支持向量机通俗导论(理解SVM的三层境界)
此文章转自 http://blog.csdn.net/v_july_v/article/details/7624837
作者:July、pluskid ;致谢:白石、jerrylead
出处:结构之法算法之道blog。
前言
第一层、了解SVM
1.0、什么是支持向量机SVM
1.1.、线性分类
1.1.1、分类标准
1.1.2、1或-1分类标准的起源:logistic回归
1.1.3、形式化标示类
1.2、线性分类的一个例子
1.3、函数间隔Functional margin与几何间隔Geometrical margin
1.3.1、函数间隔Functional margin
1.3.2、点到超平面的距离定义:几何间隔Geometrical margin
1.4、最大间隔分类器Maximum Margin Classifier的定义
1.5、到底什么是Support Vector
第二层、深入SVM
2.1、从线性可分到线性不可分
2.1.1、从原始问题到对偶问题的求解
2.1.2、线性不可分的情况
2.2、核函数Kernel
2.2.1、如何处理非线性数据
2.2.2、特征空间的隐式映射:核函数
2.2.3、几个核函数
2.2.4、核函数的本质
2.3、使用松弛变量处理 outliers 方法
2.4、小结
第三层、证明SVM
3.1、线性学习器
3.1.1、感知机算法
3.1.2、松弛变量
3.2、最小二乘法
3.3、核函数特征空间
3.4、SMO算法
3.5、SVM的应用
3.5.1、文本分类
参考文献及推荐阅读
前言
动笔写这个支持向量机(support vector machine)是费了不少劲和困难的,从5月22日凌晨两点在微博上说我要写了,到此刻真正动笔要写此文,中间竟然隔了近半个月(而后你会发现,我写完此文得花一个半月,修改完善又得再花一个月,故前后加起来至8月底,写这个SVM便要花足足近3个月)。原因很简单,一者这个东西本身就并不好懂,要深入学习和研究下去需花费不少时间和精力,二者这个东西也不好讲清楚,尽管网上已经有朋友已经写得不错了(见文末参考链接),但在描述数学公式的时候还是显得不够。得益于同学白石的数学证明,我还是想尝试写一下,希望本文在兼顾通俗易懂的基础上,真真正正能足以成为一篇完整概括和介绍支持向量机的导论性的文章。
本文作为Top 10 Algorithms in Data Mining系列第二篇文章,将主要结合支持向量机导论、数据挖掘导论及网友Free
Mind的支持向量机系列而写(于此,还是一篇学习笔记,只是加入了自己的理解,有任何不妥之处,还望海涵),宏观上整体认识支持向量机的概念和用处,微观上深究部分定理的来龙去脉,证明及原理细节,力求深入浅出 & 通俗易懂。
在本文中,你将看到,理解SVM分三层境界,
- 第一层、了解SVM(你只需要对SVM有个大致的了解,知道它是个什么东西便已足够);
- 第二层、深入SVM(你将跟我一起深入SVM的内部原理,通宵其各处脉络,以为将来运用它时游刃有余);
- 第三层、证明SVM(当你了解了所有的原理之后,你会有大笔一挥,尝试证明它的冲动);
以此逐层深入,从而照顾到水平深浅度不同的读者,在保证浅显直白的基础上尽可能深入,还读者一个较为透彻清晰的SVM。
同时,阅读本文之前,请读者注意以下两点:
- 若读者用
IE6浏览器阅读本文,将有大部分公式无法正常显示(显示一半或者完全无法显示),故若想正常的阅读本文请尽量使用chrome等浏览器,谢谢大家。 - 本文中出现了诸多公式,若想真正理解本文之内容,我希望读者,能拿张纸和笔出来,把本文所有定理.公式都亲自推导一遍或者直接打印下来,在文稿上演算(读本blog的最好办法便是直接把某一篇文章打印下来,随时随地思考.演算.讨论)。
Ok,还是那句原话,有任何问题,欢迎任何人随时不吝指正 & 赐教,感谢。
第一层、了解SVM
1.0、什么是支持向量机SVM
要明白什么是SVM,便得从分类说起。
分类作为数据挖掘领域中一项非常重要的任务,目前在商业上应用最多(比如分析型CRM里面的客户分类模型,客户流失模型,客户盈利等等,其本质上都属于分类问题)。而分类的目的则是学会一个分类函数或分类模型(或者叫做分类器),该模型能吧数据库中的数据项映射到给定类别中的某一个,从而可以用于预测未知类别。
其实,若叫分类,可能会有人产生误解,以为凡是分类就是把一些东西或样例按照类别给区分开来,实际上,分类方法是一个机器学习的方法,分类也成为模式识别,或者在概率统计中称为判别分析问题。
你甚至可以想当然的认为,分类就是恰如一个商场进了一批新的货物,你现在要根据这些货物的特征分门别类的摆放在相关的架子上,这一过程便可以理解为分类,只是它由训练有素的计算机程序来完成。
来举个例子,比如心脏病的确诊中,如果我要完全确诊某人得了心脏病,那么我必须要进行一些高级的手段,或者借助一些昂贵的机器,那么若我们没有那些高科技医疗机器,怎么判断某人是否得了心脏病呢?
当然了,古代中医是通过望、闻、问、切“四诊”,但除了这些,我们在现代医学里还是可以利用一些比较容易获得的临床指标进行推断某人是否得了心脏病。如作为一个医生,他可以根据他以往诊断的病例对很多个病人(假设是500个)进行彻底的临床检测之后,已经能够完全确定了哪些病人具有心脏病,哪些没有。因为,在这个诊断的过程中,医生理所当然的记录了他们的年龄,胆固醇等10多项病人的相关指标。那么,以后,医生可以根据这些临床资料,对后来新来的病人通过检测那10多项年龄、胆固醇等指标,以此就能推断或者判定病人是否有心脏病(虽说这个做法不能达到100%的标准,但也能达到80、90%的正确率),而这一根据以往临场病例指标分析来推断新来的病例的技术,即成为分类classification技术。
假定是否患有心脏病与病人的年龄和胆固醇水平密切相关,下表对应10个病人的临床数据(年龄用[x1]表示,胆固醇水平用[x2]表示):
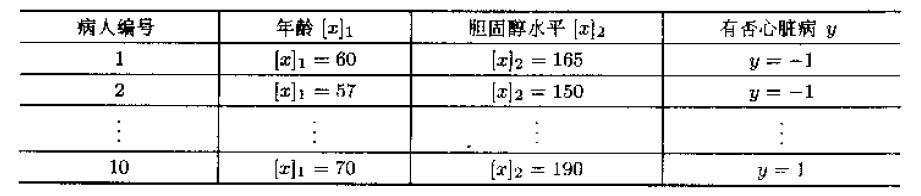
这样,问题就变成了一个在二维空间上的分类问题,可以在平面直角坐标系中描述如下:根据病人的两项指标和有无心脏病,把每个病人用一个样本点来表示,有心脏病者用“+”形点表示,无心脏病者用圆形点,如下图所示:

如此我们很明显的看到,是可以在平面上用一条直线把圆点和“+”分开来的。当然,事实上,还有很多线性不可分的情况,下文将会具体描述。
So,本文将要介绍的支持向量机SVM算法便是一种分类方法。
- 所谓支持向量机,顾名思义,分为两个部分了解,一什么是支持向量(简单来说,就是支持 or 支撑平面上把两类类别划分开来的超平面的向量点,下文将具体解释),二这里的“机”是什么意思。我先来回答第二点:这里的“机(machine,机器)”便是一个算法。在机器学习领域,常把一些算法看做是一个机器,如分类机(当然,也叫做分类器),而支持向量机本身便是一种监督式学习的方法(至于具体什么是监督学习与非监督学习,请参见此系列Machine
L&Data Mining第一篇),它广泛的应用于统计分类以及回归分析中。
支持向量机(SVM)是90年代中期发展起来的基于统计学习理论的一种机器学习方法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。
对于不想深究SVM原理的同学(比如就只想看看SVM是干嘛的),那么,了解到这里便足够了,不需上层。而对于那些喜欢深入研究一个东西的同学,甚至究其本质的,咱们则还有很长的一段路要走,万里长征,咱们开始迈第一步吧(相信你能走完)。
1.1、线性分类
OK,在讲SVM之前,咱们必须先弄清楚一个概念:线性分类器(也可以叫做感知机,这里的机表示的还是一种算法,本文第三部分、证明SVM中会详细阐述)。
1.1.1、分类标准
这里我们考虑的是一个两类的分类问题,数据点用
1 或者 -1 ,分别代表两个不同的类。一个线性分类器就是要在
上面给出了线性分类的定义描述,但或许读者没有想过:为何用y取1 或者 -1来表示两个不同的类别呢?其实,这个1或-1的分类标准起源于logistic回归,为了完整和过渡的自然性,咱们就再来看看这个logistic回归。
1.1.2、1或-1分类标准的起源:logistic回归

 的图像是
的图像是

 ,发现
,发现 只和
只和 有关,
有关, >0,那么
>0,那么 ,g(z)只不过是用来映射,真实的类别决定权还在
,g(z)只不过是用来映射,真实的类别决定权还在 。还有当
。还有当 ,
, =1,反之
=1,反之


 。Logistic回归就是要学习得到
。Logistic回归就是要学习得到 ,使得正例的特征远大于0,负例的特征远小于0,强调在全部训练实例上达到这个目标。
,使得正例的特征远大于0,负例的特征远小于0,强调在全部训练实例上达到这个目标。1.1.3、形式化标示
 替换成w和b。以前的
替换成w和b。以前的 ,其中认为
,其中认为 。现在我们替换
。现在我们替换 为
为
 )。这样,我们让
)。这样,我们让 ,进一步
,进一步

 的正负问题,而不用关心g(z),因此我们这里将g(z)做一个简化,将其简单映射到y=-1和y=1上。映射关系如下:
的正负问题,而不用关心g(z),因此我们这里将g(z)做一个简化,将其简单映射到y=-1和y=1上。映射关系如下:
1.2、线性分类的一个例子
下面举个简单的例子,一个二维平面(一个超平面,在二维空间中的例子就是一条直线),如下图所示,平面上有两种不同的点,分别用两种不同的颜色表示,一种为红颜色的点,另一种则为蓝颜色的点,红颜色的线表示一个可行的超平面。
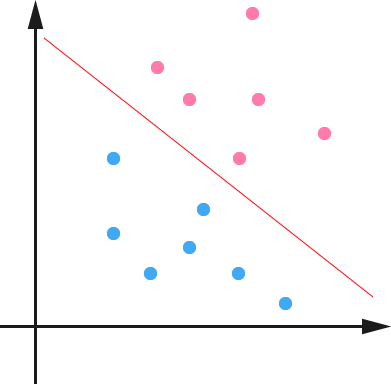
从上图中我们可以看出,这条红颜色的线把红颜色的点和蓝颜色的点分开来了。而这条红颜色的线就是我们上面所说的超平面,也就是说,这个所谓的超平面的的确确便把这两种不同颜色的数据点分隔开来,在超平面一边的数据点所对应的
-1 ,而在另一边全是 1 。
接着,我们可以令分类函数(提醒:下文很大篇幅都在讨论着这个分类函数):
f(x)=
显然,如果
-1 ,而
(有一朋友飞狗来自Mare_Desiderii,看了上面的定义之后,问道:请教一下SVM functional margin 为 γˆ=y(wTx+b)=yf(x)中的Y是只取1和-1 吗?y的唯一作用就是确保functional margin的非负性?真是这样的么?当然不是,详情请见本文评论下第43楼)
当然,有些时候(或者说大部分时候)数据并不是线性可分的,这个时候满足这样条件的超平面就根本不存在(不过关于如何处理这样的问题我们后面会讲),这里先从最简单的情形开始推导,就假设数据都是线性可分的,亦即这样的超平面是存在的。
更进一步,我们在进行分类的时候,将数据点
0 ,则赋予其类别 -1 ,如果大于 0 则赋予类别 1 。如果
请读者注意,下面的篇幅将按下述3点走:
- 咱们就要确定上述分类函数f(x) = w.x + b(w.x表示w与x的内积)中的两个参数w和b,通俗理解的话w是法向量,b是截距;
- 那如何确定w和b呢?答案是寻找两条边界端或极端划分直线中间的最大间隔(之所以要寻最大间隔是为了能更好的划分不同类的点,下文你将看到:为寻最大间隔,导出1/2||w||^2,继而引入拉格朗日函数和对偶变量a,化为对单一因数对偶变量a的求解,当然,这是后话);
- 进而把寻求分类函数f(x) = w.x + b的问题转化为对w,b的最优化问题。
总结成一句话即是:从最大间隔出发(目的本就是为了确定法向量w),转化为求对变量w和b的凸二次规划问题。亦或如下图所示(有点需要注意,如读者@酱爆小八爪所说:从最大分类间隔开始,就一直是凸优化问题):

1.3、函数间隔Functional
margin与几何间隔Geometrical margin
一般而言,一个点距离超平面的远近可以表示为分类预测的确信或准确程度。在超平面w*x+b=0确定的情况下,|w*x+b|能够相对的表示点x到距离超平面的远近,而w*x+b的符号与类标记y的符号是否一致表示分类是否正确,所以,可以用量y*(w*x+b)的正负性来判定或表示分类的正确性和确信度,于此,我们便引出了函数间隔functional
margin的概念。
1.3.1、函数间隔Functional
margin
我们定义函数间隔functional margin 为: