解决效率问题:1。为什么会出现这种问题 2。解决的途径是什么3。用例子来说话
如果下面的几个例子,你能正确给出答案:请不必再看!!
#pragma pack(1)//用来定义内存对齐所占字节
struct Test
{
double d;
char e;
int c;
char pp;
};
#pragma pack()//这个取消操作
#pragma pack(2)
struct Test
{
double d;
char e;
int c;
char pp;
};
#pragma pack()
#pragma pack(4)
struct Test
{
double d;
char e;
int c;
char pp;
};
#pragma pack()
答案分别为:14,16,24--------
#pragma pack(4)
struct Test
{
char e;
double d;
};
#pragma pack()
struct Test
{
char e;
double d;
};
这两个所占内存大小分别为:12,16------知道为什么吗?如果没有加上#pragma pack(4),那就按最大类型的倍数来算。但是话又说回来,加不加对于一个32位处理器的CPU来说,不都一样吗???不加也应该按照4个字节来算才对呀!!-----这里我还是有点晕,如果你懂的话,讲评价一下
为什么需要内存对齐??
因为CPU看待数据和我们不一样::

以上是人们的角度:

以上是CPU的角度
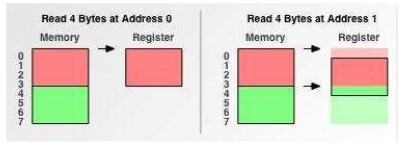
读数据时如果是从0字节开始读取时,直接读取4个字节即可,只读一次
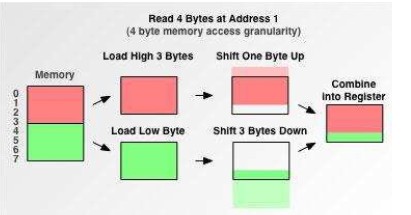
读数据如果是从1开始:所要做的工作是:此时CPU先访问一次内存,读取0-3个字节的数据进寄存器,并再次读取4-5个字节的数据进寄存器,接着把0字节和5,6,7字节的数据删除,最后全并1,2,3,4,字节的数据进寄存器。

cpu是按块读取的,假如我们想读取2-7这些字节,不能人为的想想像我们直接读吧-2,3,4,5,6,7。但是CPU是另一种思维,它只能按块读取时,虽然要读取234,便是真正在读时会扩充,一下读4个字节。