关于分词就不多介绍了,园子里很多这样的文章.birdshover就写了一些关于分词的文章.在这里我主要深入Lucene分词工具的内部算法,希望能与大家一起交流.
Lucene与分词有关的类的结构图如下:
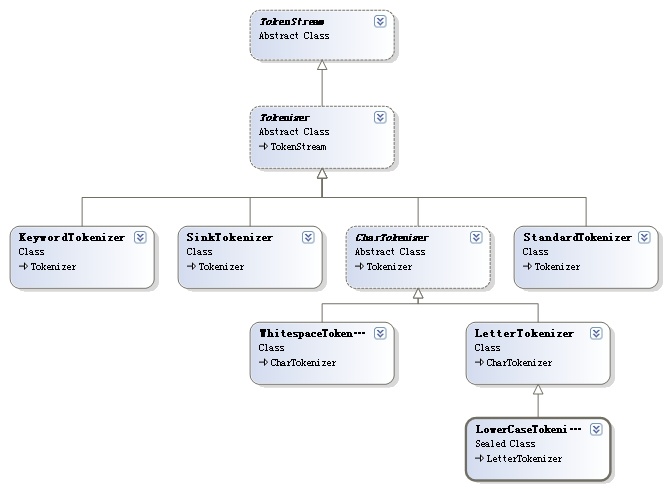
(图片引自:http://www.cnblogs.com/birdshover/archive/2008/08/28/1279044.html)
在本节主要讨论LetterTokenizer和CharTokenizer,实际上算法的实现是在CharTokenizer中的next()中实现的.
首先为了有个感性的认识,来看一个LetterTokenizer的例子:
using System;
using System.Collections.Generic;
using System.Text; using Lucene.Net.Analysis;
using System.IO;
namespace ConsoleTestProject
{
public class TestLetterTokenizer
{
//测试数据
static string TEST_TEXT = "达梦数据库,DM Database!";
public static void Test()
{
TokenStream ts = new LetterTokenizer(new StringReader(TEST_TEXT));
Token token;
while ((token = ts.Next()) != null)
{
Console.WriteLine(token.TermText());
}
ts.Close();
}
static void Main(string[] args)
{
Test();
Console.Read();
}
}
}
输出结果如下:
达梦数据库
DM
Database
LetterTokenizer中的next()方法继承自CharTokenizer.
下面将对CharTokenizer的next()方法进行详细解剖:
using System;
namespace Lucene.Net.Analysis
{
public abstract class CharTokenizer : Tokenizer
{
public CharTokenizer(System.IO.TextReader input) : base(input)
{
}
private int offset = 0, bufferIndex = 0, dataLen = 0;
private const int MAX_WORD_LEN = 255; //允许的单词的最大长度
private const int IO_BUFFER_SIZE = 1024; //一次允许最大的字符数
private char[] buffer = new char[MAX_WORD_LEN]; //单词缓冲区,构造Token的数据来源
private char[] ioBuffer = new char[IO_BUFFER_SIZE];//输入字符串存放的缓冲区
//检查当前字符是能够生成Token的字符,留给子类实现
protected internal abstract bool IsTokenChar(char c);
protected internal virtual char Normalize(char c)
{
return c;
}
/// <summary>Returns the next token in the stream, or null at EOS. </summary>
public override Token Next()
{
int length = 0; //单词的长度
/**
* offset记录当前字符中原字符串中总的位置,它与bufferIndex的值有区别的,
* bufferIndex代表当前字符在这一次读取的字符串中的位置(它的最大值受ioBuffer大小限制)
*/
int start = offset;
while (true)
{
char c;
offset++;
if (bufferIndex >= dataLen) //dataLen代表每次读取字符串的长度
{
dataLen = input.Read((System.Char[]) ioBuffer, 0, ioBuffer.Length);
bufferIndex = 0;
}
//如果没有数据了则退出循环
if (dataLen <= 0)
{
if (length > 0)
break;
else
return null;
}
else
c = ioBuffer[bufferIndex++]; //bufferIndex为ioBuffer字符的位移量
if (IsTokenChar(c))
{
// if it's a token char
if (length == 0)
// start of token
start = offset - 1; //start为每个单词在原始字符串中的起始位置
buffer[length++] = Normalize(c); // buffer it, normalized
//单词长度超过允许的最大长度,则退出循环
if (length == MAX_WORD_LEN)
// buffer overflow!
break;
}
else if (length > 0)
// at non-Letter w/ chars
break; // return 'em
}
//把数据封装成一个Token返回
return new Token(new System.String(buffer, 0, length), start, start + length);
}
}
}
根据程序中的注释很容易就会明白该算法的大体思想:
遍历输入字符串,根据特殊符号将输入字符串分成一个个单词,然后封装成Token返回,时间复杂度为O(n).