本文由larrylgq编写,转载请注明出处:http://blog.csdn.net/larrylgq/article/details/7399237
作者:吕桂强
当我们的数据大到一定的程度,无法通过RDBMS来处理时一般的做法是使用RPC/http+索引服务器+数据库来实现
通常的做法是:
使用cron等定期到数据库拉取数据,传输到索引服务器,索引服务器会创建到排索引,而业务机通过RPC/http来访问索引服务器,直接进行关键字模糊匹配消耗是惊人的,所以
一般都会进行关键字的前缀冗余,正常我们看到的进行关键字前缀冗余的做法是通过Trie树(Aho-Corasick算法)等来实现。
这个算法的好处就是
1:将公共前缀合在一起,避免空间浪费
2:计算量最大为树的广度*搜索单词的长度
但是为了进行实时搜索trie树还是太慢了,我们需要一种更快的找到匹配关键字的方法:哈希加链表
当存储关键字的时候,对关键字进行前缀冗余并排序存放如:
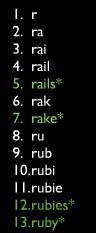
这样当我们可以快速的通过hash值找到用户输入值的位置,在这个基础上向下查找既可以找到匹配的关键字
*有关hash的介绍http://blog.csdn.net/larrylgq/article/details/7383527
但是相比Trie来说也有一个缺点就是存储空间会变大