http://www.udpwork.com/item/4066.html
单机存储引擎解决单机读写问题,Merge-Dump存储引擎设计成一种通用的存储引擎,同时支持数据写入,随机读取和顺序扫描功能。顺序扫描功能应用很广,比如MapReduce批处理,同一个广告主的所有关键词广告统计,用户浏览所有的收藏信息,淘宝卖家管理大量的商品等。简单的KV系统只需要支持随机读取,而类似Bigtable这样的通用表格系统需要考虑基于主键的顺序扫描功能。Bigtable中的Merge-Dump存储引擎结构如下:

用户的操作首先写入到MemTable中,当内存中的MemTable达到一定的大小,需要将MemTable dump到持久化存储中生成SSTable文件。这里需要注意,除了最早写入的SSTable存放了最终结果以外,其它的SSTable和MemTable存放的都是用户的更新操作,比如对指定行的某个列加一操作,删除某一行等。每次读取或者扫描操作都需要对所有的SSTable及MemTable按照时间从老到新进行一次多路归并,从而获取最终结果。为了防止机器宕机,将用户的操作写入MemTable之前,会先写入到操作日志(commit
log)中,这时一般会用到group commit操作,即将大量并发写操作聚合成一块一次性写入到commit log。由于写commit log为顺序追加,很好地利用了磁盘的顺序访问特性。
为了防止磁盘中的SSTable文件过多,需要定时将多个SSTable通过compaction过程合并为一个SSTable,从而减少后续读操作需要读取的文件个数。Bigtable中将compaction分为三种:minor compaction,merge compaction以及major compaction。其中,minor compaction指的是当内存中的MemTable达到一定的大小以后需要生成SSTable;merge compaction将连续多个大小接近的SSTable及Memtable合并生成一个SSTable;major
compaction合并所有的SSTable和Memtable生成最终的SSTable文件。Minor和Merge compaction生成的SSTable文件中包含的还是用户的更新操作,只有Major compaction生成的SSTable才包含最终结果。一般来说,线上服务的写操作比较少,我们总是能以很大概率使得每个子表只包含一个SSTable和MemTable,也就是说,读取操作基本只需要访问一个SSTable文件和内存;而线下或者半线下服务,比如网页库,虽然写入操作多,可能经常出现一个子表包含多个SSTable的情况,不过这种类型的服务一般用于大数据量顺序扫描,对延时要求不高。SSTable的compaction有几个需要注意的点:
1, 限制SSTable的数量,必要时限制写入速度。如果写入速度持续大于compaction消化的速度,也就是大于系统的承载能力,SSTable将越积越多从而compaction永远无法成功。比如Cassandra存储节点采用了类似Bigtable的Merge-dump的做法,不过据说可能因为没有控制SSTable的最大个数也出现永远合并不成功的问题;
2, Compaction及写操作并发控制。Compaction的过程很长,compaction不能阻塞写操作,并且minor compaction和merge/major compaction可能同时进行。Compaction成功提交的时候需要互斥修改子表记录的SSTable结构数组,多个compaction同时进行的时候有些麻烦;
3, Minor compaction时机。当Memtable达到一定大小,比如4MB时,需要冻结Memtable并生成SSTable数据dump到磁盘中;同时,由于所有子表的操作日志写入到同一个commit log文件,当MemTable距离第一条数据写入超过一定的时间也需要执行minor compaction,否则,会出现机器宕机回放的commit log过多的问题;
4, Merge compaction如何选取SSTable文件。Merge compaction合并SSTable以减少读取的文件个数,每次merge compaction都是把相应的SSTable文件分别读写一次。为了提高性能,一般会要求Merge compaction选取连续的大小接近的SSTable文件。举个例子,如果有4个大小为4MB的SSTable文件,如果merge的策略为((s1 & s2) & s3) & s4 (&表示merge操作),读取的文件大小为s1 * 3 + s2 * 3 + s3
* 2 + s4 * 1 = 4M * 9 = 36M,如果merge的策略为(s1 & s2) & (s3 & s4),读取的文件大小为s1 * 2 + s2 * 2 + s3 * 2 + s4 * 2 = 32M,并且SSTable文件个数越多差别越明显;
数据在SSTable中连续存放,需要同时随机读取和顺序读取两种需求。SSTable被分成大小约为64KB的块(SSTable block),由于单个tablet的大小一般为100MB ~ 200MB,我们可以认为SSTable的大小不超过256MB,包含的block个数为256MB / 64KB = 4KB,每个block需要包含起始行,结束行相关的索引信息,假设索引信息大小平均为256Byte,每个SSTable的索引大小为4KB * 256Byte = 1MB,磁盘内存比为256 : 1,16GB的索引可以存放16GB
* 256 = 4TB的数据。SSTable的索引数据全部存放到内存中,随机读取需要先通过二分查找找到相应的block,然后从磁盘中读取相应的block数据。Bigtable系统使用的SATA盘的磁盘寻道时间一般为10ms左右,一次随机读取整个64KB的块造成的overhead是可以接受的。按照64KB划分块还带来了一个好处,数据量膨胀对性能的影响很小。顺序读取的做法类似,在Merge-dump引擎中是很高效的。与传统的数据库的数据格式不同,SSTable存放的数据一般都是稀疏的,大多数列可能都没有更新操作。
按列存储&压缩:数据仓库的应用场景中需要支持按列存储,有两个好处:第一个好处是减少读取的数据量,第二个好处是提高压缩比率。Bigtable支持指定locality group,每个locality group中的列在SSTable中连续存储,每一个locality group之内按照行有序存储,当然,数据在MemTable中是不需要区分locality group的。这样,compaction是按照locality group进行的,读取每一个待归并的SSTable中相应的locality group的数据,合并生成一个新的SSTable
locality group。某些跨多个locality group的更新操作,比如删除一行,需要将更新操作同时写入到多个locality group中。
总之,Merge-dump是一种同时满足随机和顺序读取的通用存储引擎,可以广泛应用在各种NOSQL存储系统中,另外,Merge-dump存储引擎往commit log文件追加操作日志以及compaction过程都是顺序写文件,非常符合SSD的特性,天然适应硬件的发展趋势。
按照 BigTable的定义,SSTable叫做 Sorted String Table.其本质上是一种文件格式用于存储数据到磁盘上。
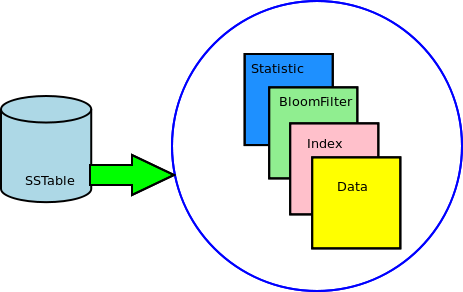
SSTable的种类
1. Data
Data文件用于存储所有 ColumnFamily的信息,即其包含的 Column和 Column
Index (注意:列索引没有单独的文件,如果采用 B+-Tree则需要有单独的文件)
.
存储格式
|
SSTable Data File |
||||||||||||||||||
|
Key.length |
||||||||||||||||||
|
key |
||||||||||||||||||
|
DataFile.size |
||||||||||||||||||
|
||||||||||||||||||
|
||||||||||||||||||
|
.. Column N -1 |
columnIndex List 的元素由预设置的size 来组织,例如,当column_size
= 64K, 当累加的column 的大小超过这一值时,创建一个新的index, 并加入到columnIndex
List
column BloomFilter 用于对Column 的访问
2. Row Index
包含Row的基于 rowKey的索引
存储格式
|
Index File |
|
Key List |
|
Key 0 |
|
Key.length |
|
key |
|
StartPositoin in datafile for the key |
|
Key N-1 |
内存中的数据表示 for Reader
|
Key0 |
StartPosition0 in data file |
|
... |
... |
|
KeyN-1 |
StartPositionN-1 in data file |
3. Row Key BloomFilter
Row Key BloomFilter用于对基于 Row key索引的访问。
|
Row Key BloomFilter File |
|
sizeOf(below fields) |
|
BloomFilter.hashCount |
|
Bits.length |
|
Bit[0] ~ bit[bits.length -1] |
4. Statistics
统计文件用于统计一个 SSTable包含的 rowCount,columnCount。一般情况下会以柱状图的形式出现(Histogram)
|
Statistics File |
|
Row Count |
|
Series [0] ~ Series[n-1] |
|
Statistic[0] ~statistic[n-1] |
|
Column Count |
|
Series [0] ~ Series[n-1] |
|
Statistic[0] ~statistic[n-1] |
操作
1 Write
当 MemTable达到预设置的极限值时,其内容将依次被 flush到磁盘上。SSTable 的 Data, index, filter, statistic文件将被生成。

1.1 write data file
MemTable flush时,写入 data文件:
- 因为 key是按照升序排列的,所以,首先根据 key,获得其在文件中的位置
- 将 key写入
- 整个row的大写写入
- 写入 column index的 bloom filter的信息
- 写入 column index的信息 (start position, end position, index size)
- 写入 column的信息 (name, value, timestamp)
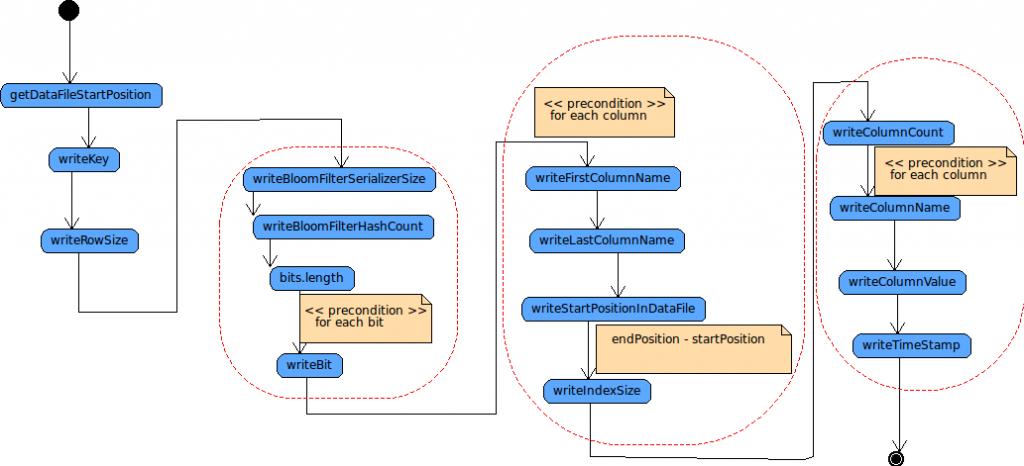
1.2 write Row index file
每次向 Data文件增加一行记录时,都将向 Row index文件加入以下数据:
- 写入 Key
- 写入key在数据文件中对应的 startPosition
1.3 write Row Index BloomFilter
每次向 Data文件增加一行记录时,都向 row Index bloomfilter增加统计信息,当数据文件最终写到磁盘后,对应的 BloomFilter文件将生成,原则上是将 BloomFilter的 Serializer形式写入磁盘即可:
- 写入 hashCount
- 写入 bits数据的长度
- 依次写 bits [0]到 bits[n-1]的内容
2 Read
当系统初始化时,所有的 SSTable需要加载到系统.
2.1 QueryByRowKey
1) 首先通过 BloomFilter看看 key是否存在,如果不存在直接返回(注意:bloomFilter永远不会返回假的不存在)
2) 如果存在,则需要进一步证实 BloomFilter不是 false Positive。
3) 通过查找内存的 cache看看 key是否可以命中 cache,如果命中,直接返回命中的记录;
4) 如果没有命中通过二分查找法在内存中的 index信息中找到 key在 data文件中的位置并返回(startPosition)
以上过程中会涉及到数据统计信息(例如 bloomFilter false Positive) 以及 cache 的更新(在通过磁盘加载到 key 的记录后)
2.2 QueryByRowKeyRang
基于 Rang的查询返回的是一个 List,本质上是一个 getPostion(left key) 和 getPostion(right key)
3 Compact
归并(Compact, 这个词真没有好的对应的中文) 可以分为两种类型:
3.1 Minor
为系统自动执行,系统设置以下参数
- 最小 SSTable个数 m1
- 最大 SSTable个数 m2
- SSTable大小平均值 A:比如 50M
- 统计存在的 SSTable,如果最终,大小处在 [½ A, 2/3 A] 的 SSTable的个数超过了 m1,则进行一次 minor归并。
3.2 Major
Major归并与 Minor归并不同之处在于,将进行一次 ColumnFamily级的剪切( purge) –将做了删除标识的 column 清除。
Major归并可以通过手工触发,比如在系统资源不够时;
另外,当在自动进行 minor归并时,如果代处理的 SSTable列表包含了该 ColumnFamily的所有的 SSTable (即完成地处理了一个 Column Family),那么也将进行一次 major归并。
对所有的 ColumnFamily,为了效率起见,可以选择地忽略太大的文件
3.3 归并处理流程
1) 根据所有 SSTable的大小,估算出待生成的归并 SSTable的大小, 并试图得到归并后的文件路径
2) 如果磁盘目前大小满足不了这一请求,则依次去掉最大的文件,直接最后剩下两个文件,如果还没法满足,则报告错误
3) 如果 SSTable列表即是此 ColumnFamily的所有 SSTable,则可以进行一次 major归并
4) 根据所有 SSTable的大小,估算出估计的行数,此参数用于生成 row index cache的大小
5) 将所有SSTable按 key的排序累积
6) 根据上述文件位置和估计的行数 生成一个输出文件 newSSTable
7) 依次迭代累积的 SSTable
a) 如果是一次 major归并,或者当前 row全部清除,则清除 columnFamily中所有作了清除标记和需要清除的 column以及 column Family,
b) 输出到 newSSTable
8) 生成新的newSSTable对应的 row index, filter, statistic文件
9) 将新生成的 newSSTable整理到系统中其它 SSTabe
10) 更新 cache
4 Delete
当多个 SSTable被归并(Compact)到一个更大的 SSTable文件时,旧的 SSTable文件需要删除以释放磁盘空间。
但由于在分布式的环境中,出于性能考虑,在 Compact过程中,删除操作不会立即执行,而是将对应的文件加入到一个后台删除线程。