Checksums是很便宜计算的(在Java里面,他们执行用本机代码),仅仅需要花费一小部分时间来读和写一个文件。对于大多数应用来说,这是一个可以接受的花费来为数据完整性。但是,也有可能不能checksum了:用例是当底层的文件系统支持本地的checksum。它是用在LocalFileSystem的RawLocalFileSystem来完成的。做这个应用,需要为文件URI满足重新划分操作通过设定fs.file.impl到org.apache.hadoop.fs.RawLocalFileSystem。可选择行的,你可以直接创建个RawLocalFileSystem实例,这个也许有效的如果你想为一些读使checksum检验无效。例如:
configuration conf=...
FileSystem fs=new RawLocalFileSystem();
fs.initialize(null,conf);
ChecksumFileSystem
LocalFileSystem用CheckFileSystem去工作,这个类使添加checksumming到其他的文件系统很容易,当ChecksumFileSystem仅仅是个FileSystem的包装。大体的代码是:
FileSystem rawFs=...
FileSystem checksummedFs=new ChecksumSystem(rawFs);
底层文件系统被称为raw文件系统,并且用在ChecksumFileSystem的getRawFileSystem。ChecksumFileSystem有一些很有用的方法为checksum工作,例如getChecksumFile()得到checksum文件的路径或者其他别的文件。为其他别的文件检查文档。
如果在读文件时候通过ChecksumFileSystem检查出错误的话,它会调用reportChecksumFileSystem()方法。默认的操作方法不做任何事情,但是LocalFileSystem移动那个抵御文件和checksum到另外的路径在相同的设备中,这个文件称为bad_file。管理者应该定期检查这些损坏的文件并对它们采取行动。
Compression
文件压缩会带来两个大的好处:减少文件存储空间,加快数据在网络上的传输,或者从硬盘上传输。当处理大数据时,这些重要好处都是必须的,因此必须仔细考虑怎样在Hadoop中用压缩。
这里有很多不同的压缩格式,工具和算法,各个都有不同特性。Table4-1显示了一些常用的:
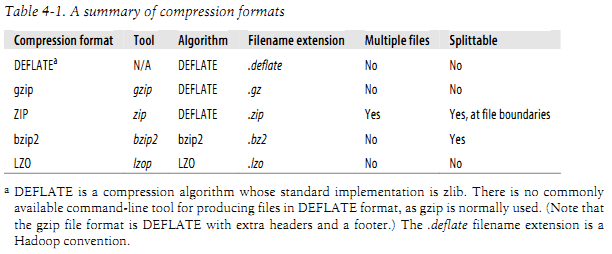
所有的压缩算法显现了一个时间和空间的交易:更快的压缩或者解压就以得到很少的空间节约为代价。所有的在上图中的压缩给了一些控制对于在压缩的时候时空的交易,这里提供了九个可选的方法:1方法是速度快的,9方法是空间节约的。例如,下面的命令用最快的压缩方法产生压缩文件file.gz。gzip -1 file
不同的压缩工具有不同的压缩特征。gzip和Zip都是最常见的压缩,出于中间的时间和空间交易比。Bizp2压缩比gzip和ZIP更加有效的,但是更慢。Bzip2的压缩速度比解压速度快,但是它还是比其他别的压缩方法慢。另一方面LZO速度比较快:它比gzip和ZIP快(或者其他别的压缩和解压方法),但是压缩效果不高效。
在上图的Splittable表示是否支持分割:就是说,是否能在数据流中选择一个点然后开始从其他点读取数据。分割压缩格式尤其对MapReduce适合。在83页“Compression and Input Splits”有更详细的讨论。
Codecs
一个编解码器是用来实行压缩和解压的算法。在Hadoop中,一个编解码器是由CompressionCodec接口代表的。因此,例如,GzipCodec为gzip封装解压和压缩方法。下图显示了Hadoop终端 编解码方法。
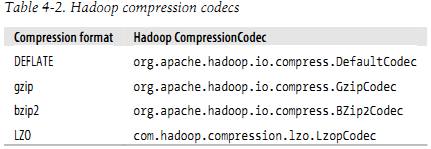
LZO是GPL认证的,也许不包含在Apache分布式中,由于这个原因Hadoop编解码器必须从http://code.google.com/p/hadoop-gpl-compression/。LZopCodec和lzop工具是兼容的,它是一个有额外头的LZO格式,这是通常需要的格式。
Compressiing and decompressing streams with compressionCodec
编解码器有两个方法来使你简单的来压缩和解压。对写入一个输入流的写入压缩,用createOutpurStream方法产生一个CompressionOutputStream到那个写入解压数据,那个解压数据是通过压缩格式写入到数据流上。相对的是,对于那些从输入流中读取的解压数据,调用creatInputStream来获得CompressionInputStream,它会允许读取解压数据从底层流上。
CompressionOutputStream、CompressionInputStream和java.util.zip.DeflaterOutputStream、java.util.zip.DeflecterInputStream是相似的,除此之外,这两种方式提供重设底层的压缩和解压,这是对压缩分离数据块流是很用的,例如SequenceFile,这个详细介绍在SequenceFile章103页。


这个应用得到CompressionCodec的全面作为第一个命令参数。我们用ReflectionUtil来构建第一个codec的实例,然后获得一个封装在System.out。然后我们调用在IOUtiles的copyBytes()方法来复制输入到输出中,这些被CompressionOutputStream压缩。最后,我们在CompressionOutputStream中调用finish(),用它来判断一个压缩器是否完成想输入流写入,但是不会关掉这个数据流。我们能试试这个方法用下面的命令,压缩字符串“Text”用StreamCompressor,然后解压用标准的输入gunzip:
%echo “Text”| hadoop StreamCompressor org.apache.hadoop.io.compress.GzipCodec \ |gunzip -Text