
ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: java.io.IOException: Incompatible namespaceIDs
in /var/lib/hadoop-0.20/cache/hdfs/dfs/data: namenode namespaceID = 240012870; datanode namespaceID = 1462711424 .
问题:Namenode上namespaceID与datanode上namespaceID不一致。
问题产生原因:每次namenode
format会重新创建一个namenodeId,而tmp/dfs/data下包含了上次format下的id,namenode ...
阅读全文

常常被一些用户问到,说“为什么我的mapreduce作业总是运行到某个阶段就报出如下错误,然后失败呢?以前同一个作业没出现过的呀?”
10/01/10 12:48:01 INFO mapred.JobClient: Task Id : attempt_201001061331_0002_m_000027_0, Status : FAILED
java.lang.OutOfMemoryError: Java heap space
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.<init>(MapTask.java:498)
at org.apache.hadoop....
阅读全文
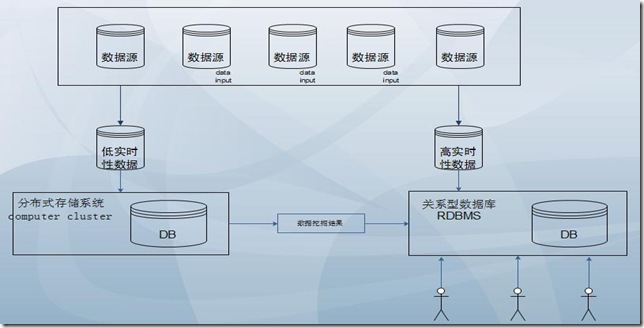
最近一段时间一直在从事和hadoop相关的工作,主要是技术内容学习、安装配置优化以及一些框架结构的设计。在此期间,我对于RDBMS和Hadoop的结合应用有了一些自己的看法,写出来大家共同探讨一下。
1、为什么要用Hadoop
这个在网上已近有很多的人说过这个问题,我在这里就不多述了。但是我想说下,对于一个工具而言,只有最合适的应用场景没有最牛的工具。hadoop对我而言也只是一个工具,所以,更多的时候我是从业务角度...
阅读全文

1. 机器配置
(1) 机器规划
master(NameNode, JobTracker) 192.168.100.123 node14
slave1(DataNode, TaskTracker)192.168.100.124 node15
slave2(DataNode, TaskTracker)192.168.100.125 node16
(2) 添加hadoop用户
在三台机器上分别 groupadd hadoop 并 useradd -g hadoop hadoop添加hadoop用户
(3) NFS设置
通过root用户在master上配置NFS server,并共享/home目录;
在slaves上挂在master上的/home到本...
阅读全文

import java.io.IOException;
import java.util.StringTokenizer;
import java.util.Collections;
import java.util.Iterator;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.li...
阅读全文

废话不讲,直切正题。
搭建环境:Centos x 6.4 64bit
1、安装JDK
我这里用的是64位机,要下载对应的64位的JDK,下载地址:http://www.oracle.com/technetwork/cn/java/javase/downloads/jdk7-downloads-1880260-zhs.html,选择对应的JDK版本,解压JDK,然后配置环境变量,
vi /etc/profile
注:这里有的人喜欢配置在当前用户里,我这里是配置的全局。
export PATH
export JAVA_HOME=/opt/jdk1.7
export PATH=$PATH:$JAVA_HOME/...
阅读全文

Cloudera公司作为Hadoop商业领域的翘首人物,此前就对将Mahout包装为商业应用的一个商业公司进行收购;开启大数据学习领域的云计算领域,而跟Spark商业公司Databricks的进一步合作;进一步完善HDFS数据存储模型下的另外一种流式计算模型的整合。加上Cloudera自身的Impala产品。
在Hadoop领域下,或者大数据模型下的,三种计算和分析技术都集中于Cloudera公司的旗下。
在阿里巴巴内部的诸多云梯、流式计算、海量数据的实时处理...
阅读全文
原文地址:http://www.cnblogs.com/sharpxiajun/p/3151395.html
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密。这个可能是我做技术研究的思路有关,我开始学习某一套技术总是想着这套技术到底能干什么,只有当我真正理解了这套技术解决了什么问题时候,我后续的学习就能逐步的加快,而学习hdfs时候我就发现,要理解hadoop...
阅读全文

1. 配置NameNode和DataNode的目录 ()
说明:配置dfs.name.dir 和 dfs.data.dir
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
<description>Determines where on the local filesystem the DFS name node
should store the name table(fsimage). If this is a comma-delimited list
of directories then the name table...
阅读全文
0) 要是下面的错误你都碰到了。。说明你开发环境没搞好,用下面这个命令吧。
yum groupinstall "Development Libraries"
1) 报错: "[ERROR] Failed to execute goal org.codehaus.mojo:make-maven-plugin:1.0-beta-1:autoreconf (autoreconf) on project hadoop-yarn-server-nodemanager:
autoreconf command returned an exit value != 0. Aborting build; see debug output for more information. -> [Help 1]"
...
阅读全文