---------------------------------------- 对象的序列化:-------------------------------------------
对象序列化操作需要使用到ObjectOutputStream和ObjectInputStream两个对象
ObjectOutputStream也是字节输出流的子类:
java.lang.Object java.io.OutputStream java.io.ObjectOutputStream
ObjectInputStream是字节输入流的子类:
java.lang.Object java.io.InputStream java.io.ObjectInputStreamObjectOutputStream通过writeObject(Object obj) ObjectInputStream通过readObject() 通过一个简单的程序测试:
publicstaticvoid
objetcSeri()throws Exception {
ObjectOutputStream oos =new ObjectOutputStream(
new FileOutputStream("person.object"));
//写入person对象
oos.writeObject(new Person("johnny",21,"CHINA"));
oos.close();
}
控制台 出现如下错误:
Exception in thread "main" java.io.NotSerializableException: com.huaxia.day21.Personat java.io.ObjectOutputStream.writeObject0(Unknown Source)at java.io.ObjectOutputStream.writeObject(Unknown Source)at com.huaxia.day21.ObjectSerializable.objetcSeri(ObjectSerializable.java:15)at com.huaxia.day21.ObjectSerializable.main(ObjectSerializable.java:9)
说明Person这个类没有实现Serializable接口
更正错误后发现硬盘中多了一个person.obejct文件
其内容为一些我们看不懂的字符:
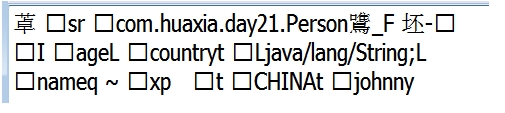
那么我们是否通过ObjectInputStream读取到文件的内容呢?
public static void readObject() throws Exception {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("person.object"));
Person person = (Person)ois.readObject();
System.out.println(person);
}
控制台输出结果:name:johnny age:21 country:CHINA
我们来看一下Serializable接口的API

这意思是说:如果实现了序列化接口的类没有显示声明serialVersionUID变量,序列化运行时将计算一个默认的serialVersionUID的值为这个类基于类的变量方面的值
.我们强烈建议所有实现序列化接口的类都要显示的声明serialVersionUID变量,因为默认的serialVersionUID变量值对于类的修改是非常敏感的,因为他的值就是根据
类成员的签名而生成的而不是系统随机生成的,假设我们对类A进行序列化,在一般情况下我们可以反序列化得到类A的信息,如果我们一旦修改了类A,
那么我们再次反序列化就会出现java.io.InvalidClassException 异常的,因为第一次编译类A的时候他的id是一个值,
你修改类A后在再次编译id的值已经变了.因此为了保证在不同的编译器serialVersionUID变量的值一致性,
所以建议把该变量定义成一个private的常量.
下面来模拟这种情况:现在我修改Person类:如下

重新反序列化一次:
public static void readObject() throws Exception {ObjectInputStream ois = new ObjectInputStream(new FileInputStream("person.object"));Person person = (Person)ois.readObject();System.out.println(person);}
控制台打印店异常:Exception in thread "main" java.io.InvalidClassException: com.huaxia.day21.Person; local class incompatible:
stream classdesc serialVersionUID = -379036032685453711,
local class serialVersionUID = 1208026685571330753
用来将文件或者文件夹封装成对象
---------------------------------------- 管道流:-------------------------------------------
在Java中,可以使用管道流进行线程之间的通信,输入流和输出流必须相连接,这样的通信有别于一般的Shared Data通信,其不需要一个共享的数据空间。
管道流有两个类:
PipedOutputStream管道输出流
java.lang.Object java.io.OutputStream java.io.PipedOutputStream
PipedInputStream管道输入流
java.lang.Objectjava.io.InputStreamjava.io.PipedInputStream
输入输出可以直接连接,通过结合多线程技术 ,如果使用单线程技术,很容易就阻塞了,因为当一个管道读取流去读取数据的时候,如果没有数据那么他就
会一直阻塞在了,我在以前的程序中就已经看到了,那么管道写入流,就没有办法写数据了.所以通过多线程就不会有影响了.
现在我们来实现一个多线程的管道通信流:
package com.huaxia.day21; import java.io.IOException; import java.io.PipedInputStream; import java.io.PipedOutputStream;
class Read implements Runnable {
private PipedInputStream is;
public Read(PipedInputStream is) {
this.is = is;
}
public void run() {
int len=0;
byte[] buffer = new byte[1024];
try {
//如果不使用循环,如果写入的数据超过1024,那么读的就不完整了
while((len=is.read(buffer))!=-1){
System.out.println(new String(buffer,0,len));
}
is.close();
} catch (IOException e) {
throw new RuntimeException("管道流读取失败");
}finally{
if(is!=null)
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
class Write implements Runnable {
private PipedOutputStream os;
public Write(PipedOutputStream os) {
this.os = os;
}
public void run() {
try {
//向管道输出流写入数据
os.write("hello world!".getBytes());
} catch (IOException e) {
e.printStackTrace();
}finally{
if(os!=null)
try {
os.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
public class PipedStreamTest {
public static void main(String[] args) throws IOException {
PipedInputStream pis= new PipedInputStream();
PipedOutputStream pos = new PipedOutputStream();
//连接管道流,使之能够通信
pis.connect(pos);
//启动写入线程
new Thread(new Write(pos)).start();
//启动读取线程
new Thread(new Read(pis)).start();
}
}
---------------------------------------- 随机访问文件:RandomAccessFile-------------------------------------------
首先看一下该类的体系结构:
java.lang.Object java.io.RandomAccessFile
从中可以看出该类不是Io体系中的一员而是直接继承Object类的.
该类的实例同时支持随机的读写文件,随机访问文件的行为就像一个大的字节数组存储在文件系统中,在这个数组中有指针或者下标样的东西,
我们可以通过getFilePointer()方法获取文件当前的指针,并且可以通过seek(long pos) 方法设置指针的位置.
通过构造方法可以看出:该只能操作文件,操作文件的模式mode可以为以下的值:
r rw rws rwd
如果操作文件的模式是只读(r),不会创建文件,回去尝试读取指定的文件,如果文件不存在,则会出现异常
如过操作文件的模式是读写(rw),如果文件不存在,就会创建文件,如果文件存在,则不会覆盖文件.
write(int b) 写一个字节,如果这个字节超过8bit,那么写入最低8bit
writeInt(int v) 把这个整型当作4个字节写入文件,最高8位先写
skipBytes(int n) 跳过n个字节,不能往回跳
seek(long pos) 设置下标的位置,下标是从0开始
getFilePointer() 获取当前的指针位置
对于RandomAccessFile要重点掌握一下几点
2,学会使用seek(long pos) 实现随机读取和随机写入
3,还要注意数据写入要具有规律,以便更好的使用seek方法实现方便的功能.
下面就对于上面的要求来学习一下?
RandomAccessFile raf =new RandomAccessFile("random.txt","rw");
raf.write(97);
raf.close();
发现文件如下所示:

我写入97,那么为什么在txt文件中会显示一个a呢?因为write(int b)把指定的一个字节(4bit)写入到文件中,那么要在文本中显示,显示的肯定是字符而不是
二进制代码,所以它会根据编码表去查发现这个二进制代码所对应的字符是a,所以显示的是a.
我们把上面的 程序中的write方法的参数改为258,如:
RandomAccessFile raf =new RandomAccessFile("random.txt","rw");
raf.write(258);
raf.close();
发现文件如下所示:

因为通过验证我们知道258所对应的二进制是100000010 我们发现这是9位,超过了一个字节8位,而write(int)方法又是写一个字节的,
所以会出现数据丢失的情况.
那我们可以验证一下,第一个程序使用RandomAccessFile读取出来的数据是97,那么说明在文件文件中显示a,是正确的,
第二个程序也使用RandomAccessFile读取文件,如果读取出来的数据是257,那也说明程序是正确的,反之为错误!
验证第一个程序:
public static void readFile() throws IOException{
RandomAccessFile raf = new RandomAccessFile("random.txt","r");
System.out.println(raf.readInt());
}
发现控制台输出的是97,说第一个程序是正确的,
验证第二程序,把参数改成258,重新写一遍,然后在读取 发现控制台输出为2,为什么写入的是257,因为
258所对应的二进制是100000010共9位 而write(int)方法又是写一个字节,最低8位,所以前面的1没有写入,所以最终写入的
是00000010,而00000010对应的十进制又是2,所以输出2了.
那么我们怎么解决呢?我们发现API中是这样表述writeInt(int v)方法的
说明该方法写入的是4个字节,而不是1个字节,所以适合使用这个:
RandomAccessFile raf = new RandomAccessFile("random.txt","rw");
raf.writeInt(258);
raf.close();
raf.writeInt(258);
raf.close();
对应的读取的方法也要改变:
RandomAccessFile raf =new RandomAccessFile("random.txt","r");
System.out.println(raf.readInt());
输出的结果是258,说明是正确的,所以当写入int的时候应该使用writeInt(int),对应的也要使用readInt()读取.
写入数据
public static void writeFile() throws IOException{
RandomAccessFile raf = new RandomAccessFile("random.txt","rw");
//下面写入两个人名和其年龄
raf.write("张三".getBytes());
raf.writeInt(23);
raf.write("李四".getBytes());
raf.writeInt(35);
raf.close();
}
然后读取
public static void readFile() throws IOException{
RandomAccessFile raf = new RandomAccessFile("random.txt","r");
byte[] buffer = new byte[4];
raf.read(buffer);//读取4个字节
int age = raf.readInt();//再读取4个字节
System.out.println("name="+new String(buffer)+"\tage="+age);
}
控制台输出:name=张三 age=23
现在我想读取第二个人,怎么读取呢?
public static void readFile_2() throws IOException{
RandomAccessFile raf = new RandomAccessFile("random.txt","r");
raf.seek(8*1);
byte[] buffer = new byte[4];
raf.read(buffer);//读取4个字节
int age = raf.readInt();//再读取4个字节
System.out.println("name="+new String(buffer)+"\tage="+age);
}
控制台输出:
name=李四 age=35
原理图:
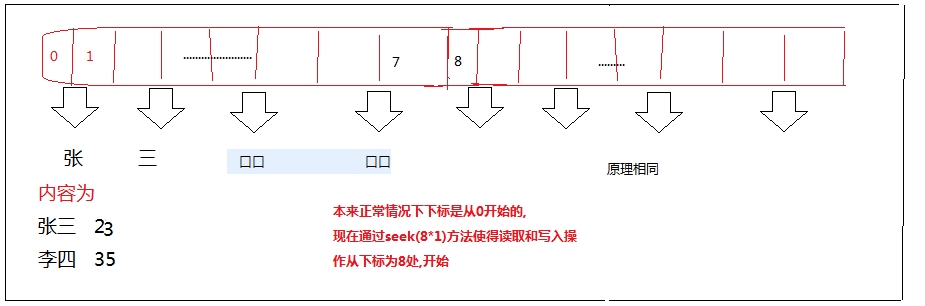
如果现在想在第4个人的位置加一个人?原理也还是一样的设置了下标就可以了
public static void writeFile_2() throws IOException{
RandomAccessFile raf = new RandomAccessFile("random.txt","rw");
raf.seek(8*3);
//下面写入两个人名和其年龄
raf.write("王五".getBytes());
raf.writeInt(99);
raf.close();
}
在读取的时候设置一下下标.控制台输出正常:name=王五 age=99
-------------------------------操作基本数据类型的流对象-----------------------------------
操作基本数据类型的流对象包括:
java.lang.Object java.io.InputStream java.io.FilterInputStream java.io.DataInputStream 和
java.lang.Object java.io.OutputStream java.io.FilterOutputStream java.io.DataOutputStream
一个数据输出流(data out stream)让应用程序把基本的数据类型写入一个输出流当中,可以通过data input stream 读取数据
它操作基本数据类型非常方便,如果使用其他的流对象,来获取基本数据类型,必须要进行类型转换,而在使用data stream则不用如此麻烦,但是要注意
读取的时候要严格按照顺序读取.因为各个基本数据类型的字节数不是相同的,如果不按照顺序怎会出现乱码的情况.
例如:
public static void writeData() throws IOException {
DataOutputStream dos = new DataOutputStream(new FileOutputStream(
"dataType.txt"));
dos.writeInt(109);
dos.writeDouble(123.089);
dos.writeBoolean(true);
dos.close();
}
public static void readData() throws IOException {
DataInputStream dis = new DataInputStream(new FileInputStream(
"dataType.txt"));
int num = dis.readInt();
double d = dis.readDouble();
boolean b = dis.readBoolean();
System.out.println("int:"+num+"\tdouble:"+d+"\tboolean:"+b);
}
输出结果:int:109 double:123.089 boolean:true
我们来看一下UTF-8和UFT修改版的区别:
public static void writeData_2() throws IOException {
DataOutputStream dos = new DataOutputStream(new FileOutputStream(
"utfdata.txt"));
dos.writeUTF("你好中国");
dos.close();
}
发现文件内容如下所示:

文件大小为:
现在我们使用换行流往文件中写入相同的数据:
public static void writeData_3() throws IOException {
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("uft-8data.txt"),"utf-8");
osw.write("你好中国");
osw.close();
}

发现utf-8与utf修改版不管是内容还是大小都是不同的.
现在我们使用转换流,字符集为utf-8可不可以读取用UTF修改版的字符集写入的数据呢?
public static void readData_2() throws IOException {
InputStreamReader isr = new InputStreamReader(new FileInputStream("utfdata.txt"),"utf-8");
BufferedReader bw =new BufferedReader(isr);
//因为是测试,数据只有一行 就不循环
System.out.println(bw.readLine());
}

public static void readData_3() throws IOException {
DataInputStream dis = new DataInputStream(new FileInputStream("utfdata.txt"));
System.out.println(dis.readUTF());
}

-------------------------操作字节数组的流-----------------------------------
java.lang.Object java.io.InputStream java.io.ByteArrayInputStream
ByteArrayInputStream(byte[] buf) ByteArrayInputStream(byte[] buf, int offset, int length)
java.lang.Object java.io.OutputStream java.io.ByteArrayOutputStream ByteArrayOutputStream() ByteArrayOutputStream(int size)
我们知道在字节流中本来就封装了字节数组,那为什么还要出现这操作字节数组的流呢?
ByteArrayInputStream包含一个内部缓冲区,该缓冲区包含从流中读取的字节,内部计数器跟踪read方法
要提供的下一个字节,关闭ByteArrayInputStream无效,此类的方法在关闭流 后任然可以被调用,不会产生IO异常
为什么关闭了流对象还可以使用该类里面的方法呢?
我们查看该类的源代码:
publicvoid close()throws
IOException {
IOException {
}
发现该方法只是一个空实现,为什么?因为该类操作的只是字节数组,没有和底层的资源相关联.所以只是一个空实现.
ByteArrayOutputStream此类实现了一个输出流,数据被写入一个字节数组中,缓冲区会随着数据的不断写入而自动增长,
可以使用toByteArray()和toString()方法获取数据.使用该流的时候不用指定目的地,因为在内部它有一个可变长度的字节数组,
这就是它的目的地.也可把数据写到一个输出流writeTo(OutputStream out)
现在可以总结一下:
源:键盘(System.in) 硬盘(FileStream即能够操作文件的流) 内存(ArrayStream即操作数组的流)
目的:控制台(System.out) 硬盘(FileStream即能够操作文件的流) 内存(ArrayStream即操作数组的流)
这是字节数组流,如果我们操作的是字符呢?使用它的话就不方便了,使用字符数组流就方便了CharArrayReader和CharArrayWriter.还有直接操作字符串的StringReader和StringWriter
它们和字节数组流很相似,这里就不多介绍了.
----------------------------字符编码-----------------------------------------
字符编码牵涉到两个概念:编码和解码;那么什么时候会出现编码什么时候出现解码呢?
当把字符写入文件中,也就是字符向字节数组转换需要编码;
当把文件打开显示给用户看,也就是字节数组向字符转换需要解码;
例如:
public static void main(String[] args) throws UnsupportedEncodingException {
String value = "你好中国";
byte[] b = value.getBytes();// 默认按gbk编码
System.out.println(Arrays.toString(b));
System.out.println(new String(b));
}
输出结果:

因为都是相同的字符编码所以输出正常;
假设我们在解码的时候使用iso8859-1进行解码,情况会怎么样呢?
把上面的
String decode =new String(b);//默认按gbk解码
改为:String decode =new String(b,"iso8859-1");//默认按gbk解码,因为你的字符编码可能写错,所以会抛出UnsupportedEncodingException

发现出现了乱码,因为你使用的是,gbk进行编码的,当使用UTF-8进行解码的时候,在UTF-8编码表里面查找[-60, -29, -70, -61, -42, -48, -71, -6]
所对应的字符,而这些数字对应的字符又是我们看不懂的字符,所以会出现乱码情况!
难道我们使用了错误的字符集进行解码后,就没有办法使数据恢复吗?
当然有!
public static void main(String[] args) throws UnsupportedEncodingException {
String value = "你好中国";
byte[] b = value.getBytes();// 默认按gbk编码
System.out.println(Arrays.toString(b));
String decode = new String(b, "iso8859-1");// 默认按gbk解码
System.out.println(decode);
byte[] b2 = decode.getBytes("iso8859-1");
System.out.println(Arrays.toString(b2));
System.out.println(new String(b,"gbk"));
}
这个程序就可以解决这个问题,输出结果为:

那么它的原理是什么呢?我们画一个图来解释:

以前在学习JSP的时候,发现通过get方法提交的表单,如果在输入框里填写中文,当在服务器端获取该数据的时候就会出现乱码,自己在网上找到了
解决办法,
String name = request.getParameter("username");
name =
new String(name.getBytes("iso8859-1"),"gbk");
可是但是并不知道为什么要这样,现在听了老师的讲解,懂了!
关于"联通"的字符编码:
我们做一个小实验,新建一个记事本,在里面写入两个字"联通",保存,然后关闭.再打开,发现文件里面的数据乱码!这是为什么?

public static void main(String[] args) {
String value = "联通";
byte[] b = value.getBytes();
for(byte by : b){
//打印它的二进制形式
System.out.println(Integer.toBinaryString(by&255));
}
}
输出结果为
11111111111111111111111111000001
11111111111111111111111110101010
11111111111111111111111111001101
11111111111111111111111110101000
获取其最低8bit
System.out.println(Integer.toBinaryString(by&255));
11000001
10101010
11001101
10101000
我们查看UTF的编码描述:
1,所有的字符在'\u0001'到'\u007f'都用一个byte描述,格式如下:

我们知道GBK每两个字节表示一个字符,而UTF-8不是,那么在底层字节流在读取的时候,她怎么知道几个字节表示一个字符呢?
现在通过上面的图发现,它是有自己的规则.
我们发现"联通"的二进制代码和上面的的UTF描述的第2条很像,每个字符的第一个字节都是110开头,每个字符的第二个字节都是10开头,
所以我们在上面的试验中才会出现那样的错误,当我们保存"联通"后,记事本发现它很像UTF的特征,所以它用UTF-8去编码!
解决办法:
在联通前面随便加几个汉字即可,因为记事本一开始发现不像UTF-8的编码特征,所以就使用ANSI去编码 那么什么是ANSI编码呢?
这些使用 2 个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。
---------------------- android培训、java培训、期待与您交流! ----------------------