机器学习是人工只能领域中与算法相关的一个分支,它允许机器不断地进行学习。很多情况下,这相当于将一组数据传递给算法,并由某个算法推断出这些数据的属性相关的信息。然后借助这些信息,算法就能预测出未来有可能会出现的其他数据。
举个例子,假定我们收到了包含’porn’单词的垃圾邮件,对于人而言,我们可以很轻松地识别出这些垃圾邮件。这就意味着我们实际上已经建立起了一个关于垃圾邮件的智力模型。那如果我们把这样的信息输入给专门用来过滤垃圾邮件的机器学习算法,算法应该有能力做出同人类类似的归纳。
现在已经存在各种机器学习算法。这些算法从广义上来说可以分为监督学习,无监督学习,半监督学习和增强学习。监督学习从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求是包括输入和输出,也可以说是特征和目标,并且训练集中的目标是由人标注的。无监督学习与监督学习相比,训练集没有人为标注的结果。从具体的算法层面来说,常见的算法大致可以分为分类算法和聚类算法。分类算法属于监督学习,常见的算法包括,决策树分类,朴素贝叶斯分类,SVM,神经网络等等。K-means则是典型的聚类算法。这一篇主要介绍的是朴素贝叶斯算法。
在看具体的朴素贝叶斯算法之前我们先来讨论下它的基石—贝叶斯法则。贝叶斯是一种利用概率的推断手段。对已观察到的数据和概率分布来进行推理来进行最优的决策。
我们用P(x) 来表示在没有训练数据前假设x拥有的初始概率。P(x) 被称为x的先验概率(prior probability), 它反映了关于x是一个正确假设的机会的背景知识。
类似,P(c)表示将要观察的训练数据c的先验概率。用P(c|x)表示假设x成立下观察到数据c概率。我们感兴趣的是给定训练数据c时h成立的概率P(x|c),这被叫做h的后验概率(posterior probability), 因为它反映了在看到训练数据c后x成立的概率。
贝叶斯法则提供了从先验概率P(x) 以及P(c)和P(c|x)计算后验概率P(x|c)的方法。
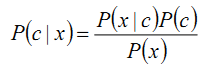
为了更好地说明,我们举个例子。因为贝叶斯分类器在文本文档分类方面是最有效的算法之一。我们来一步一步看贝叶斯是如何判断一个文档属于某个分类的。
P(c|x) = P(x|c)P(c)/p(x)
P(c) – 类别c的先验概率
P(x) – 文档x的先验概率
P(x|c) – 已知文档c属于类别x的概率
P(c|x) – 文档x属于类别c的概率,也就是我们所要求出的值。
这里x表示某一文档,实际上x是一个向量,由文档x的多个特征<a1,a2,...an>来表示。
那么,根据贝叶斯法则,我们可以得到计算最大P(c|x)的公式:

这个式子常常被成为贝叶斯最优分类器。
朴素贝叶斯是贝叶斯学习中比较实用的一个,它假设每个训练实例的属性是相互独立的,所以我们可以得到
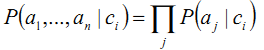
这样一来,我们所要计算的c(x) 就简化成了计算
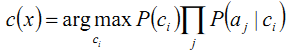
现在我们要做的就是估算上面的式子中出现的两个数据项的值。
这里出现了一个问题:如果没有分类ci有特征量aj, 那么

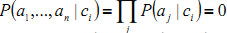
这就是说不管其他的特征值的概率怎样,ci(x)都等于0
当出现这种情况的时候,我们可以在分子分母上都加上1来避免概率为0.这种变换通常被称为Laplace Smoothing. 那么P(aj|ci)就可以变换为
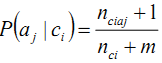
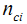 : 所有目标值为Ci的训练样本的个数
: 所有目标值为Ci的训练样本的个数
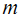 : 不同特征量的个数
: 不同特征量的个数
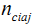 :所有目标值为Ci 并且出现特征值aj的训练样本的个数
:所有目标值为Ci 并且出现特征值aj的训练样本的个数
对于具体的文档分类问题,具体的算法如下:

在实际情况中,p(wj|ci)是个非常小的数值,我们可以用log来放大数值,那么
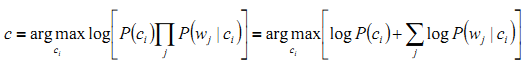
至此,我们就可以得出c了。
总结:
朴素贝叶斯可以用伪代码形式表示如下:
1. 收集训练集中所有的特征量
2. 计算所需要的概率项P(ci)和p(wj|ci)
a) 对于C中每一个目标值ci
i. 计算P(ci)和p(wj|ci)
朴素贝叶斯在文本分类方面在2006年的时候已经被证明甚至比一些更现代的方法比如boosted trees和random forests表现都要出色,而且它只需要较小的训练集。因为它假设属性间都是相互独立的,所以计算量也变小了很多,因为只需要计算每个类别的特征值而不是整个矩阵。
朴素贝叶斯方法的条件独立假设看上去很傻很天真,为什么结果却很好很强大呢?就拿一个句子来说,我们怎么能鲁莽地声称其中任意一个单词出现的概率只受到它前面的 3 个或 4 个单词的影响呢?别说 3个,有时候一个单词的概率受到上一句话的影响都是绝对可能的。那么为什么这个假设在实际中的表现却不比其它算法差呢?有人对此提出了一个理论解释,并且建立了什么时候朴素贝叶斯的效果能够等价于非朴素贝叶斯的充要条件,这个解释的核心就是:有些独立假设在各个分类之间的分布都是均匀的所以对于likelihood的相对大小不产生影响;即便不是如此,也有很大的可能性各个独立假设所产生的消极影响或积极影响互相抵消,最终导致结果受到的影响不大。