开始我是IDLE编写的,并直接按F5运行,没发现问题,文件也被正确地保存,文件的编码类型也是utf-8.


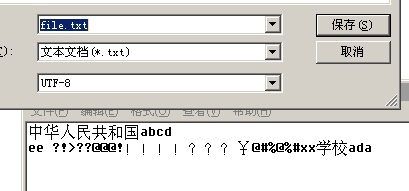
可是我用命令行运行,却发现显示出现乱码了,然后在打开文件发现文件被正确保存了,编码还是utf-8:
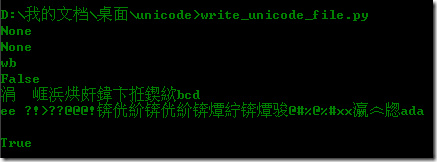
我想问题是命令行不能自动识别字符编码吧,因为IDLE显示是正确的,它支持utf-8。
于是我修改了代码,在字符串前加了'u',表明content是unicode:
content = u'中华人民共和国abcd \r\nee ?!>??@@@!!!!!???¥@#%@%#xx学校ada\r\n'
可是运行发现,命令行是正确显示了,但是却出现异常:
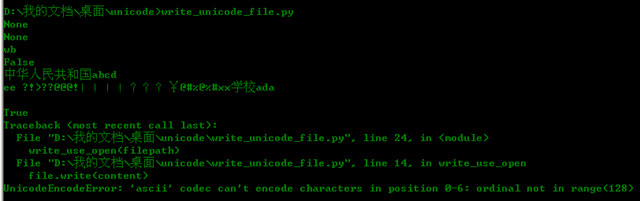
很明显,content里包含了非ASCII码字符,肯定不能使用ASCII来进行编码的,write方法是默认使用ascii来编码保存的。
很容易就可以想到,在保存之前,先对unicode字符进行编码,我选择utf-8
#coding=utf-8 import os def write_use_open(filepath): try: file = open(filepath, 'wb') try: content = u'中华人民共和国abcd \r\nee ?!>??@@@!!!!!???¥@#%@%#xx学校ada\r\n' print file.encoding print file.newlines print file.mode print file.closed print content print unicode.encode(content, 'utf-8') file.write(unicode.encode(content, 'utf-8')) finally: file.close() print file.closed except IOError, e: print e if __name__ == '__main__': filepath = os.path.join(os.getcwd(), 'file.txt') write_use_open(filepath)
看看运行结果:
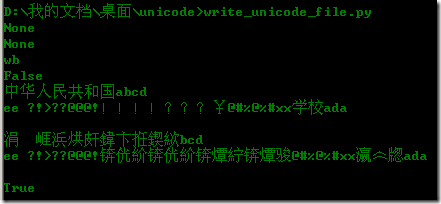
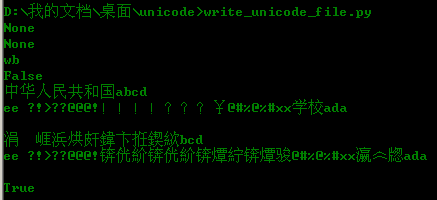
OK了打开文档也是正确的。
读取文件又怎样?同样道理,只是这次不是编码了,而解码:
def read_use_open(filepath): try: file = open(filepath, 'rb') try: content = file.read() content_decode = unicode(content, 'utf-8') print 'original text' print content print 'decode using utf-8' print content_decode finally: file.close() except IOError, e: print e if __name__ == '__main__': filepath = os.path.join(os.getcwd(), 'file.txt') write_use_open(filepath) print 'read file ---------------------------' read_use_open(filepath)

为什么不直接在open的时候就解码呢?呵呵,可以啊,可以使用codecs的open方法
import codecs def read_use_codecs_open(filepath): try: file = codecs.open(filepath, 'rb', 'utf-8') try: print 'using codecs.open' content = file.read() print content finally: file.close() except IOError, e: print e

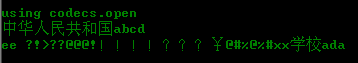
好了,希望对你有用。
本文参考:Unicode HOWTO