我们在中断专题中提到,Linux的缺页(Page Fault)异常处理程序必须区分以下两种情况:由编程错误所引起的异常,及由引用属于进程地址空间但还尚未分配物理页框的页所引起的异常。
线性区描述符可以让缺页异常处理程序非常有效地完成它的工作。do_page_fault()函数是80x86上的缺页中断服务程序,它把引起缺页的线性地址和当前进程的线性区相比较,从而能够根据和下图所示的方案选择适当的方法处理这个异常。
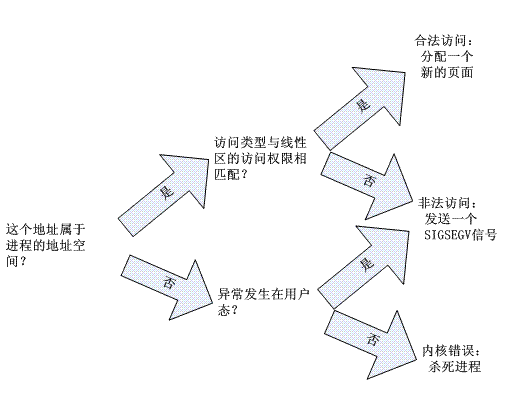
在实际中,情况更复杂一些,因为缺页处理程序必须处理多种分得更细的特殊情况,它们不宜在总体方案中列出来,还必须区分许多种合理的访问。处理程序的详细流程图如图所示:
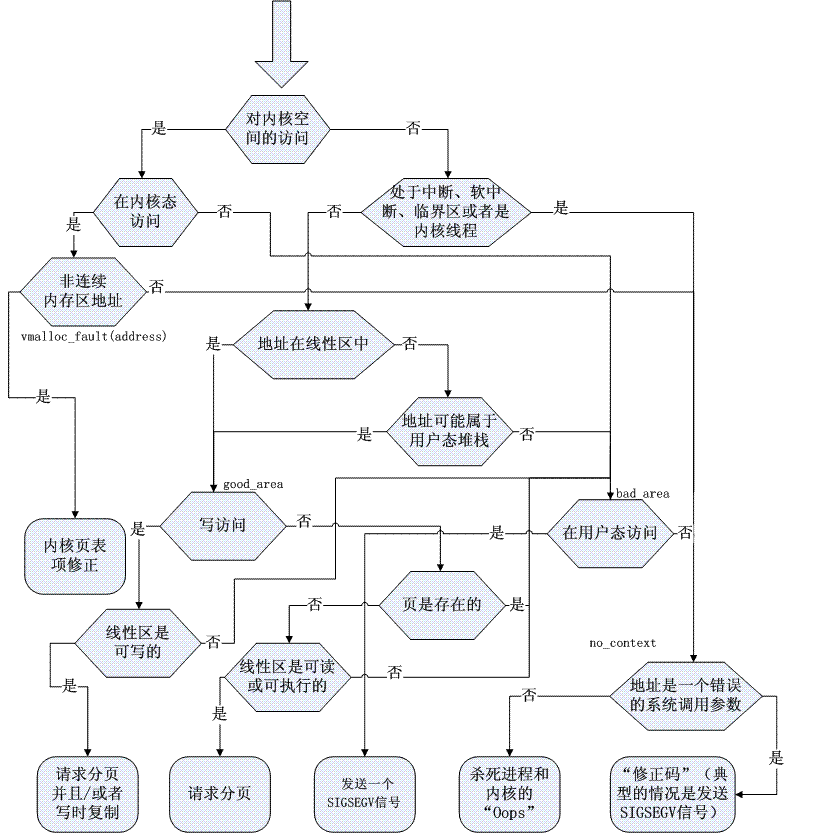
图中标识good_area、bad_area和no_context等是出现在do_page_fault()中的标记,它们有助于你理清流程图中的块与代码中特定行之间的关系。下面,我们就来晒晒这段Linux内存管理中,中重要的异常处理代码:
fastcall void __kprobes do_page_fault(struct pt_regs *regs,
unsigned long error_code)
{
struct task_struct *tsk;
struct mm_struct *mm;
struct vm_area_struct * vma;
unsigned long address;
unsigned long page;
int write, si_code;
/* get the address */
address = read_cr2();
tsk = current;
si_code = SEGV_MAPERR;
/*
* We fault-in kernel-space virtual memory on-demand. The
* 'reference' page table is init_mm.pgd.
*
* NOTE! We MUST NOT take any locks for this case. We may
* be in an interrupt or a critical region, and should
* only copy the information from the master page table,
* nothing more.
*
* This verifies that the fault happens in kernel space
* (error_code & 4) == 0, and that the fault was not a
* protection error (error_code & 9) == 0.
*/
if (unlikely(address >= TASK_SIZE)) {
if (!(error_code & 0x0000000d) && vmalloc_fault(address) >= 0)
return;
if (notify_page_fault(DIE_PAGE_FAULT, "page fault", regs, error_code, 14,
SIGSEGV) == NOTIFY_STOP)
return;
/*
* Don't take the mm semaphore here. If we fixup a prefetch
* fault we could otherwise deadlock.
*/
goto bad_area_nosemaphore;
}
if (notify_page_fault(DIE_PAGE_FAULT, "page fault", regs, error_code, 14,
SIGSEGV) == NOTIFY_STOP)
return;
/* It's safe to allow irq's after cr2 has been saved and the vmalloc
fault has been handled. */
if (regs->eflags & (X86_EFLAGS_IF|VM_MASK))
local_irq_enable();
mm = tsk->mm;
/*
* If we're in an interrupt, have no user context or are running in an
* atomic region then we must not take the fault..
*/
if (in_atomic() || !mm)
goto bad_area_nosemaphore;
/* When running in the kernel we expect faults to occur only to
* addresses in user space. All other faults represent errors in the
* kernel and should generate an OOPS. Unfortunatly, in the case of an
* erroneous fault occurring in a code path which already holds mmap_sem
* we will deadlock attempting to validate the fault against the
* address space. Luckily the kernel only validly references user
* space from well defined areas of code, which are listed in the
* exceptions table.
*
* As the vast majority of faults will be valid we will only perform
* the source reference check when there is a possibilty of a deadlock.
* Attempt to lock the address space, if we cannot we then validate the
* source. If this is invalid we can skip the address space check,
* thus avoiding the deadlock.
*/
if (!down_read_trylock(&mm->mmap_sem)) {
if ((error_code & 4) == 0 &&
!search_exception_tables(regs->eip))
goto bad_area_nosemaphore;
down_read(&mm->mmap_sem);
}
vma = find_vma(mm, address);
if (!vma)
goto bad_area;
if (vma->vm_start <= address)
goto good_area;
if (!(vma->vm_flags & VM_GROWSDOWN))
goto bad_area;
if (error_code & 4) {
/*
* Accessing the stack below %esp is always a bug.
* The large cushion allows instructions like enter
* and pusha to work. ("enter $65535,$31" pushes
* 32 pointers and then decrements %esp by 65535.)
*/
if (address + 65536 + 32 * sizeof(unsigned long) < regs->esp)
goto bad_area;
}
if (expand_stack(vma, address))
goto bad_area;
/*
* Ok, we have a good vm_area for this memory access, so
* we can handle it..
*/
good_area:
si_code = SEGV_ACCERR;
write = 0;
switch (error_code & 3) {
default: /* 3: write, present */
#ifdef TEST_VERIFY_AREA
if (regs->cs == KERNEL_CS)
printk("WP fault at %08lx/n", regs->eip);
#endif
/* fall through */
case 2: /* write, not present */
if (!(vma->vm_flags & VM_WRITE))
goto bad_area;
write++;
break;
case 1: /* read, present */
goto bad_area;
case 0: /* read, not present */
if (!(vma->vm_flags & (VM_READ | VM_EXEC | VM_WRITE)))
goto bad_area;
}
survive:
/*
* If for any reason at all we couldn't handle the fault,
* make sure we exit gracefully rather than endlessly redo
* the fault.
*/
switch (handle_mm_fault(mm, vma, address, write)) {
case VM_FAULT_MINOR:
tsk->min_flt++;
break;
case VM_FAULT_MAJOR:
tsk->maj_flt++;
break;
case VM_FAULT_SIGBUS:
goto do_sigbus;
case VM_FAULT_OOM:
goto out_of_memory;
default:
BUG();
}
/*
* Did it hit the DOS screen memory VA from vm86 mode?
*/
if (regs->eflags & VM_MASK) {
unsigned long bit = (address - 0xA0000) >> PAGE_SHIFT;
if (bit < 32)
tsk->thread.screen_bitmap |= 1 << bit;
}
up_read(&mm->mmap_sem);
return;
/*
* Something tried to access memory that isn't in our memory map..
* Fix it, but check if it's kernel or user first..
*/
bad_area:
up_read(&mm->mmap_sem);
bad_area_nosemaphore:
/* User mode accesses just cause a SIGSEGV */
if (error_code & 4) {
/*
* Valid to do another page fault here because this one came
* from user space.
*/
if (is_prefetch(regs, address, error_code))
return;
tsk->thread.cr2 = address;
/* Kernel addresses are always protection faults */
tsk->thread.error_code = error_code | (address >= TASK_SIZE);
tsk->thread.trap_no = 14;
force_sig_info_fault(SIGSEGV, si_code, address, tsk);
return;
}
#ifdef CONFIG_X86_F00F_BUG
/*
* Pentium F0 0F C7 C8 bug workaround.
*/
if (boot_cpu_data.f00f_bug) {
unsigned long nr;
nr = (address - idt_descr.address) >> 3;
if (nr == 6) {
do_invalid_op(regs, 0);
return;
}
}
#endif
no_context:
/* Are we prepared to handle this kernel fault? */
if (fixup_exception(regs))
return;
/*
* Valid to do another page fault here, because if this fault
* had been triggered by is_prefetch fixup_exception would have
* handled it.
*/
if (is_prefetch(regs, address, error_code))
return;
/*
* Oops. The kernel tried to access some bad page. We'll have to
* terminate things with extreme prejudice.
*/
bust_spinlocks(1);
if (oops_may_print()) {
#ifdef CONFIG_X86_PAE
if (error_code & 16) {
pte_t *pte = lookup_address(address);
if (pte && pte_present(*pte) && !pte_exec_kernel(*pte))
printk(KERN_CRIT "kernel tried to execute "
"NX-protected page - exploit attempt? "
"(uid: %d)/n", current->uid);
}
#endif
if (address < PAGE_SIZE)
printk(KERN_ALERT "BUG: unable to handle kernel NULL "
"pointer dereference");
else
printk(KERN_ALERT "BUG: unable to handle kernel paging"
" request");
printk(" at virtual address %08lx/n",address);
printk(KERN_ALERT " printing eip:/n");
printk("%08lx/n", regs->eip);
}
page = read_cr3();
page = ((unsigned long *) __va(page))[address >> 22];
if (oops_may_print())
printk(KERN_ALERT "*pde = %08lx/n", page);
/*
* We must not directly access the pte in the highpte
* case, the page table might be allocated in highmem.
* And lets rather not kmap-atomic the pte, just in case
* it's allocated already.
*/
#ifndef CONFIG_HIGHPTE
if ((page & 1) && oops_may_print()) {
page &= PAGE_MASK;
address &= 0x003ff000;
page = ((unsigned long *) __va(page))[address >> PAGE_SHIFT];
printk(KERN_ALERT "*pte = %08lx/n", page);
}
#endif
tsk->thread.cr2 = address;
tsk->thread.trap_no = 14;
tsk->thread.error_code = error_code;
die("Oops", regs, error_code);
bust_spinlocks(0);
do_exit(SIGKILL);
/*
* We ran out of memory, or some other thing happened to us that made
* us unable to handle the page fault gracefully.
*/
out_of_memory:
up_read(&mm->mmap_sem);
if (tsk->pid == 1) {
yield();
down_read(&mm->mmap_sem);
goto survive;
}
printk("VM: killing process %s/n", tsk->comm);
if (error_code & 4)
do_exit(SIGKILL);
goto no_context;
do_sigbus:
up_read(&mm->mmap_sem);
/* Kernel mode? Handle exceptions or die */
if (!(error_code & 4))
goto no_context;
/* User space => ok to do another page fault */
if (is_prefetch(regs, address, error_code))
return;
tsk->thread.cr2 = address;
tsk->thread.error_code = error_code;
tsk->thread.trap_no = 14;
force_sig_info_fault(SIGBUS, BUS_ADRERR, address, tsk);
}
do_page_fault()函数接收以下输入参数:
- pt_regs结构的地址regs,该结构包含当异常发生时的微处理器寄存器的值。
- 3位的error_code,当异常发生时由控制单元压入栈中(参见第四章中的“中断和异常的硬件处理”一节)。这些位有以下含义:
—— 如果第0位被清0,则异常由访问一个不存在的页所引起(页表项中的Present标志被清0);否则,如果第0位被设置,则异常由无效的访问权限所引起。
—— 如果第1位被清0,则异常由读访问或者执行访问所引起;如果该位被设置,则异常由写访问所引起。
—— 如果第2位被清0,则异常发生在处理器处于内核态时;否则,异常发生在处理器处于用户态时。
* bit 3 == 1 means use of reserved bit detected
* bit 4 == 1 means fault was an instruction fetch
do_page_fault()的第一步操作是读取引起缺页的b线性地址b(address = read_cr2();)。当异常发生时,CPU控制单元把这个值存放在cr2控制寄存器中:
#define read_cr2() ({ /
unsigned int __dummy; /
__asm__ __volatile__( /
"movl %%cr2,%0/n/t" /
:"=r" (__dummy)); /
__dummy; /
})
函数将这个线性地址保存在address局部变量中,并把指向current进程描述符的指针保存在tsk局部变量中(tsk = current;)。
对比那个纷繁复杂的图的顶部所示,函数首先检查引起缺页的线性地址是否属于内核空间,即是否是第3GB~4GB之间:
si_code = SEGV_MAPERR;
if (unlikely(address >= TASK_SIZE)) { /* 0xd = 1101 */
if (!(error_code & 0x0000000d) && vmalloc_fault(address) >= 0)
return;
if (notify_page_fault(DIE_PAGE_FAULT, "page fault", regs, error_code, 14,
SIGSEGV) == NOTIFY_STOP)
return;
goto bad_area_nosemaphore;
}
如果发生了由于内核试图访问不存在的页框引起的异常,就去执行vmalloc_fault(address)函数,该部分代码处理可能由于在内核态访问非连续内存区而引起的缺页,我们在“处理非连续内存区访问”博文中对此进行说明;如果是DIE_PAGE_FAULT异常,就去执行notify_page_fault异常处理函数;否则就跳转去执行bad_area_nosemaphore标记处的代码,我们在“处理地址空间以外的错误地址”博文将对此进行说明。
随后,再检查一下是否产生了DIE_PAGE_FAULT异常,如果是就去执行notify_page_fault异常处理函数。
如果缺页发生之前或CPU运行在虚拟8086模式时就打开了本地中断,那么该函数还要确保本地中断打开:
if (regs->eflags & (X86_EFLAGS_IF|VM_MASK))
local_irq_enable();
接下来,缺页处理程序检查异常发生时是否内核正在执行一些关键例程或正在运行内核线程(回想一下,对内核线程而言,进程描述符的mm字段总为NULL):
if (in_atomic() || !mm)
goto bad_area_nosemaphore;
这里简单介绍一下,如果缺页发生在下面任何一种情况下,则in_atomic()宏产生等于1的值:
- 内核正在执行中断处理程序或可延迟函数。
- 内核正在禁用内核抢占的情况下执行临界区代码。
如果缺页的确发生在中断处理程序、可延迟函数、临界区或内核线程中,do_page_fault()就不会试图把这个线性地址与current的线性区做比较。再一个,内核线程从来不使用小于TASK_SIZE的地址。同样,中断处理程序、可延迟函数和临界区代码也不应该使用小于TASK_SIZE的地址,因为这可能导致当前进程的阻塞。当然,后面bad_area_nosemaphore的内容我们会在后面的博客详细讨论。
现在,让我们假定缺页没有发生在中断处理程序、可延迟函数、临界区或者内核线程中。于是函数必须检查进程所拥有的线性区以决定引起缺页的线性地址是否包含在进程的地址空间中,为此必须获得进程的mmap_sem读/写信号量:
if (!down_read_trylock(&mm->mmap_sem)) {
if ((error_code & 4) == 0 &&
!search_exception_tables(regs->eip))
goto bad_area_nosemaphore;
down_read(&mm->mmap_sem);
}
如果内核bug和硬件故障有可能被排除,那么当缺页发生时,当前进程就不会有为写而获得信号量mmap_sem。尽管如此,do_page_fault()还是想确定的确没有获得这个信号量,因为如果不是这样就会发生死锁。所以,函数使用down_read_trylock()而不是down_read()。
如果这个信号量被关闭而且缺页发生在内核态(error_code & 4),do_page_fault()就要确定异常发生的时候,是否正在使用作为系统调用参数被传递给内核的线性地址。此时,因为每个系统调用服务例程都小心地避免在访问用户态地址空间以前为写而获得mmap_sem信号量,所以do_page_fault()确信mmap_sem信号量由另外一个进程占有了(!search_exception_tables(regs->eip)),从而do_page_fault()一直等待直到该信号量被释放(down_read(&mm->mmap_sem))。否则,如果缺页是由于内核bug或严重的硬件故障引起的,函数就跳转到bad_area_nosemaphore标记处。
我们假设已经为读而获得了mmap_sem信号量。现在,do_page_fault()开始搜索错误线性地址所在的线性区:
vma = find_vma(mm, address);
if (!vma)
goto bad_area;
if (vma->vm_start <= address)
goto good_area;
if (!(vma->vm_flags & VM_GROWSDOWN))
goto bad_area;
如果vma为NULL,说明address之后没有线性区,因此这个错误的地址肯定是无效的。另一方面,如果在address之后结束处的第一个线性区包含address,则函数跳到标记为good_area的代码处。
如果两个“if”条件都不满足,则函数就确定address没有包含在任何线性区中,但内部变量vma指向当前进程的mm_struct的mmap_cache指向的那个vm_area_struct。函数就执行进一步的检查,由于这个错误地址可能是由push或pusha指令在进程的用户态堆栈上的操作所引起的。
我们稍微离题一点,解释一下栈是如何映射到线性区上的。每个向低地址扩展的栈所在的区,它的VM_GROWSDOWN标志被设置,这样,当vm_start字段的值可能被减小的时候,而vm_end字段的值保持不变。这种线性区的边界包括、但不严格限定用户态堆栈当前的大小。这种细微的差别主要基于以下原因:
- 线性区的大小是4KB的倍数(必须包含完整的页),而栈的大小却是任意的。
- 分配给一个线性区的页框在这个线性区被删除前永远不被释放。尤其是,一个栈所在线性区的vm_start字段的值只能减小,永远也不能增加。甚至进程执行一系列的pop指令时,这个线性区的大小仍然保持不变。
现在这一点就很清楚了,当进程填满分配给它的堆栈的最后一个页框后,进程如何引起一个“缺页”异常——push引用了这个线性区以外的一个地址(即引用一个不存在的页框)。注意,这种异常不是由程序错误引起的,因此它必须由缺页处理程序单独处理。
我们现在回到对do_page_fault()的描述,它检查上面所描述的情况:
if (error_code & 4) {
if (address + 65536 + 32 * sizeof(unsigned long) < regs->esp)
goto bad_area;
}
if (expand_stack(vma, address))
goto bad_area;
如果线性区的VM_GROWSDOWN标志被设置,并且异常发生在用户态,函数就要检查address是否小于regs->esp栈指针的值(它应该只小于一点点)。因为几个与栈相关的汇编语言指令(如pusha)只有在访问内存之后才执行减esp寄存器的操作,所以允许进程有32字节的后备区间。如果这个地址足够高(在允许的范围内),则代码调用espand_stack()函数检查是否允许进程既扩展它的栈也扩展它的地址空间。如果一切都可以,expand_stack就把vma的vm_start字段设为address,并返回0;否则,expand_stack返回-ENOMEM。
注意:只要线性区的VM_GROWSDOWN标志被设置,但异常不是发生在用户态,上述代码就跳过容错检查。这些条件意味着内核正在访问用户态的栈,也意味着这段代码总是应当运行expand_stack()。