前面发了两篇内排序的文章。(一)中当时归并排序并没有写出,(二)中今天发现在非递归quickSort中stack<node*> 存在内存泄露,并且主程序选项功能支持不是很好,所以今天又练习写了一遍。
大规模排序时,发现1million整形数据大小为6.8M,int在当前平台占4B
1million = 1000000 = 106 ≈220 总容量=4B*220 =4M≈6.8M,因为这里面还有空格、回车还有文件自身的一些信息占容量。100million数据大小为673M,1billion数据大小为6.6G。各种文件系统大小限制在下有说明。当前系统最大申请内存可达400G。
C/C++源码:sort.cpp
功能:七种常见内排序算法
C/C++源码:data.cpp
功能:随机生成一定规模的随机数据
运行结果:
数据规模10无序数据集,迭代1W次
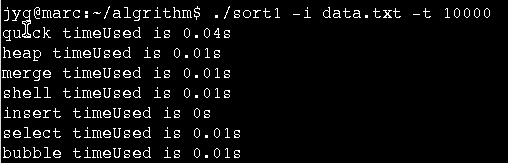
数据规模100有无序数据集,迭代1024次
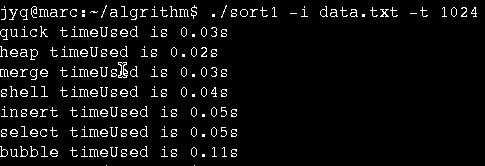
数据规模100有序数据集,迭代1024次
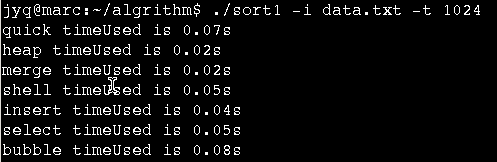
数据规模10W无序数据集
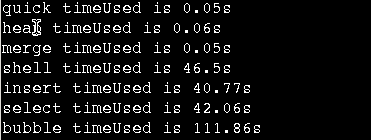
数据规模10W有序数据集(注意quickSort性能下降)
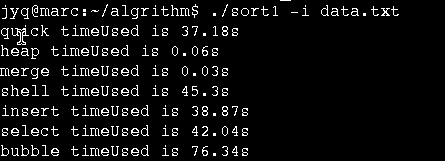
数据规模100W无序数据集

1Billion无序数据集(quick,heap,merge,其它O2的方法已经淘汰)
注意在小规模如果数据集全部可以装入内存,不考虑换页影响的话,三种排序时间复杂度都是O(nlgn),其中数据显示快排是时间最快,归并时间与其差不多,堆排慢于其它两种方法,大概是1.5倍关系。但是当10亿数据,内存容量约为4G。快排与堆排需要遍历遍历整个数组,会造成颠簸,而归并的性质决定了它每次处理的数据有很强的局部性,不会很大颠簸,所以归并排比其它两种性能提高数倍。

NTFS(Windows):支持最大分区2TB,最大文件2TB
FAT16(Windows):支持最大分区2GB,最大文件2GB
FAT32(Windows):支持最大分区128GB,最大文件4GB
Ext2
最大文件大小: 1TB
最大文件极限: 仅受文件系统大小限制
最大分区/文件系统大小: 4TB
最大文件名长度: 255 字符
缺省最小/最大块大小: 1024/4096 字节
缺省inode分配: 每4096字节为1
在强制FS检查前的最大装载: 20(可配置)
//REDHAT9默认是ext3的文件系统
Ext3
最大文件大小: 1TB
最大文件极限: 仅受文件系统大小限制
最大分区/文件系统大小: 4TB
最大文件名长度: 255 字符
缺省最小/最大块大小: 1024/4096 字节
缺省inode分配: 每4096字节为1
在强制FS检查前的最大装载: 20(可配置)
ReiserFS
最大文件大小: 1TB
最大文件极限: 32k目录,42亿文件
最大分区/文件系统大小: 4TB
最大文件名长度: 255 字符
JFS
最小文件系统大小 16 MB
最大文件大小: 受体系结构限制
最大文件极限: 受文件系统大小限制
缺省最小/最大块大小: 1024/4096 字节
缺省inode分配: 动态