http://goog-perftools.sourceforge.net/doc/tcmalloc.html
作者: Sanjay Ghemawat, Paul Menage <opensource@google.com>
动机
TCMalloc要比glibc 2.3中的malloc(所在库为ptmalloc2),以及我测试过的其他版本的malloc要快。在2.8 GHz P4机器上,ptmalloc2大约需要300纳秒完成一对malloc/free操作。而TCMalloc实现相同的操作只需要50纳秒。在执行malloc的时候,速度是非常重要的,如果malloc的速度不是足够快,那么应用程序程序员更倾向于将数据写到他们自己定制的在malloc上层的空闲链表中。这种行为会带来额外的复杂度,会使用更多的内存资源,除非应用程序程序员非常小心的使用空闲的链表并且及时将无效数据从链表中清理出去以回收链表。
在多线程程序中,TCMalloc会减少锁的争夺。对于小对象来说,TCMalloc对锁的争用几乎为0。对于大对象,TCMalloc使用细粒度的高效的自旋锁来提高效率。ptmalloc2采用的使用arena-per-thread(每个线程单独的存储空间)的方法也能减少锁的争用。但是ptmalloc2的这种方法存在着很大的问题。ptmalloc2中的内存空间不能从某一块地址空间迁移到另一块。这样会导致大量的内存资源浪费。例如,在google的某一应用中,第一阶段为其数据结构分配了大约300MB的内存。当第一阶段结束后,第二阶段将会在相同的地址空间启动。如果第二阶段被指配到与第一阶段不同的内存空间,则该阶段无法重用第一阶段结束后的内存,导致其会在新的地址空间再次分配300MB的内存,造成了浪费。相似的内存浪费也在其他的应用中存在。
使用TCMalloc的另一个优势是在内存中紧凑的存储小对象。例如, N倍8-byte的对象在内存中分配,将会占用大概8N bytes的内存空间,仅仅额外占用了百分之1的头部内存空间。而ptmalloc2会为分配每一个对象使用4-byte的头空间,并且(我认为)按照8-byte的倍数来对齐内存,最终会使用
* 1.0116N bytes的头空间。
使用
$ LD_PRELOAD="/usr/lib/libtcmalloc.so"
我们不是很推荐使用LD_PRELOAD这种小技巧。TCMalloc同样包括heap checker 与heap
profiler。
如果你希望链接到不包括heap profiler以及checker的TCMalloc版本,你可以链接到libtcmalloc_minimal来实现。
综述
TCMalloc为每个线程分配线程本地缓存,可以满足小块的数据分配。当需要的时候,对象可以从中央数据结构移动到
线程本地缓存,而周期性的垃圾收集机制会将内存从各个线程本地缓存聚集到中央数据结构。

TCMalloc对待大小小于32KB(小对象)的对象与对待大对象的处理方式是不同的。大对象会直接从中央的堆分配器通
过页级别的分配器来分配。例如,一个大对象总是按照页对齐,并且占据页整数倍的内存空间。
小对象分配
每个小对象的大小将会映射到170个指定的不同大小的空间集合中。例如,所有961到1024bytes的内存分配请求,均
会映射到1024。不同大小的集合都是被分割开的,所以小空间被8bytes分隔,大一些的被16bytes分隔,更大一些
的被32bytes分隔,以此类推。最大的空间为256bytes。
每个线程缓存包括一个不同大小的对象分别连接到一起的链表。
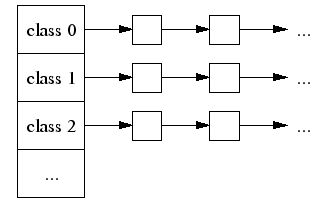
当需要分配一个小对象时:(1)我们映射其大小到对应的空间集合中。(2)查找当前线程缓存中对应的未分配的链。(3)如果空闲的链非空,我们从中取出第一个对象并返回给调用者。当这样快速的获取空间时,TCMalloc根本不需要锁,加锁和解锁这一对操作在2.8 GHz Xeon处理器上会占用100纳秒的时间,因此这样的机制可以很有效的加速内存分配的效率。当空闲的内存对象链为空时:(1)我们从中央空闲链中取出一些对象填充到对应的集合中(中央空闲链是所有线程共享的)。(2)将他们放到线程本地的空闲链中。(3)返回这些新取的对象中的一个给应用程序。
大对象分配
一个大对象的大小(大于32K)要向上按照页大小(4K)对齐,并且是由中央的页面堆来处理。中央页面堆同样也是由一些不同大小的元素的链表组成的数组。对于i小于256,数组中第k的入口,是由k个页组成的元素所链接在一起的空闲链表。第256个入口是由长度大于256个页链接在一起的空闲链表。

一个需要k个页面大小的分配请求,可以通过访问第k个空闲链表来满足。如果该空闲链表为空,我们就访问下一个空闲链表(页面大一些的),以此类推。最终,如果需要的话我们会访问最后一个空闲链。如果这一系列的查找都失败的话,我们将从系统中得到内存(使用sbrk,mmap或者通过映射一部分/dev/mem)。如果一个k页面大小的分配请求分配到的内存空间大于k个页面,当该空间释放的时候需要放回到页面堆中相应大小的空闲链表中。
Spans
Tmalloc中的堆管理机制是将其组成一些页面的集合。一组连续的页面被称为一个span对象。一个span对象既可以被分配也可以被释放。如果被释放,span将会被放到对应的页面堆链表。如果被分配,span可以是一个交给应用程序的大对象,或者是一组被分割成连续小对象的页面。如果是被分割成为小对象,那么在span中会记录对象的大小级别。
中央数组的页号索引,能够用于实现找到一个Span由哪些页面组成。举例来说,下图的span a占有2个页面,spanb占有1个页面,span c占有5个页面,而span d占有3个页面。
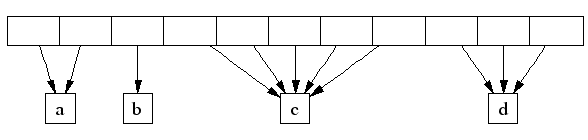
一个32位的地址空间能够分配2^20个4K的页面,因此中央数组占据4MB的内存空间是可以令人接受的。在64位的机器上,我们使用3级的基树来代替数组,用于映射页号与对应的span指针。
释放
当一个对象释放的时候,我们计算其页号,然后在中央数组中查找其对应的span对象。span对象中的信息能够告诉我们要释放的对象是否是小对象,若是小对象的话还会得知其对象的大小级别。
如果是小对象,我们将其放回到当前线程的线程缓存所属的对应的空闲链表中。如果线程的缓存以及超过了预定的大小(默认2MB),我们会运行一个垃圾收集器去收集该线程缓存中不使用的对象,将他们放到中央空闲链表中。
如果要释放的对象是大对象,span信息会告诉我们该对象所覆盖的页的范围。假设这个范围是[p,q],我们查找页号p-1和q+1所在的span,若这俩邻居span是空闲的,我们将他们与[p,q]合并在一起。最后将所得的span放到页堆中对应的空闲链表中。
用于小对象的中央空闲链
前面的内容提到过,我们的中央空闲链覆盖了每一个大小级别的对象。每一个中央空闲链都由2级数据结构组成:一组span,以及每个span中由空闲对象组成的链表。
从中央空闲链分配对象,是通过移动从某个span的链表移动第一个对象实现的。若所有span都有空闲链表,那么中央页堆首选大小合适的span去分配。
一个对象返回到中央空闲链,是通过将其挂到span所属的链表中实现的。若链表的长度与span中所有的小对象的个数完全相等,该span是完全空闲的,并且需要返回到页堆中。
线程缓存的垃圾收集
当线程缓存中所有对象的大小加起来超过2MB时,需要对其进行垃圾收集。随着线程数目的增多,垃圾收集的阈值是会自动减少的,因此在存在大量内存的时候,我们的程序不会浪费过量的内存。
我们遍历缓存中的所有空闲链表,从中移动一定数量的对象到对应的中央链表中。每个链的低水位标记L决定了从空闲链中移出对象的数量。L记录了自从上一次垃圾收集操作之后本链的最小长度。注意我们可以缩短链的长度,通过在前一次垃圾收集时移走L个对象,并且没有从中央链中获取其他对象。我们使用这个过去的记录来预测未来的情况,从线程缓存中移走L/2个对象到中央链中。这个算法性能良好,如果一个线程停止使用某个特定大小的对象,该大小的所有对象将会很快的从线程缓存中迁移到中央空闲链中,以便被其他线程来使用。
NOTE: 后面都是测试的相关信息 可以自己去看测试结果 总的来说测试结果是很棒的。