Percolator 中的分布式事务
下一代大规模增量索引平台 – Percolator
简介
继google的3大基石GFS, MapReduce,BigTables之后,Google在10月份osdi会议上公布了论文《Large-scale Incremental Processing Using Distributed Transactions and Notification》,介绍了他们最新的内容索引技术。这项技术是Google下一代内容索引系统Caffeine的核心。该框架在抓取网页的同时进行对文档的处理,将平均延迟降低为原来的百分之一,平均文档寿命(document
age)降低50%。
motivation
传统索引系统通常采用了多级索引的方式,按照网页的重要性将网页进行分级,分别按照小时,天,周对网页库进行更新。其特点是将网页收录到各级网页库时需要对全库进行处理。这种模式最大的缺点是新产生的网页或者信息不能被及时的收录到网页库中,而且定期做全库扫描也会造成计算资源的浪费。根源在于现有MapReduce框架对于网页库的处理粒度过粗,一次全库的更新需要几天的时间才能完成。针对这个问题Percolator细化了更新粒度,提供了对文档的随机访问,实现了对单个文档的处理,避免了MapReduce对全库的遍历。下面我们介绍下Percolator的设计及实现。
设计
在最初的Percolator设计中曾经考虑过直接使用BigTable存储网页库,但是对于构建网页库而言,需要比BigTable行原子性更强的一致性语义。而BigTable的可扩展性,容错以及负载均衡等设计是非常优秀的,为了避免重新发明“轮子”,Percolator在BigTable基础上,通过两阶段提交实现了跨行,跨表事务以及notifiication框架。
Percolator提供了对PB级网页库的随机访问功能。我们可以单独的处理每一个页面,从而避免使用mapreduce框架重建索引库时对全库的scan操作。此外为了实现高吞吐以及高并发下的同步,Percolator支持ACID兼容的事务语义。
对增量索引系统而言除了用户触发的操作外,很多处理流程是数据触发的。 Percolator中数据的变化,并且根据数据的变化进行触发后续的一系列操作(比如:页面解析,内容抽取等)。为了满足此需求,Percolator提供了notification语义。notification语义类似DBMS中的触发器,当Percolator中的某个cell数据发生变化,就触发应用开发者指定的Observer程序。一系列Observer程序通过“责任链”的方式级联,并完成各自逻辑。
作为一个基础架构,Percolator继承了BigTable的一致性和容错模型,并且可以通过增加机器实现集群的线性扩展。此外,它提供了友好的开发接口,使索引系统的开发者专注于页面解析,抽取,分词等算法的开发,而不必被分布式系统中常见的一致性,容错等问题所困扰。
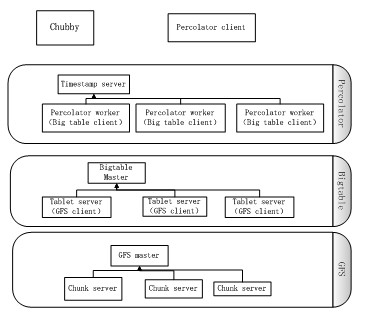
图1 Percolcator主要组件
如图1所示,Percolcator是构建在GFS和BigTable之上,主要包含3个组件。 timestamp server,Percolcator worker,Chubby。
Timestamp server提供了统一时间的服务,它保证每次获取的时间戳单调递增,timestamp server会持久化时间戳,以保证服务重启时时间戳的顺序性。Chubby 服务提供了分布式锁服务,保证Percolcator在处理全局临界资源时,可以互斥访问。Percolcator
worker是Percolator中的主要部分,实现了跨行/跨表事务和notification机制。为获得更好的吞吐量,Percolcator worker启动了多个BigTable client对BigTable进行并发访问。Percolcatorghm,ghdm, worker不持久化任何数据,换言之每个Percolcator worker都是无状态的,如果Percolator
worker节点失效,Percolator client可以通过重试切换到另一个Percolator worker,从而不影响服务。
Percolator的设计主要针对大规模数据存储,以及对网页索引具有实时性更新需求的应用。相对于传统的OLTP,Percolator没有集中的事务管理机制,如果有机器在进行事务的过程中失效,失效事务中的锁释放是一件比较大的挑战。由于Percolator用于网页库建索引这样的线下服务,放松了对实时性的要求,采用一种延迟的方式清理锁。
实现
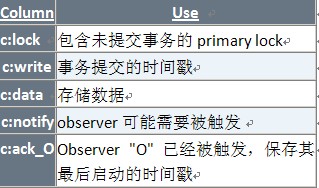
Percolator提供了类似BigTable的用户接口,Percolator中的cell通过BigTable中5列来表示。其中lock, write,data
3列用于实现Percolator事务的功能。Notify和ack_O这2列是为了实现Percolator的notification机制。
下表为Percolator在BigTable中的schema。
下面我们通过Percolator中的两个主要的feature:事务和notification框架来介绍下Percolator的实现机制。
事务
Percolaor在BigTable的基础上,提供了跨行,跨表的ACID语义。Percolator中的事务是通过传统的两阶段提交实现。
在实现分布式事务的时候, Percolator 使用了两个基本的服务, 一个提供精确时间用来产生timestamp, 另外一个提供一种简单的分布式锁, 用来检查一个进程是否还活着. 这两个服务这里不做介绍了. 我们集中精力来看 Percolator 是如何充分利用 bigtable
的单行原子性以及多版本这两个特性来实现自己的分布式事务的. 简单来说, 就是把多列, 多表的事务的提交和回滚变成一个个单行事务.
我们看论文中的具体例子.这个例子是从Bob的账户中转7美金到joe的账户. 这是一个涉及到两个 row 的事务.
下面的表示中, 冒号前面的部分是一个版本号, 可以通过时间服务来解决其取值问题, lock 这个列用来放锁的情况. write 这个列放最终的数据写入情况.
下面的叙述中请大家注意, 单行的操作是有原子性的( bigtable 的保证).
key bal:data bal:lock bal:write
Bob 6: 6: 6: data @ 5
5: $10 5: 5:
Joe 6: 6: 6: data @ 5
5: $2 5: 5:
1 这个是初始状态, bob 账户有10美金, joe 有2个美金. write 列中的 6:data @ 5 表示 当前的数据是 version 为 5 的(感谢 bigtable 的多版本支持)
Bob 7:$3 7: I am primary 7:
6: 6: 6: data @ 5
5: $10 5: 5:
Joe 6: 6: 6: data @ 5
5: $2 5: 5:
2 事务的第一个阶段, bob的账户变成3美金了. 注意 lock 列被加锁, 并且标明自己是 primary. 每个事务中, 只有一个primary, 也正是这个primary的存在, 使得我们能够用行原子性来实现分布式事务.
Bob 7: $3 7: I am primary 7:
6: 6: 6: data @ 5
5: $10 5: 5:
Joe 7: $9 7: primary@Bob.bal 7:
6: 6: 6: data @ 5
5: $2 5: 5:
3 现在给joe加上7美金, 所以joe是9美元了, 注意 joe 这一行的 lock 是指向 primary 的一个指针.
Bob 8: 8: 8: data@7
7: $3 7: 7:
6: 6: 6: data @ 5
5: $10 5: 5:
Joe 7: $9 7: primary @ Bob.bal 7:
6: 6: 6:data @ 5
5: $2 5: 5:
4 事务提交的第一阶段, 提交 primary, 移除lock 列的内容 在 write 列写入最新数据的 version
Bob 8: 8: 8: data @ 7
7: $3 7: 7:
6: 6: 6: data @ 5
5: $10 5: 5:
Joe 8: 8: 8: data@7
7: $9 7: 7:
6: 6: 6: data @ 5
5:$2 5: 5:
5 事务提交的第二阶段, 提交除 primary 之外其它部分. 提交的方式也是移除 lock,
同时在 write 列写入新数据的 version
从这个讲述我们看到是怎么把两行的事务用单行原子性搞定的了. 事务是否提交完全取决于 primary. 如果 primary 提交了, 则lock列被清空, write列标识了正确的版本号. 反之就是未提交. 这种方式可以用来处理多列, 多表, 的事务, 而且可以并发执行的事务数量几乎是无限的.
因为没有任何全局锁.
Percolator是通过快照隔离(Snapshot
isolation)实现事务的,多版本数据是快照隔离的必要条件,幸运的是bigtable可以通过时间戳来支持多版本的数据。。Snapshot
isonation要求存放数据的多个版本,每个版本的数据是一个一致的快照。它可以防止写-写冲突,如果两个事务的更新 基于同一个版本的数据,那么这两个更新只会有一次成功。设计的算法必须保证这一点。
Snapshot isolation并不提供串行化的保证,一般使用这种isolation的事务都对更新顺序不敏感。这种isolation的优点是更新事务不会阻塞读,每次读取都可以读取
一个一致的快照,这样读请求就不用加锁。
下面看下事务处理的算法伪代码:
class Transaction
{
struct Write {Row row; Column col; string value;};
// 所有的写都会cache在这个数组中,直到commit的时候才会进行真正的写入
vector<Write> writes_;
// 事务开始的时间,事务基于该时间之前最后提交的版本为基础进行修改
int start_ts_;
// 事务创建的时候获取基准timestamp
Transaction() : start_ts_(oracle.GetTimeStamp()){}
// 所有更新都被缓存起来
void set(Write w) {writes_.push_back(w);}
// 这里的Get主要是在更新事务中实现read-modify-write,普通读取是不用
// 在事务中进行的,不需要判断当前是否有人加锁,直接获取最新的write中记录的数据版本,
// 然后直接读取相应版本的数据
bool Get(Row row, Column c, string *value)
{
while(true)
{
bigtable::Txn T = bigtable::StartRowTransaction(row);
/// 检查是否有更新事务正在进行
if (T.Read(row, c+"lock", [0,start_ts_]))
{
/// 有未决的事务; 执行clean或者等待
BackoffAndMaybeCleanupLock(row,c);
continue;
}
/// 查找小于start_ts_最后commit的事务,由于每次读取都是通过c.write,因此在一个事务提交之前其他事务是看不到它修改的数据的
last_write = T.Read(row, c+"write", [0,start_ts_]);
if(!last_write.found()) return false; /// no data
/// 获取事务commit的数据的timestamp
int data_ts = last_write.start_timestamp();
*value = T.Read(row, c+"data", [data_ts,data_ts]);
return true;
}
}
/// prewrite, tries to lock cell w, return false in case of conflict
/// 两阶段提交的第一阶段,prewrite,对cell w进行加锁,如果存在冲突,则返回false
/// 冲突有两种情况:
/// -# 事务开始之后别的进程进行了commit操作
/// -# 如果有任何别的线程已经加锁
/// 由于行级事务的存在,保证并发的进程只有一个能够对cell加锁,从而保证
/// snapshot isolation
/// 这里值得关注行级事务如何实现read-modify-write
/// 由于prewrite没有执行取消别人的锁的操作,因此加锁的时候必须保证加锁的顺序,以防止死锁
bool Prewrite(Write w, Write primary)
{
Column c = w.col;
bigtable::Txn T = bigtable::StartRowTransaction(w.row);
/// Abort on writes after our start timestamp ...
if (T.Read(w.row, c+"write", [start_ts,MAX])) return false;
/// ... or locks at any timestamp
if (T.Read(w.row, c+"lock", [0,MAX])) return false;
/// 由于行级事务的存在,保证并发的进程只有一个能够对cell加锁,从而保证
T.write(w.row, c+"data", start_ts_, w.value);
T.write(w.row, c+"lock", start_ts_, {primary.row, primary.col};
return T.Commit();
}
bool Commit()
{
Write primary = write_[0];
vector<Write> secondaries(writes_.begin() + 1, writes_.end());
/// 首先对primary加锁
if (!Prewrite(primary, primary)) return false;
/// 然后对所有需要修改的cell加锁
for(vector<Write>::iterator beg = secondaries.begin();
beg != secondaries.end();
beg ++)
{
if(!Prewrite(w, primary)) return false;
}
/// 这个地方为什么不直接使用start_ts_?这样不能够保证snapshot isolation
/// 设想如下执行场景
/// -# T A start, start_ts_ = 8
/// -# T B start, start_ts_ = 9
/// -# T A commit, if use start_ts_, then write = 8
/// -# T B prewrite, then B will not discover that there is a commit transaction after its start
/// 因此重新获取commit_ts是为了防止并发更新
int commit_ts = oracle_.GetTimestamp();
//首先提交primary
Write p = primary;
bigtable::Txn T = bigtable::StartRowTransaction(p.row);
if(!T.Read(p.row, p.col+"lock", [start_ts_, start_ts_]))
{
/// 由于是乐观锁,因此在加锁(Prewrite)之后执行commit之前,锁可能被其他进程
/// 取消,这种情况下事务应该失败,由于行级事务的存在,锁的取消和提交是串行的
return false;
}
/// start_ts_是cell的结果
T.Write(p.row, p.col+"write", commit_ts_, start_ts_);
/// 解锁
T.Erase(p.row, p.col+"lock", commit_ts);
/// 如果primary更新失败,则事务失败
if(!T.Commit()) return false;
/// Sencond phase: write out write records for secondary cells
/// 下面的更新没有在行事务中,并且更新失败也不会让事务abort,因此primary
/// commit成功,事务一定最终被commit
for(vector<Write>::iterator beg = secondaries.begin();
beg != secondaries.end();
beg ++)
{
/// 在没有行事务的情况下,这里必须保证这种写入顺序,
/// 必须先写write再erase锁,否则异常情况下没有办法恢复
bigtable::Write(w.row, w.col+"write", commit_ts, start_ts_);
bigtable::Erase(w.row, w.col+"lock", commit_ts);
}
return true;
}
};
在事务开始时,取得一个称为start_ts_的时间戳。见line7。
写
在commit之前,通过调用Set()函数,新记录全部在内存中缓存,见line13。commit的代码见line66-78,commit分为两个操作。
第一,给所有要写的记录上锁,见line66-78。在上锁的过程中与其它事务可能产生两种冲突,其一,write-write conflict,即本事务看到了待写记录的时间戳(write列)大于本事务的开始时间(start_ts_),见line55;其二,在待加锁的记录上发现其它的事务加锁,见line57。在发生冲突情况下,Percolator不会对事务进行排队(not
provide serializability),所以在这种情况下本事务会被abort(需要回滚,但是此时不会回滚,需要其它事务的触发)。
分配一个记录上的锁为主锁。在这里我们指定第一个记录上的锁是主锁,其它锁均是对这个锁的引用。
如果没有产生冲突,新记录将被写入表中,见line60。但是没有更新时间戳(write列),所以用户看不到新写入的数据。
第二,首先从timestamp服务取得一个称为commit_ts的时间戳,见line87。从主锁开始,释放各个锁并使得在第一部中的数据更新对其它事务是可见的(把start_ts_写入至记录的write列)。
一旦主锁对应的记录对其它事务是可见(即更新其write列为start_ts_),则此事务在任何情况下都不会失败,即事务一定会commit成功,反之,此事务可能会被abort。这个时间点称为commit point。
读
见line18-38。首先会检测目的记录上是否存在[0,start_ts_]的锁,若有,则等待至解锁,若没有则读取最新版本的数据。
处理client 异常
如何发现事务所属client进程退出(dead)或死锁(stuck)
利用chubby锁服务检测client进程的死活,并在其中写入一个时间戳,client进程会定期的向锁文件写入新的时间戳。若一个client是活的(alive),但是其时间戳太小,client进程被认为是死锁(stuck)。
client发生异常时,如何处理事务?
当其它client上的进程上的事务(事务A)与异常client的事务(事务B)发生冲突时(冲突点可能在line24、line57),事务A会查看事务B是否到达了commit
point(B的主锁是否解锁),若事务B还没有到达commit point,则事务A会roll back(回滚)事务B,删除事务B所有的锁和记录;若事务B已经到达commit point,则事务A会roll
forward(使得B中的更新记录对其它事务可见,并删除B对应的所有锁)事务B。
从伪代码可以看出,算法就是标准的2PC。commit的时候的执行过程如下:
- 对所有participants加锁并执行预处理(预更新)
- 对primary执行commit
- 对所有其他participants执行commit
对primary执行commit成功与否是整个事务成功或者失败的标志。
Percolator就是通过以上5步(从Bob的账户中转7美金到joe的账户例子可以看出)完成事务的两阶段提交。对于分布式事务来讲,由于没有集中事务管理机制,其较大的困难就是在处理事务的过程中,Percolator
client如果出现异常crash,如何清除已有的锁并重新使用被加锁的行。
Percolator采用的是比较消极的锁释放机制。如果事务A在执行的过程中,Percolator client crash掉了,Percolator 并不会主动释放事务A所占有的锁。如果事务B 在进行的过程中,使用到了事务A占有的数据,则由事务B负责锁的释放。
此时,有件比较棘手的事情就是:我们应当如何区分事务A是由于Percolator client crash导致不能完成,还是事务A长时间处于commit 的状态。为了避免此类竞态条件,我们需要一种锁机制来判断这两种情况。由于BigTable能够保证行的原子性,Percolator 很自然的使用BigTable的一个cell作为锁(称为primary
lock),先抢到primary lock的则可以执行,否则退出。
Notification机制
粗略的讲,Notification机制类似于DBMS中的触发器,即用户对cell的修改都会触发观察该cell的程序(我们把这个程序称为”Observer”)。多个Observer组成一个”责任链”,当被观察的cell被修改的时候,Observer链上的全部Observer将被触发。
在实现上,为了能够及时发现被修改的cell,Percolator在其每一行中增加了一个BigTable列notify,用于标识被修改且没有触发执行Observer的cell。为了发现被标识为notify的cell,每个Percolator
worker都会随机选取tablet,并进行scan。对于被标识为notify的dirty cell,则触发observer链。为了避免多个worker同时scan相同的tablet,worker使用分布式锁服务(Chubby)在开始scan一个tablet的时候对tablet进行加锁。对于网页库而言,这种周期性的对全表上P级数据进行scan是一个非常低效的操作,为了对其优化减少每次scan的数据量,Percolator利用了BigTable按列存储的优势,将notify列指定为单独的locality
group,保证worker只对notify列进行scan,避免了全表扫描造成的对多余数据的加载。
此外,为了区分已被触发的Observer,Percolator增加了列ack_O,(表示名字为O的Observer对应的ack),该列的内容为对应Observer的最后启动时间。当被观察的列被修改,Percolator启动一个事务来处理notification。该事务读取被观察的列以及其相关联的ack列,如果该column最后写时间大于ack_O中的时间戳,则认为该column对应的Observer需要被触发。否则,认为Observer已经被触发。
在Notification机制的实现上需要考虑以下几个重要问题:
1. 如何防止多个notification事务的无限循环?
2. 如果多个notification事务触发了对同一个cell的修改,如何避免并发修改造成的正确性问题?
对于问题1当前Percolator实现中并未对notification事务的无限循环进行检测和防止,所以应用开发者必须在Observer开发中警惕此种情况,避免notification循环的出现。
对于问题2,Percolator的解决方法是使每一个被触发的Observer为一个事务,如果启动了多个Observer,同时修改一个cell,则事务锁机制可以避免重复修改引入的正确性问题。
总结
本文简单介绍了下一代大规模增量索引平台-Percolator所要解决的问题,实现的方法。该平台构建在Big Table和GFS上,利用了GFS的数据安全,BigTable的行原子性,负载均衡以及服务容错等优越特性,提供了稳定,可扩展的增量索引构建平台,并且相对于传统索引技术而言,带来了搜索结果的实时性和集群资源利用率的全面提升。在一窥Google基础架构的同时,我们可喜的看到,作为Percolator中最主要的2大功能的身影已经出现在HBase社区的开发计划中(Transaction和Coprocessor),下一代大规模增量索引平台离我们并不遥远。
percolator相关补充:
随着需要收集和处理的数据规模以惊人的速率增长,曾经只有Google级别的系统才会遇到的可伸缩性需求变得更普遍,并常常需要专门的解决方案。Daniel
Peng和Frank Dabek最近发表了一篇论文,介绍Google索引系统Percolator的技术细节。Percolator目前运行在数千台服务器上,存储了数十PB的数据,并且每天要处理数十亿次的更新。
在抓取网页的同时进行索引更新,意味着在新文档不断加入时,需要对已有的总文档库进行持续地更新。这是通过小规模、独立的变换实现海量数据转换任务的一个典型范例。现有的技术基础平台恰恰不能胜任这样的任务:传统DBMS无法满足存储量和吞吐率的需求,而MapReduce和其它批处理系统无法逐个处理小规模更新,因为它们必须依赖于创建大量的批处理任务才能获得高效率。
Daniel和Frank解释说,尽管索引的过程是一项批处理任务,可以通过一系列的MapReduce操作来表现。但每次重新爬完一些页面后要更新索引的时候,由于新增文档和已有文档之间存在链接引用的关系,只对增量部分运行MapReduce操作是远远不够的,实际上必须基于整个文档库进行MacReduce操作。事实上在Percolator出现之前,索引就是以上述的方式更新的。这样带来的主要问题就是由于要对整个文档库重新处理而产生的延迟。
解决此问题的关键是优化增量数据的处理方式。Percolator的一个关键设计理念是:提供对库中文档的随机访问,以实现对单个文档的处理,从而避免了像MapReduce那样对文档全集进行处理。Percolator通过“快照隔离”实现了遵从ACID的跨行及跨表事务,从而满足多线程在多台服务器上对文档库进行转换操作的需求。Percolator还提供了“观察者(observer)”机制,在用户指定的列发生更新之后,这些观察者会被系统触发,以帮助开发者追踪计算过程所处的状态。
论文作者补充到:
Percolator是专门针对处理增量更新而设计,但不是用于取代大多现有的数据处理解决方案。那些不能被拆分为单个微小更新的计算任务(比如对一个文件排序)仍然最好由MapReduce承担。
Percolator更适合于在高一致性及在数据量和CPU等方面有很高需求的计算任务。对于Google来说,它的主要用途是将网页实时地添加到Web索引中。运用Percolator,Google可以在抓取网页文档的同时来对文档进行处理,从而将平均延迟降低为原来的百分之一,平均文档寿命(document
age)降低50%。
Percolator建立于分布式存储系统BigTable之上。集群里的每台服务器上运行着三个可执行文件:worker,BigTable
tablet服务器和Google File System chunkserver服务器
所有观察者都被关联到Percolator worker上,后者会对BigTable进行扫描,一旦发现更新过的列就会在worker进程中以函数调用的方式触发("notification")相应的观察者。观察者通过向BigTable tablet服务器发送读、写RPC请求来运行事务,继而触发后者向GFS chunkserver服务器发送读、写RPC请求。
Percolator没有提供用于事务管理的中心服务器,也没有全局锁侦测器。因为Percolator不需要像运行OLTP任务的传统DBMS一样,对低延迟有很高要求,所以它采取了一种延迟的方式来清理锁,也因此在事务提交时造成了数十秒的延迟。
这种方法增加了事务冲突时的延迟,但保证了系统可以扩展到几千台服务器的规模……尽管增量数据处理在没有强事务的情况下也能进行,但事务使得开发者更容易地去分析系统的状态,并避免将错误引入到长时间运行的文档库中。
Percolator的架构可以在普通廉价服务器集群上线性扩展多个数量级。在性能方面,Percolator处于MapReduce和DBMS之间。和DBMS相比,在处理同样数量的数据情况下,Percolator由于其分布式架构,资源消耗远大于DBMS,同时它还引入了约30倍的额外性能开支。和MapReduce相比,Percolator可以以低很多的延迟来处理数据,同时需要额外的资源来支持随机查找。Percolator自2010年4月开始为Google
web搜索提供索引,它利用合理的额外资源消耗,获得了更低的延迟。
下一代大规模增量索引平台 – Percolator
简介
继google的3大基石GFS, MapReduce,BigTables之后,Google在10月份osdi会议上公布了论文《Large-scale Incremental Processing Using Distributed Transactions and Notification》,介绍了他们最新的内容索引技术。这项技术是Google下一代内容索引系统Caffeine的核心。该框架在抓取网页的同时进行对文档的处理,将平均延迟降低为原来的百分之一,平均文档寿命(document
age)降低50%。
motivation
传统索引系统通常采用了多级索引的方式,按照网页的重要性将网页进行分级,分别按照小时,天,周对网页库进行更新。其特点是将网页收录到各级网页库时需要对全库进行处理。这种模式最大的缺点是新产生的网页或者信息不能被及时的收录到网页库中,而且定期做全库扫描也会造成计算资源的浪费。根源在于现有MapReduce框架对于网页库的处理粒度过粗,一次全库的更新需要几天的时间才能完成。针对这个问题Percolator细化了更新粒度,提供了对文档的随机访问,实现了对单个文档的处理,避免了MapReduce对全库的遍历。下面我们介绍下Percolator的设计及实现。
设计
在最初的Percolator设计中曾经考虑过直接使用BigTable存储网页库,但是对于构建网页库而言,需要比BigTable行原子性更强的一致性语义。而BigTable的可扩展性,容错以及负载均衡等设计是非常优秀的,为了避免重新发明“轮子”,Percolator在BigTable基础上,通过两阶段提交实现了跨行,跨表事务以及notifiication框架。
Percolator提供了对PB级网页库的随机访问功能。我们可以单独的处理每一个页面,从而避免使用mapreduce框架重建索引库时对全库的scan操作。此外为了实现高吞吐以及高并发下的同步,Percolator支持ACID兼容的事务语义。
对增量索引系统而言除了用户触发的操作外,很多处理流程是数据触发的。 Percolator中数据的变化,并且根据数据的变化进行触发后续的一系列操作(比如:页面解析,内容抽取等)。为了满足此需求,Percolator提供了notification语义。notification语义类似DBMS中的触发器,当Percolator中的某个cell数据发生变化,就触发应用开发者指定的Observer程序。一系列Observer程序通过“责任链”的方式级联,并完成各自逻辑。
作为一个基础架构,Percolator继承了BigTable的一致性和容错模型,并且可以通过增加机器实现集群的线性扩展。此外,它提供了友好的开发接口,使索引系统的开发者专注于页面解析,抽取,分词等算法的开发,而不必被分布式系统中常见的一致性,容错等问题所困扰。
图1 Percolcator主要组件
如图1所示,Percolcator是构建在GFS和BigTable之上,主要包含3个组件。 timestamp server,Percolcator worker,Chubby。
Timestamp server提供了统一时间的服务,它保证每次获取的时间戳单调递增,timestamp server会持久化时间戳,以保证服务重启时时间戳的顺序性。Chubby 服务提供了分布式锁服务,保证Percolcator在处理全局临界资源时,可以互斥访问。Percolcator
worker是Percolator中的主要部分,实现了跨行/跨表事务和notification机制。为获得更好的吞吐量,Percolcator worker启动了多个BigTable client对BigTable进行并发访问。Percolcatorghm,ghdm, worker不持久化任何数据,换言之每个Percolcator worker都是无状态的,如果Percolator
worker节点失效,Percolator client可以通过重试切换到另一个Percolator worker,从而不影响服务。
Percolator的设计主要针对大规模数据存储,以及对网页索引具有实时性更新需求的应用。相对于传统的OLTP,Percolator没有集中的事务管理机制,如果有机器在进行事务的过程中失效,失效事务中的锁释放是一件比较大的挑战。由于Percolator用于网页库建索引这样的线下服务,放松了对实时性的要求,采用一种延迟的方式清理锁。
实现
Percolator提供了类似BigTable的用户接口,Percolator中的cell通过BigTable中5列来表示。其中lock, write,data
3列用于实现Percolator事务的功能。Notify和ack_O这2列是为了实现Percolator的notification机制。
下表为Percolator在BigTable中的schema。
下面我们通过Percolator中的两个主要的feature:事务和notification框架来介绍下Percolator的实现机制。
事务
Percolaor在BigTable的基础上,提供了跨行,跨表的ACID语义。Percolator中的事务是通过传统的两阶段提交实现。
在实现分布式事务的时候, Percolator 使用了两个基本的服务, 一个提供精确时间用来产生timestamp, 另外一个提供一种简单的分布式锁, 用来检查一个进程是否还活着. 这两个服务这里不做介绍了. 我们集中精力来看 Percolator 是如何充分利用 bigtable
的单行原子性以及多版本这两个特性来实现自己的分布式事务的. 简单来说, 就是把多列, 多表的事务的提交和回滚变成一个个单行事务.
我们看论文中的具体例子.这个例子是从Bob的账户中转7美金到joe的账户. 这是一个涉及到两个 row 的事务.
下面的表示中, 冒号前面的部分是一个版本号, 可以通过时间服务来解决其取值问题, lock 这个列用来放锁的情况. write 这个列放最终的数据写入情况.
下面的叙述中请大家注意, 单行的操作是有原子性的( bigtable 的保证).
key bal:data bal:lock bal:write
Bob 6: 6: 6: data @ 5
5: $10 5: 5:
Joe 6: 6: 6: data @ 5
5: $2 5: 5:
1 这个是初始状态, bob 账户有10美金, joe 有2个美金. write 列中的 6:data @ 5 表示 当前的数据是 version 为 5 的(感谢 bigtable 的多版本支持)
Bob 7:$3 7: I am primary 7:
6: 6: 6: data @ 5
5: $10 5: 5:
Joe 6: 6: 6: data @ 5
5: $2 5: 5:
2 事务的第一个阶段, bob的账户变成3美金了. 注意 lock 列被加锁, 并且标明自己是 primary. 每个事务中, 只有一个primary, 也正是这个primary的存在, 使得我们能够用行原子性来实现分布式事务.
Bob 7: $3 7: I am primary 7:
6: 6: 6: data @ 5
5: $10 5: 5:
Joe 7: $9 7: primary@Bob.bal 7:
6: 6: 6: data @ 5
5: $2 5: 5:
3 现在给joe加上7美金, 所以joe是9美元了, 注意 joe 这一行的 lock 是指向 primary 的一个指针.
Bob 8: 8: 8: data@7
7: $3 7: 7:
6: 6: 6: data @ 5
5: $10 5: 5:
Joe 7: $9 7: primary @ Bob.bal 7:
6: 6: 6:data @ 5
5: $2 5: 5:
4 事务提交的第一阶段, 提交 primary, 移除lock 列的内容 在 write 列写入最新数据的 version
Bob 8: 8: 8: data @ 7
7: $3 7: 7:
6: 6: 6: data @ 5
5: $10 5: 5:
Joe 8: 8: 8: data@7
7: $9 7: 7:
6: 6: 6: data @ 5
5:$2 5: 5:
5 事务提交的第二阶段, 提交除 primary 之外其它部分. 提交的方式也是移除 lock,
同时在 write 列写入新数据的 version
从这个讲述我们看到是怎么把两行的事务用单行原子性搞定的了. 事务是否提交完全取决于 primary. 如果 primary 提交了, 则lock列被清空, write列标识了正确的版本号. 反之就是未提交. 这种方式可以用来处理多列, 多表, 的事务, 而且可以并发执行的事务数量几乎是无限的.
因为没有任何全局锁.
Percolator是通过快照隔离(Snapshot
isolation)实现事务的,多版本数据是快照隔离的必要条件,幸运的是bigtable可以通过时间戳来支持多版本的数据。。Snapshot
isonation要求存放