操作XML的几种方式
1.DOM生成和解析XML文档
为 XML 文档的已解析版本定义了一组接口。解析器读入整个文档,然后构建一个驻留内存的树结构,然后代码就可以使用 DOM 接口来操作这个树结构。优点:整个文档树在内存中,便于操作;支持删除、修改、重新排列等多种功能;缺点:将整个文档调入内存(包括无用的节点),浪费时间和空间;使用场合:一旦解析了文档还需多次访问这些数据;硬件资源充足(内存、CPU)。
2.SAX生成和解析XML文档
为解决DOM的问题,出现了SAX。SAX ,事件驱动。当解析器发现元素开始、元素结束、文本、文档的开始或结束等时,发送事件,程序员编写响应这些事件的代码,保存数据。优点:不用事先调入整个文档,占用资源少;SAX解析器代码比DOM解析器代码小,适于Applet,下载。缺点:不是持久的;事件过后,若没保存数据,那么数据就丢了;无状态性;从事件中只能得到文本,但不知该文本属于哪个元素;使用场合:Applet;只需XML文档的少量内容,很少回头访问;机器内存少;
3.DOM4J生成和解析XML文档
DOM4J 是一个非常非常优秀的Java XML API,具有性能优异、功能强大和极端易用使用的特点,同时它也是一个开放源代码的软件。如今你可以看到越来越多的 Java 软件都在使用 DOM4J 来读写 XML,特别值得一提的是连 Sun 的 JAXM 也在用 DOM4J。
4.JDOM生成和解析XML
为减少DOM、SAX的编码量,出现了JDOM;优点:20-80原则,极大减少了代码量。使用场合:要实现的功能简单,如解析、创建等,但在底层,JDOM还是使用SAX(最常用)、DOM、Xanan文档。
以上是java解析XML的四种方式.
而我在我看来无论是哪种语言或者方式解析XML(不考虑性能等问题),都能简单的概述为以下几步:
读:
①:通过流的方式获得XML文件
②:创建文档对象
③:获得根节点
④:层层遍历,封装为POJO类,转化为集合
写:
①:创建文档对象
②:创建根节点
③:根节点依次添加子节点,设置节点属性等等
④:通过文件流写XML文件
为什么选择Dom4j?
原因很简单,Hibernate就是使用Dom4j操作Xml来做ORM.
其他的很多Apache项目也是使用Dom4j作为操作XML;
所以选择Dom4j.
使用Dom4j步骤.
导入Jar, 下载地址很多 这里使用dom4j-1.6.1.jar
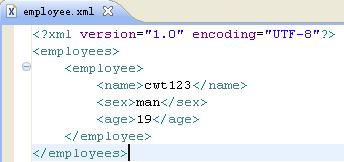
读Demo:
book.xml内容如下
编写测试类: [输出的结果可以用一个POJO来包装 得到对象再进行操作]
result:

写Demo:
result: