返回文档首页
(一)简介
代码下载: git clone git://git.code.sf.net/p/redy/code redy-code
当我们需要识别文本时,通常分析步骤为:
- 根据文本内容的规律推导一个上下文无关文法,但最好是正则文法。
- 根据文法画出状态机。
- 把状态机转化为状态矩阵。
这一章的内容有:
- 变量识别
- 字符串识别
- 注释的识别
(二)变量识别
1)命名规则
Redy中变量的命名规则为:首字符必须为字母,下划线或者字符'@',后面紧接数字,字母,下划线。
2)BNF文法
identifier ::=(letter|'_'|'@')(letter|digit|"_")* digit ::='0'..'9' letter ::=lowercase|uppercase lowercase ::='a'..'z' uppercase ::='A'..'Z'3)状态机
4)状态矩阵

对于变量来说,可以把字符分为这么几类:
- 数字(digit)
- 字母(letter)
- 下划线(underline)
- 符号@(s_at)
- 除上面字符以外其它字符(other)
状态有两个,一个为 identifier_begin,一个为identifier。其中开始状态为identifier_begin,结束状态为identifier
状态矩阵为:
状态\输入
Other
Digit
Letter
Underline
s_at
identifier_begin
identifier
identifier
identifier
identifier
identifier
identifier
identifier
其中空格的地方表示,在当前状态下,并不能识别该输入类型的字符。
5)程序数据
我们用一个一映射每个字符所属的类型:
#define ID_ERR 0 #define ID_DIGIT 1 #define ID_LETTER 2 #define ID_UNDERLINE 3 #define ID_S_AT 4 char identifier_type_map[ASSIC_NUM]= { 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0, 4,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,0,0,0,0,3, 0,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 };状态转换矩阵虽然是一个二维的矩阵,但是我们这里用一个一维组数来表于:
#define ID_STATE_TYPES 2 #define ID_INPUT_TYPES 5 #define ID_STATE_BEGIN 0 #define ID_STATE_IDENTIFIER 1 #define ID_STATE_ERROR -1 /*Other | Digit | Letter | Underline | S_AT */ int identifier_automaton[ID_STATE_TYPES*ID_INPUT_TYPES]= { /*ID_STATE_BEGIN*/ ID_STATE_ERROR,ID_STATE_ERROR,ID_STATE_IDENTIFIER,ID_STATE_IDENTIFIER,ID_STATE_IDENTIFIER, /* ID_STATE_IDENTIFIER*/ ID_STATE_ERROR,ID_STATE_IDENTIFIER,ID_STATE_IDENTIFIER,ID_STATE_IDENTIFIER,ID_STATE_ERROR };然后再用一个一维数组来表示每一个状态是否为终态:
char id_state[ID_STATE_TYPES]={0,1};
现在我们经完成了大部份的数据。
6)驱动程序
要识别变量,还需要一个驱动程序,为了方便管理,使用一个结构体来管理数据
struct automaton { int states_num; /*状态的数量*/ int inputs_num; /*输入类型的数量*/ char* type_map; /*字符映射到输入类型的数组*/ int begin_state; /*开始状态*/ int* states_matrix; /*状态矩阵*/ char* states_info; /*状态信息*/ };
变量状态的结构体信息:
struct automaton am_id= { ID_STATE_TYPES, ID_INPUT_TYPES, identifier_type_map, ID_STATE_BEGIN, identifier_automaton, id_state };
驱动程序为:
/*返回值-1则表示识别错误,其它值表示能识别的最大位置*/ int driver(struct automaton* am,char* str) { int length=strlen(str); /*字符串长度*/ int i; int cur_state=am->begin_state; /*得到开始状态*/ int last_final=-1; for(i=0;i<length;i++) { int input_type=am->type_map[str[i]]; /*根据当前字符得到输入类型*/ /*根据当前状态和输入类型,查状态转换表,得到下一个状态*/ int next_state=am->states_matrix[cur_state*am->inputs_num+input_type]; /*当前状态是否能识别当前输入类型*/ if(next_state==LEX_ERR) { return last_final; } else { cur_state=next_state; /*如果当前状态为终态,则记录下来识别位置*/ if(am->states_info[cur_state]==1) { last_final=i; } } } return last_final; }
7)测试程序
下面写一个测试程序来测试一下我们程序的效果。
int main() { char buf[2048]; char buf_copy[2048]; printf("input:__quit__ exit\n"); printf("input:"); scanf("%s",buf); while(strcmp(buf,"__quit__")!=0) { int ret=driver(&am_id,buf); if(ret==-1) { printf("sorry,Error String\n"); } else { memcpy(buf_copy,buf,ret+1); buf_copy[ret+1]='\0'; printf("Recongise: %s\n",buf_copy); if(ret+1==strlen(buf)) { printf("It's Variable\n"); } else { printf("It's Not Variable\n"); } } printf("\ninput:"); scanf("%s",buf); } return 0; }现在我们来看一下运行结果:
上面的所有代码都位于:tutorial/lexical/identifier文件夹里面

(三)字符串识别
在Redy字符串是以双引号开头,双引号结尾,中间可以是任意字符,但除'\'以外,'\'用于转义特殊的字符。
1)BNF文法:
string ::='"'stringitem*'"' stringitem ::= <any source character except "\ " or newline or the quote> |'\'esc_item esc_item ::=<any source character >
2)状态机:

3)状态矩阵:
对于字符串来说,输入类型这么几种
- 引号 (quote)
- 换行符(newline)
- 反斜杠(backslash)
- 其它字符(other)
其中:
esc_item包括:引号,换行符,反斜杠,其它字符。
stringItem包括:其它字符。
状态矩阵为:
状态\输入
Other
Newline
Backslash
Quote
string_begin
String
String
string
string_esc
string_end
string_esc
String
String
String
String
string_end
其中string_begin为开始状态,string_end为状态。
4)程序数据:
字符所属类型映射:
#define STRING_OTHER 0 #define STRING_NEWLINE 1 #define STRING_BACKSLASH 2 #define STRING_QUITE 3 char string_type_map[ASSIC_NUM]= { 0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,3,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,2,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 };
状态矩阵:
#define STRING_STATE_TYPES 4 #define STRING_INPUT_TYPES 4 #define STRING_STATE_BEGIN 0 #define STRING_STATE_STRING 1 #define STRING_STATE_ESC 2 #define STRING_STATE_END 3 #define STRING_STATE_ERR LEX_ERR /*Other | Newline | BackSlash | Quite */ int string_automaton[STRING_STATE_TYPES*STRING_INPUT_TYPES]= { /*STRING_STATE_BEGIN*/ STRING_STATE_ERR,STRING_STATE_ERR,STRING_STATE_ERR,STRING_STATE_STRING, /*STRING_STATE_STRING*/ STRING_STATE_STRING,STRING_STATE_ERR,STRING_STATE_ESC,STRING_STATE_END, /*STRING_STATE_ESC*/ STRING_STATE_STRING,STRING_STATE_STRING,STRING_STATE_STRING,STRING_STATE_STRING, /*STRING_STATE_END*/ STRING_STATE_ERR,STRING_STATE_ERR,STRING_STATE_ERR,STRING_STATE_ERR };
状态信息:
char string_state[STRING_STATE_TYPES]={0,0,0,1};
然后再把这些信息集合起来,交结我们的驱动程序来处理:
struct automaton am_string= { STRING_STATE_TYPES, STRING_INPUT_TYPES, string_type_map, STRING_STATE_BEGIN, string_automaton, string_state };
由于驱动程序和变量设别的基本一样,所以这里就不贴出,所有的代码都可以在下载下的文件夹的tutorial/lexical/string里面找到
5)运行结果
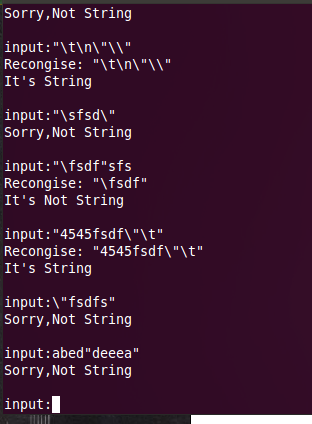
(四)注释的识别
在Redy中,注释是以符号'#'开头,后面可以接任意字符,直到这一行结束。
(1)状态机
(2)状态矩阵
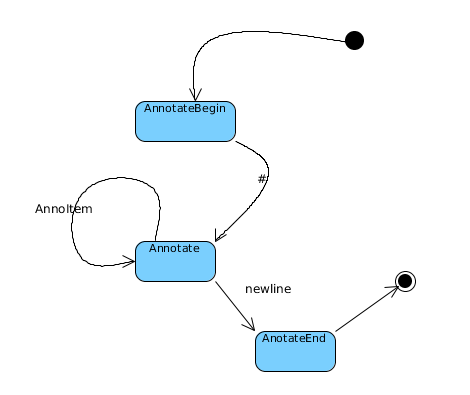
对于注释来说,输入类型可以分为这么几种
- 符号'#' (Pound)
- 换行符 (newline)
- 除以上字符的所有字符 (other)
其中AnnoItem包括 Pound,other状态矩阵为:
状态\输入
Other
Newlin
Pound
AnnotateBegin
Anotate
Anotate
Anotate
AnotateEnd
Anotate
AnotateEnd
其中开始状态为AnnotateBegin,终态为AnotateEnd
(3)程序数据
字符所属类型映射:
enum ANNO_INPUT_TYPTE { ANNO_OTHER=0, ANNO_NEWLINE, ANNO_POUND, ANNO_INPUT_NUM, }; char annotate_type_map[ASSIC_NUM]= { 0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 };
状态矩阵:
#define ANNO_STATE_NUM 3 #define ANNO_BEGIN 0 #define ANNO_ANNOTATE 1 #define ANNO_END 2 /* Other | Newlin | Pound */ int annotate_automaton[ANNO_STATE_NUM*ANNO_INPUT_NUM]= { LEX_ERR,LEX_ERR,ANNO_ANNOTATE, ANNO_ANNOTATE,ANNO_END,ANNO_ANNOTATE, LEX_ERR,LEX_ERR,LEX_ERR, };
状态信息:
char anno_state[ANNO_STATE_NUM]={0,0,1};
然后再把这些信息集合起来,交结我们的驱动程序来处理,驱动程序与前面的介变量识别的一样,但是主函数有一点变化,因为要在输入的字符串包含换行符,所以不能用scanf函数,这里使用的时getline从标准输入中读取一行,主函数为:
int main() { char* buf; int n; char buf_copy[2048]; printf("input:__quit__ exit\n"); printf("input:"); getline(&buf,&n,stdin); while(strcmp(buf,"__quit__")!=0) { int ret=driver(&am_anno,buf); if(ret==-1) { printf("sorry,Not Anno\n"); } else { memcpy(buf_copy,buf,ret+1); buf_copy[ret+1]='\0'; printf("Recongise: %s\n",buf_copy); if(ret+1==strlen(buf)) { printf("It's Anno\n"); } else { printf("It's Not Anno\n"); } } printf("\ninput:"); getline(&buf,&n,stdin); } return 0; }
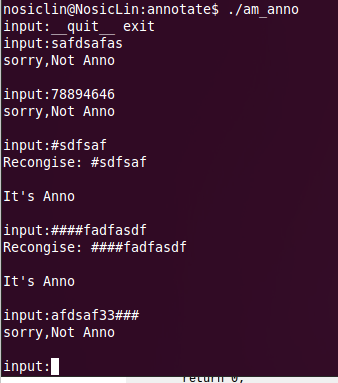
(4)运行结果
关于注释识别的源程序,大家可以在tutorial/lexical/annotate下面找到
返回文档首页