0.简介
FastDFS是基于互联网应用的开源分布式文件系统,主要用于大中型网站存储资源文件,如图片、文档、音频、视频等。FastDFS采用类似GFS的架构,用纯C语言实现,支持Linux、FreeBSD、AIX等UNIX 系统。用户端只能通过专有API对文件进行存取访问,不支持POSIX接口方式。准确地讲,GFS以及 FastDFS、mogileFS、HDFS、TFS等类GFS系统都不是系统级的分布式文件系统,而是应用级的分布式文件存储服务。
1.特点
FastDFS主要解决了大容量的文件(主要是图片、视频、音频等小文件)存储和高并发访问的问题,并在文件存取时实现了负载均衡。与其它类GFS系统相比,FastDFS最大的特点在于它是一个轻量级的系统,体现在以下几个方面。
首先,FastDFS的结构比较简单,主要由Client、Tracker server和Storage server三部分组成。Client通过Tracker server得到Storage server的信息,然后直接与Storage server通信访问文件,避免了Tracker server成为瓶颈。
第二,FastDFS不对文件进行分块存储,与支持文件分块存储的DFS相比,更加简洁高效。
第三,FastDFS中的文件ID是由Storage server生成后返回给客户端的。文件ID中包含了Volume号、文件相对路径和文件名等(文件ID中还包含文件大小、时间戳、源Storage server IP地址、文件内容校验码、随机数等),client可以根据文件ID直接定位到文件所在的Volume(但具体通过哪个Storage server下载需要询问Tracker server根据负载均衡原则指定)。因此FastDFS不需要存储文件索引信息。而其他文件系统则通常需要由NameServer存储文件索引信息,如mogileFS采用MySQL数据库来存储文件索引以及系统相关的信息,而MySQL很容易成为系统瓶颈。
FastDFS轻量级的另外一个体现是代码量较小,FastDFS-V2.0的代码行数不到5.2万行(其实TFS更小。。。tfs-1.3约为4.2万行)。
2.结构组成
FastDFS的基本结构如图,主要由三部分组成:Client、Tracker server和Storage server。
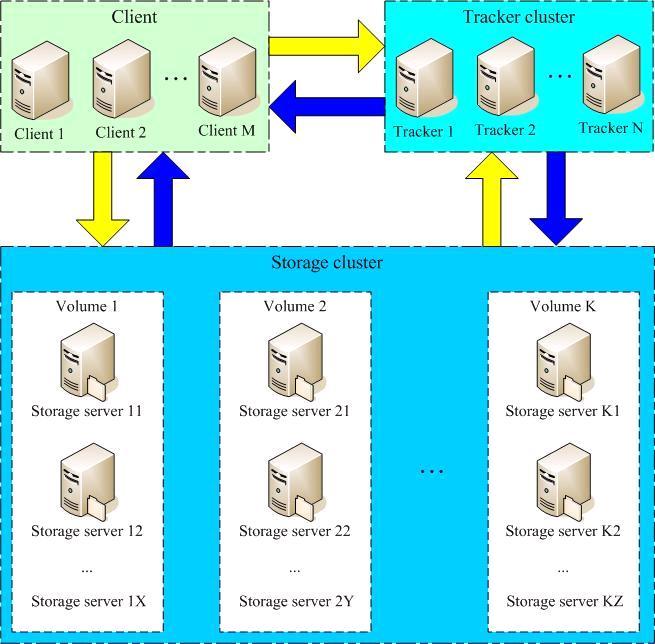
2.1 Tracker server
Tracker server类似于GFS中的Master或TFS中的Name server,但与他们很不同的一点是,Tracker server的主要作用是负载均衡和调度,而不负责文件索引和映射。Tracker server在内存中记录分组和Storage server的状态等信息,不记录文件索引信息,其占用的内存量也很少。Tracker server可以只有一个,也可以有多个组成Tracker cluster,这样的好处是可以提高对用户的响应能力和增加容灾性,此时各Tracker server相互对等,冗余备份,由应用端来轮流选择进行访问。
2.2 Storage server
Storage server完成文件管理的所有功能:存储、同步和提供存取接口,文件和metadata都存储在其上。Storage server类似于GFS中的Chunk server或TFS中的Data server,通常一个Storage server即一台机器,Storage server可以动态新增和删除。FastDFS的存储部分即Storage cluster,分为多个Volume,每个Volume中包括多个Storage server。同一Volume内的各Storage server之间是对等的,存储的内容相同,起冗余容错的作用。文件上传、下载、删除等操作可在Volume内任意一台
Storage server上进行。一个Volume的存储容量取决于该Volume内最小的Storage server的容量,因此Volume内各Storage server的软硬件配置最好是一致的。采用这种分Volume的存储方式的好处是灵活、可控性较强。比如上传文件时,可以由客户端直接指定上传到哪个Volume。当某个Volume的访问压力较大时,可以在该Volume内增加Storage server来扩充服务能力(纵向扩容)。当系统总容量不足时,可以增加Volume来扩充存储容量(横向扩容)。
Storage server直接利用OS的文件系统存储文件。FastDFS不会对文件进行分块存储,客户端上传的文件和Storage server上的文件一一对应。
关于Storage server的同步,不同Volume的Storage server之间不会相互通信,同Volume内的Storage server之间会相互连接进行文件同步。文件同步采用push方式,接受更新操作的文件称为源文件,其所在server称为源服务器,其它文件称为备份文件,其它server称为目标服务器。当文件更新操作发生时,源服务器向目标服务器发起同步,对所有备份文件进行更新。当有新Storage server加入本Volume时,由已有的一台 Storage server将其上的所有文件同步给该新增服务器。具体的同步实现在Storage
server中由专门线程根据binlog进行,binlog记录了文件上传、删除等更新操作。为了最大程度地避免相互影响以及出于系统简洁性考虑,Storage server对同Volume内除自己以外的每台服务器都会启动一个线程来负责文件同步。
这种异步的同步方式带来了一致性问题,当源文件尚未来得及将所有备份文件同步更新时,访问这些备份文件将引发错误。文件的访问主要分为更新和下载两种情况:FastDFS规定更新操作只能对源文件进行,从而避免了同时对不同的备份文件进行更新导致的冲突;文件下载时,Tracker server记录了各Storage server中各文件的同步情况,会向Client提供同步后的文件所在的Storage server。
3.文件上传下载流程
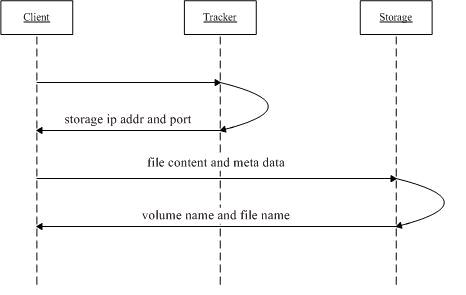
3.1 文件上传流程:
1. Client询问Tracker server应上传到哪个Storage server;
2. Tracker server返回一台可用的Storage server,返回的数据为该Storage server的IP地址和端口;
3. Client直接和该Storage server建立连接,进行文件上传,Storage server返回新生成的文件ID,文件上传结束。
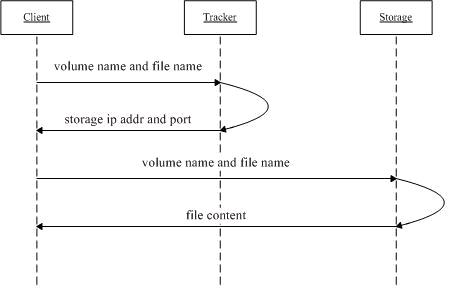
3.2 文件下载流程:
1. Client询问Tracker server可以下载指定文件的Storage server,参数为文件ID(包含Volume号和文件名);
2. Tracker server返回一台可用的Storage server;
3. Client直接和该Storage server建立连接,完成文件下载。
4 总结
FastDFS是基于互联网应用的开源分布式文件系统,主要解决了大容量的小文件存储和高并发访问的问题,具有轻量级、支持高并发访问、高可扩展性等优点。
本文为个人分析观点,有不正确处敬请各路大侠指正。谢谢!(文中参考了happy_fish的文章和插图)
http://blog.csdn.net/ivy_zhang_1101081987/article/details/6196903