http://www.gdcvault.com/play/1014350/Mega-Meshes-Modeling-Rendering-and
全名太长了:MegaMeshes modeling, rendering and lighting a world made of 100 billion polygons
简直是一个微博。
作者是lionhead的一个team的lead programmer, lionhead studio开发了fable和black&white系列的强力工作室。
介绍他们给《milo&kate》开发的游戏(milo真大牌,有人专门给开发游戏)
整篇文章看下来感觉挺不爽的,压缩到1/3还差不多,太长了而且有意思的信息密度非常小。
很多大家都熟知的东西还特大篇幅介绍。
MegaMeshes
paper从美术风格开始讲起,这个我很喜欢,程序员就是应该有更好的一个视野。
m&k是走一个小可爱的闷骚路线,polygon的形状很简单,却希望有很大的规模和高质量的lighting。
给人感觉很童话。

为了很好的达到这一点,这帮哥们来了个有意思的想法,让artist像雕塑一样工作,而不是create geometry, create 2d texture, 然后map上去。
而是直接在geometry上精雕细琢然后着色,着色就在vertex,需要更细致就把polygon细分,不用texture。
做完这一点之后,工具自动从高精模型上抽取出diffuse map, normal map等, 就和normal mapping产生的方法比较类似。
这个会进一步解放artist的创作力和生产力。
对于整个world,他们希望整个world放在一起来雕琢,当然实际程序中还是要分cluster,但是给artist感觉是浑然一体的。
但是这样一来,一个level就会有10billion级别的polygon,所以就需要一个solution来搞定这些,也就是mega mesh tool。
从mega mesh这个名字也能看出来会使用类似mega texture的方式来存储,在使用的时候这么大数量的polygon是没法存的,
具体存储和使用的时候会有hierarchy的概念,根据需求load不同的level。
高精度的部分是按照低精度模型顶点加delta的方式来存的,低精度和高精度模型之间有关系的,也就是说修改低精度模型会直接导致高精度模型的update(nice!)。
virtual texture
mesh都mega了,texture不mega有点说不过去了。
贴图压缩
mega tex会导致数据量很大,十几g是小case,需要好好压一压。
常用的一切都不给力,
dxt的压缩率不行
jpeg的quality不行(blocky)
最后用的是microsoft research 的Rico Malvar的ptc算法。
http://research.microsoft.com/apps/pubs/?id=101991
结果惊人:
- normal compression ptc:40:1, dxn:3:1
- albedo compression ptc:60:1, dxt: 6:1
但是在其他情况就不知道了,因为这些算法的压缩方式都是很挑源数据,有的就很好,有的一般,正好被lionhead赶上了,结果非常强力。
albedo texture
这里利用人眼的一个特点,就是对brightness敏感,对颜色不够敏感,所以使用YCoCg space是一个(luminance,orange,green)这样的组合。然后对orang和green进行ptc encoding压缩。
解压缩的时候就是生成dxt格式的贴图。
结果给出来是:769k:37k==大约20倍的压缩率。
frame analyze
分析场景需要那些贴图,lionhead使用把场景render一下,render不带贴图,而且输出的是texture的uv,cpu端读取这个render target就知道那些tile的texture是需要的了。
虽然看起来问题多多,但是用起来还很不错的。
流程上是3thread的协同工作,render thread在产生drawcall, virtual tex thread负责texture loading的工作,gpu就render。
这里就是gpu 的pipeline要尽可能的先做其他工作把需求virtual texture loading的部分mask掉。
整个协同上使用fence这些element来同步,fence被gpu consume的时候会向cpu端发event或者callback一些function,导致向virtual tex thread插入一些command, command的执行就是load in texture。
这些load进来的texture都是用来下一帧render的,所以相对还是有空间来load和lock的。
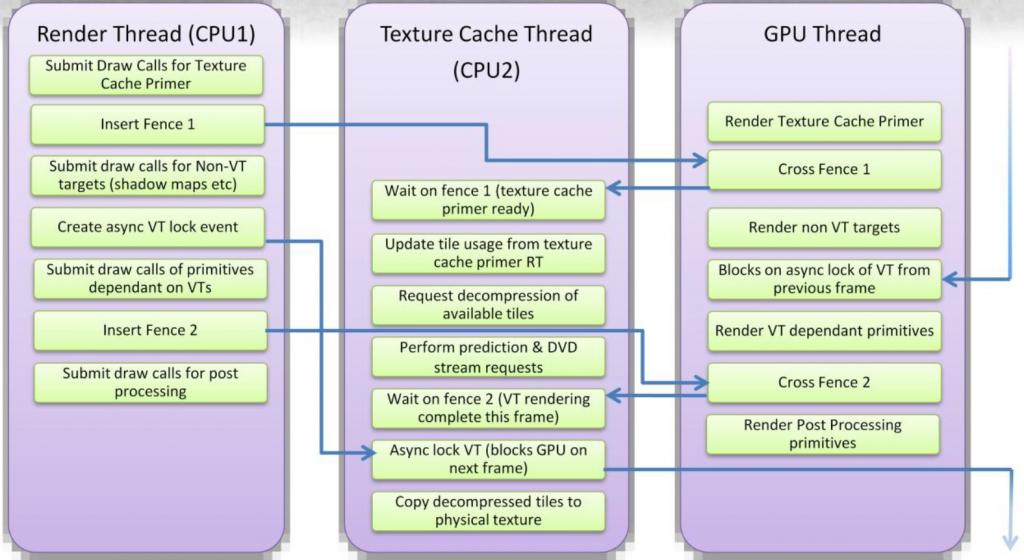
texture cache上也传承了传统cache的一些机制,space/temp locality。
lighting
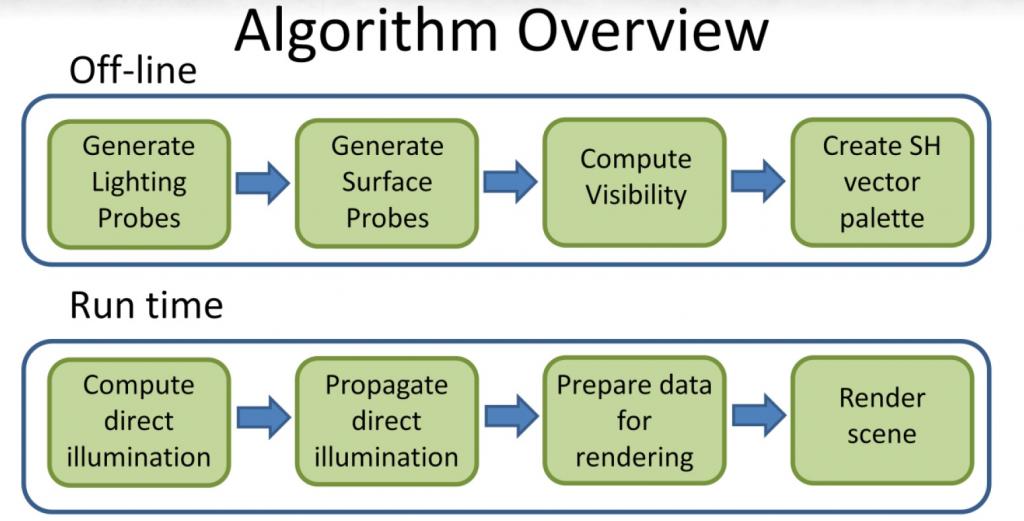
算是realtime gi,但是现在这个词太唬人了,其实只是对常用的indirect lighting做一些调整。
使用spherical harmonics系数存储lighting信息,有lighting propagation过程。
用lookup table来存储sh系数,进而压缩算是一个亮点。
算法效率不高,只能适合小场景,干脆老老实实follow crytek用light propagation volume算了啊。