本博客(http://blog.csdn.net/livelylittlefish )贴出作者(阿波)相关研究、学习内容所做的笔记,欢迎广大朋友指正!
Content
4.1基本思想
4.2数据结构描述
4.3分解过程描述
4.4如何输出?
4.5输出结果
4.6讨论
附录 4 :再改进的方法的代码weight3.1.c/3.2.c/3.3.c
附录 5 :再改进的方法的代码weight3.1.c/3.2.c/3.3.c 的输出结果
附录 7 :一个更简单的方法的代码weight5.1.c/5.2.c/5.3.c
4. 一个改进的方法
修改数据结构,不用第3节的各种数组,而用树形结构来保存称量过程的分解结果。
4.1 基本思想
该方法的基本思想如下图。
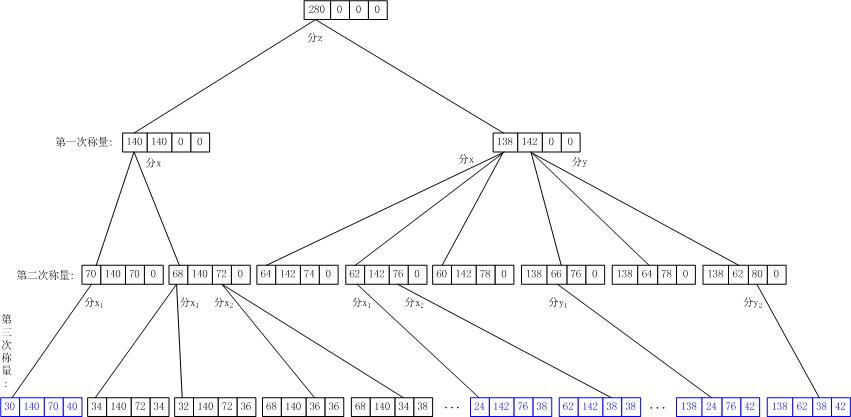
图中每个节点对应分解过程的每一个称量结果,根(第0层)表示起始状态,第1层表示第1次称量结果,依此类推。从根到叶子节点的路径就代表了一次完整的称量过程(该称量过程有分解结果,但结果不一定满足目标)。满足目标的叶子(上图中显示为蓝色)即为正确的称量结果。
比较该图与第3节的图,很显然,该方法数据结构统一、简单,且节省大量空间。
4.2 数据结构描述
图中节点结构及根节点定义如下。
00001: / **
00002: * the proble of dividing salt using weight.
00003: * a heap of salt with 280g, divide it into two small heaps of salt with 100g and 180g
00004: * respectively, in 3 steps. the weights are 4g and 14g. there is a balance of course.
00005: *
00006: * this is an improved search method based on the pure mathematical method.
00007: */
00008: #include <stdio.h>
00009: #include <stdlib.h>
00010: #include <string.h>
00011:
00012: #define Max_Num 5
00013: #define To_Be_Devided 2
00014:
00015: #define total 280 //the total weight of the heap of salt
00016: int ws[]={0, 4, 10, 14, 18}; //all cases of the weights combination
00017: int heap1 = 100, heap2 = 180; //the target weight of the two samll heaps of salt
00018:
00019: struct Division_Node
00020: {
00021: int parent_be_divided_; //array to_be_divided_[] divided from its parent with this index
00022: int step_; //the node step in the division process
00023: int heap_[Max_Num - 1]; //all divisions of its parent position for all weights
00024: int to_be_divided_[2]; //salt heap index to be divided in next step
00025: struct Division_Node *next_[2* Max_Num]; //all pointers to all child divisions
00026: int child_; //the numbe of children (not NULL in array next_)
00027: };
00028:
00029: //the root, for step 1, heap_[0] will be divided
00030: static struct Division_Node root = {0, 0, {total}, {0}, {NULL}, 0};
当前节点保存其父节点被分解后的结果,heap_[]数组中,下标为to_be_divided_[0]和to_be_divided_[1]的元素保存了新生成的两个值,parent_be_divided_表示这两个值是由其父节点的heap_[]数组中第parent_be_divided_个元素被分解的结果。
例如,父亲节点parent,儿子节点为child,其关系为:parent.heap_[child.parent_be_divided_]被分解为两个值,分别为child.heap_[child.to_be_divided_[0]]和child.heap_[child.to_be_divided_[1]],且有parent.next_[k]=&child,表示child是parent的第k个儿子。对于child的下一次分解,就依次分解这两个新生成的值。
4.3 分解过程描述
按广度优先的顺序,求得如上图的每一次称量的节点,即可完成所有有结果的称量。当然要避免重复,并使用限制规则来减小搜索空间。
从根节点root.heap_[4]={280}开始分解,初始时root.to_be_divided_[2]={0},即开始时只有root.heap_[0]=280需要分解,以分解x及x1为例说明该分解过程。
(1) 第一次称量:step=1,z=x+y,x保存在heap_[0],y保存在heap_[step],to_be_divided_[2]={0,step}。
(2) 第二次称量:step=2,x=x1+x2,x1保存在heap_[0],x2保存在heap_[step],to_be_divided_[2]={0,step}。
(3) 第三次称量:step=3,x1=x11+x12,x11保存在heap_[0],x12保存在heap_[step],to_be_divided_[2]={0,step}。
该过程从上图也能看到。此处仅给出第三次称量过程的代码,如下,其他省略,具体请参考附录3。
00119: /** the third division, according to
00120: x1=x11+x12, y1=y11+y12, x11<=x12, y11<=y12
00121: x2=x21+x22, y2=y21+y22, x21<=x22, y21<=y22
00122: but, x1 or x2 or y1 or y2 is saved in heap_ of each node2 with index node2- >to_be_divided_[0]
00123: and node2- >to_be_divided_[1]. so, unify them to be as x1.
00124: */
00125: void weight3()
00126: {
00127: int div = 0, i = 0, j = 0, k = 0, w = 0;
00128: struct Division_Node *cur = &root;
00129:
00130: int step = 3;
00131: for (i = 0; i < cur->child_; i++) //for each node1 in step1
00132: {
00133: struct Division_Node *node1 = cur->next_[i];
00134: for (j = 0; j < node1->child_; j++) //for each node2 of node1 in step2
00135: {
00136: struct Division_Node *node2 = node1->next_[j];
00137:
00138: //to avoid repeatance
00139: int to_be_divided = To_Be_Devided;
00140: if (node2->heap_[node2->to_be_divided_[0]] == node2->heap_[node2->to_be_divided_[1]])
00141: to_be_divided--;
00142:
00143: int child = 0;
//for step 3, will divide x1=heap_[0], x2=heap_[2] of node2
00144: for (div = 0; div < to_be_divided; div++)
00145: {
00146: int curpos = node2->to_be_divided_[div];
00147: int x1 = node2->heap_[curpos];//the current heap to be divided, x1,or x2,or y1,or y2
00148:
00149: for (k = 0; k < Max_Num; k++)
00150: {
00151: w = ws[k];
00152: int x11 = (x1 - w)/2; //divide x or y, use x in order to be in a uniform
00153: int x12 = (x1 + w)/2;
00154: if (x11 % 2!= 0) //no need to judge x12
00155: continue;
00156:
00157: //new a node in step 3
00158: struct Division_Node *node3 = (struct Division_Node*)malloc(sizeof(
struct Division_Node));
00159: memset(node3, 0, sizeof(struct Division_Node));
00160: memcpy(node3->heap_, node2->heap_, (Max_Num-1)*sizeof(int));//copy from its parent
00161: node3->parent_be_divided_ = curpos;
00162: node3->step_ = step;
00163: node3->heap_[curpos] = x11;
00164: node3->heap_[step] = x12;
00165: node3->to_be_divided_[0] = curpos; //in fact, this array in step3 needed for dump
00166: node3->to_be_divided_[1] = step;
00167: node2->next_[child++] = node3; //link current node2 and node3
00168: }
00169: }
00170:
00171: node2->child_ = child;
00172: }
00173: }
00174: }
4.4 如何输出?
广度遍历该树,即可输出所有结果。如果加入判断,即可输出正确分解结果。此处列出输出正确结果的代码。具体过程不再解释,可参考代码注释进行理解。
00204: void dump_correct_results(struct Division_Node* node)
00205: {
00206: int i = 0, j = 0, k = 0;
00207: struct Division_Node *cur = node;
00208:
00209: for (i = 0; i < cur->child_; i++) //for each node1 in step1
00210: {
00211: struct Division_Node *node1 = cur->next_[i];
00212: for (j = 0; j < node1->child_; j++) //for each node2 of node1 in step2
00213: {
00214: struct Division_Node *node2 = node1->next_[j];
00215: for (k = 0; k < node2->child_; k++) //for each node3 of node2 in step 3
00216: {
00217: struct Division_Node *node3 = node2->next_[k];
00218:
00219: /** unify them into the following equations
00220: z = x + y, x <= y
00221: x = x1 + x2, x1 <= x2
00222: x1 = x11 + x12, x11 <= x12
00223: */
00224: int x11 = node3->heap_[node3->to_be_divided_[0]];
00225: int x12 = node3->heap_[node3->to_be_divided_[1]];
00226: int x2index = 0;
00227: if (node3->parent_be_divided_ == node2->to_be_divided_[0])
00228: x2index = node2->to_be_divided_[1];
00229: else
00230: x2index = node2->to_be_divided_[0];
00231: int x2 = node2->heap_[x2index];
00232:
00233: if (x11 + x2 == heap1 || x12 + x2 == heap1)
00234: {
00235: printf("%d = %d + %d\n", total, node1->heap_[node1->to_be_divided_[0]],
00236: node1->heap_[node1->to_be_divided_[1]]);
00237: printf("%d = %d + %d\n", node1->heap_[node2->parent_be_divided_],
00238: node2->heap_[node2->to_be_divided_[0]],
00239: node2->heap_[node2->to_be_divided_[1]]);
00240: printf("%d = %d + %d\n\n", node2->heap_[node3->parent_be_divided_], x11, x12);
00241: }
00242: }
00243: }
00244: }
00245: }
4.5 输出结果
该方法的输出结果与第3节的输出结果完全相同。此处省略,有兴趣的读者可以自行验证。具体的输出结果请参考附录2。
4.6 讨论
比起第3节数学的方法,该方法不需要那么多的数组定义,定义数组的方法(第3节)如果加上别的条件,例如再多一次称量,很难扩展。很显然,该方法数据结构统一、简单,且节省大量空间。但该方法也有缺点,例如,最终的正确解只有5个,但该方法同第3节的数学方法一样,计算了所有的有结果的解,共37个,也比较浪费。
那么,有没有一种方法,直接在第2次称量和第3次称量的时候直接判断这个分解是否正确或者直接计算这个正确的解呢?——有。下面介绍这种方法。
