享元模式(Flyweight Pattern)
——.NET设计模式系列之十三
Terrylee,2006年3月
摘要:面向对象的思想很好地解决了抽象性的问题,一般也不会出现性能上的问题。但是在某些情况下,对象的数量可能会太多,从而导致了运行时的代价。那么我们如何去避免大量细粒度的对象,同时又不影响客户程序使用面向对象的方式进行操作?
本文试图通过一个简单的字符处理的例子,运用重构的手段,一步步带你走进Flyweight模式,在这个过程中我们一同思考、探索、权衡,通过比较而得出好的实现方式,而不是给你最终的一个完美解决方案。
主要内容:
1. Flyweight模式解说
2..NET中的Flyweight模式
3.Flyweight模式的实现要点
……
概述
面向对象的思想很好地解决了抽象性的问题,一般也不会出现性能上的问题。但是在某些情况下,对象的数量可能会太多,从而导致了运行时的代价。那么我们如何去避免大量细粒度的对象,同时又不影响客户程序使用面向对象的方式进行操作?
意图
运用共享技术有效地支持大量细粒度的对象。[GOF 《设计模式》]
结构图
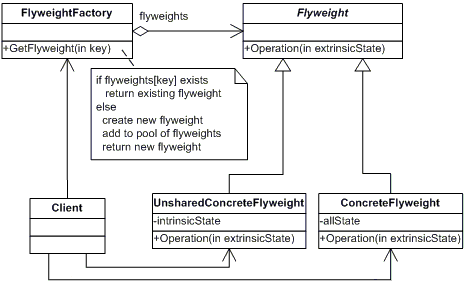
图1 Flyweight模式结构图
生活中的例子
享元模式使用共享技术有效地支持大量细粒度的对象。公共交换电话网(PSTN)是享元的一个例子。有一些资源例如拨号音发生器、振铃发生器和拨号接收器是必须由所有用户共享的。当一个用户拿起听筒打电话时,他不需要知道使用了多少资源。对于用户而言所有的事情就是有拨号音,拨打号码,拨通电话。
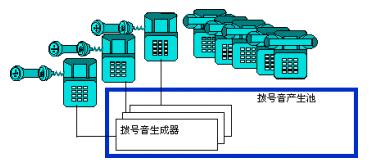
图2 使用拨号音发生器例子的享元模式对象图
Flyweight模式解说
Flyweight在拳击比赛中指最轻量级,即“蝇量级”,这里翻译为“享元”,可以理解为共享元对象(细粒度对象)的意思。提到Flyweight模式都会一般都会用编辑器例子来说明,这里也不例外,但我会尝试着通过重构来看待Flyweight模式。考虑这样一个字处理软件,它需要处理的对象可能有单个的字符,由字符组成的段落以及整篇文档,根据面向对象的设计思想和Composite模式,不管是字符还是段落,文档都应该作为单个的对象去看待,这里只考虑单个的字符,不考虑段落及文档等对象,于是可以很容易的得到下面的结构图:

图3
示意性实现代码:
 // "Charactor"public abstract class Charactor
// "Charactor"public abstract class Charactor

 {
{ //Fields protected char _symbol; protected int _width; protected int _height; protected int _ascent; protected int _descent; protected int _pointSize; //Method public abstract void Display();
//Fields protected char _symbol; protected int _width; protected int _height; protected int _ascent; protected int _descent; protected int _pointSize; //Method public abstract void Display(); }// "CharactorA"public class CharactorA : Charactor{ // Constructor public CharactorA()
}// "CharactorA"public class CharactorA : Charactor{ // Constructor public CharactorA()
 { this._symbol = 'A'; this._height = 100; this._width = 120; this._ascent = 70; this._descent = 0; this._pointSize = 12;
{ this._symbol = 'A'; this._height = 100; this._width = 120; this._ascent = 70; this._descent = 0; this._pointSize = 12; } //Method public override void Display() { Console.WriteLine(this._symbol); }}// "CharactorB"public class CharactorB : Charactor{ // Constructor public CharactorB() { this._symbol = 'B'; this._height = 100; this._width = 140; this._ascent = 72; this._descent = 0; this._pointSize = 10; } //Method public override void Display() { Console.WriteLine(this._symbol); }}// "CharactorC"public class CharactorC : Charactor{ // Constructor public CharactorC() { this._symbol = 'C'; this._height = 100; this._width = 160; this._ascent = 74; this._descent = 0; this._pointSize = 14; } //Method public override void Display() { Console.WriteLine(this._symbol); }}
} //Method public override void Display() { Console.WriteLine(this._symbol); }}// "CharactorB"public class CharactorB : Charactor{ // Constructor public CharactorB() { this._symbol = 'B'; this._height = 100; this._width = 140; this._ascent = 72; this._descent = 0; this._pointSize = 10; } //Method public override void Display() { Console.WriteLine(this._symbol); }}// "CharactorC"public class CharactorC : Charactor{ // Constructor public CharactorC() { this._symbol = 'C'; this._height = 100; this._width = 160; this._ascent = 74; this._descent = 0; this._pointSize = 14; } //Method public override void Display() { Console.WriteLine(this._symbol); }}好了,现在看到的这段代码可以说是很好地符合了面向对象的思想,但是同时我们也为此付出了沉重的代价,那就是性能上的开销,可以想象,在一篇文档中,字符的数量远不止几百个这么简单,可能上千上万,内存中就同时存在了上千上万个Charactor对象,这样的内存开销是可想而知的。进一步分析可以发现,虽然我们需要的Charactor实例非常多,这些实例之间只不过是状态不同而已,也就是说这些实例的状态数量是很少的。所以我们并不需要这么多的独立的Charactor实例,而只需要为每一种Charactor状态创建一个实例,让整个字符处理软件共享这些实例就可以了。看这样一幅示意图:

图4
现在我们看到的A,B,C三个字符是共享的,也就是说如果文档中任何地方需要这三个字符,只需要使用共享的这三个实例就可以了。然而我们发现单纯的这样共享也是有问题的。虽然文档中的用到了很多的A字符,虽然字符的symbol等是相同的,它可以共享;但是它们的pointSize却是不相同的,即字符在文档中中的大小是不相同的,这个状态不可以共享。为解决这个问题,首先我们将不可共享的状态从类里面剔除出去,即去掉pointSize这个状态(只是暂时的J),类结构图如下所示:
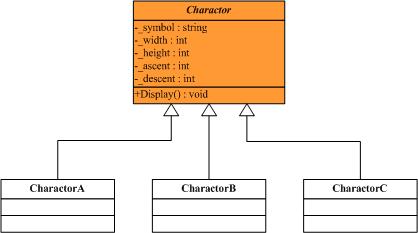
图5
示意性实现代码:
// "Charactor"public abstract class Charactor{ //Fields protected char _symbol; protected int _width; protected int _height; protected int _ascent; protected int _descent; //Method public abstract void Display();}// "CharactorA"public class CharactorA : Charactor{ // Constructor public CharactorA() { this._symbol = 'A'; this._height = 100; this._width = 120; this._ascent = 70; this._descent = 0; } //Method public override void Display() { Console.WriteLine(this._symbol); }}// "CharactorB"public class CharactorB : Charactor{ // Constructor public CharactorB() { this._symbol = 'B'; this._height = 100; this._width = 140; this._ascent = 72; this._descent = 0; } //Method public override void Display() { Console.WriteLine(this._symbol); }}// "CharactorC"public class CharactorC : Charactor{ // Constructor public CharactorC() { this._symbol = 'C'; this._height = 100; this._width = 160; this._ascent = 74; this._descent = 0; } //Method public override void Display() { Console.WriteLine(this._symbol); }}
好,现在类里面剩下的状态都可以共享了,下面我们要做的工作就是控制Charactor