SVD实际上是数学专业内容,但它现在已经渗入到不同的领域中。SVD的过程不是很好理解,因为它不够直观,但它对矩阵分解的效果却非常好。比如,Netflix(一个提供在线电影租赁的公司)曾经就悬赏100万美金,如果谁能提高它的电影推荐系统评分预测准确率提高10%的话。令人惊讶的是,这个目标充满了挑战,来自世界各地的团队运用了各种不同的技术。最终的获胜队伍"BellKor's Pragmatic Chaos"采用的核心算法就是基于SVD。
SVD提供了一种非常便捷的矩阵分解方式,能够发现数据中十分有意思的潜在模式。在这篇文章中,我们将会提供对SVD几何上的理解和一些简单的应用实例。
线性变换的几何意义(The geometry of linear transformations)
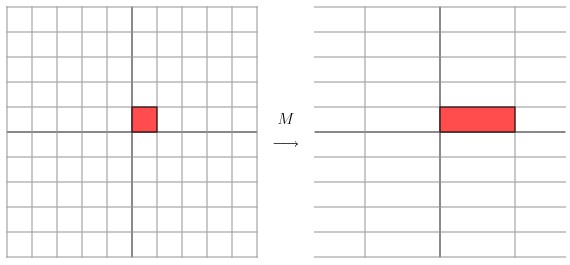
让我们来看一些简单的线性变换例子,以 2 X 2 的线性变换矩阵为例,首先来看一个较为特殊的,对角矩阵:
![]()
从几何上讲,M 是将二维平面上的点(x,y)经过线性变换到另外一个点的变换矩阵,如下图所示
![]()
变换的效果如下图所示,变换后的平面仅仅是沿 X 水平方面进行了拉伸3倍,垂直方向是并没有发生变化。
现在看下矩阵
![]()
这个矩阵产生的变换效果如下图所示
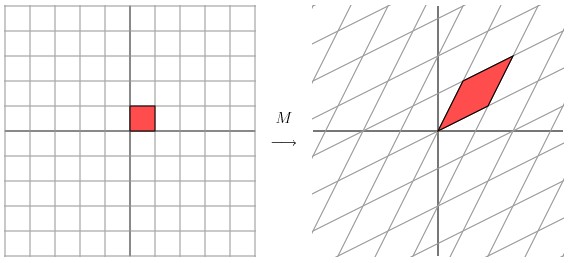
这种变换效果看起来非常的奇怪,在实际环境下很难描述出来变换的规律 ( 这里应该是指无法清晰辨识出旋转的角度,拉伸的倍数之类的信息)。还是基于上面的对称矩阵,假设我们把左边的平面旋转45度角,然后再进行矩阵M 的线性变换,效果如下图所示:
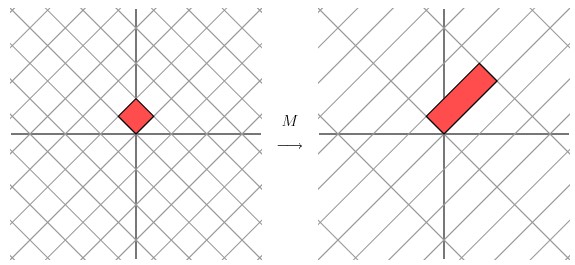
看起来是不是有点熟悉? 对的,经过 M 线性变换后,跟前面的对角矩阵的功能是相同的,都是将网格沿着一个方向拉伸了3倍。
这里的 M 是一个特例,因为它是对称的。非特殊的就是我们在实际应用中经常遇见一些 非对称的,非方阵的矩阵。如上图所示,如果我们有一个 2 X 2 的对称矩阵M 的话,我们先将网格平面旋转一定的角度,M
的变换效果就是在两个维度上进行拉伸变换了。
用更加数学的方式进行表示的话,给定一个对称矩阵 M ,我们可以找到一些相互正交Vi ,满足MVi
就是沿着Vi 方向的拉伸变换,公式如下:
Mvi
= λivi
这里的 λi 是拉伸尺度(scalar)。从几何上看,M
对向量 Vi 进行了拉伸,映射变换。Vi 称作矩阵 M 的特征向量(eigenvector),λi
称作为矩阵M 特征值(eigenvalue)。这里有一个非常重要的定理,对称矩阵M 的特征向量是相互正交的。
如果我们用这些特征向量对网格平面进行线性变换的话,再通过
M 矩阵对网格平面进行线性换的效果跟对M 矩阵的特征向量进行线性变换的效果是一样的。
对于更为普通的矩阵而言,我们该怎么做才能让一个原来就是相互垂直的网格平面(orthogonal grid), 线性变换成另外一个网格平面同样垂直呢?PS:这里的垂直如图所示,就是两根交错的线条是垂直的。
![]()
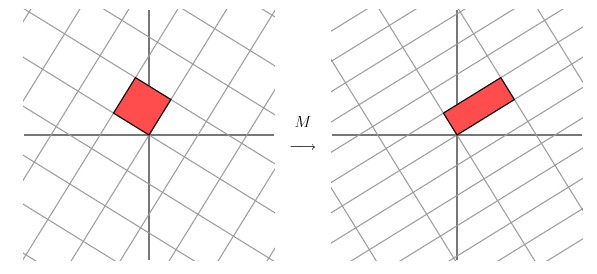
经过上述矩阵变换以后的效果如图

从图中可以看出,并没有达到我们想要的效果。我们把网格平面旋转 30 度角的话,然后再进行同样的线性变换以后的效果,如下图所示
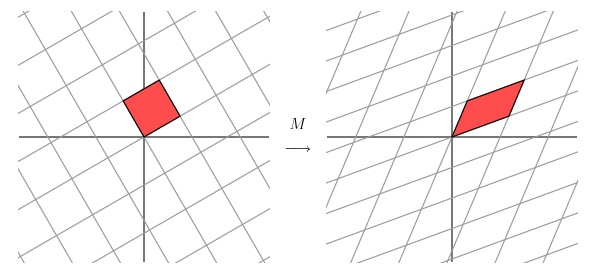
让我们来看下网格平面旋转60度角的时候的效果。
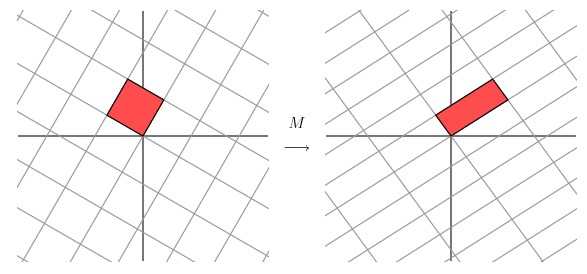
嗯嗯,这个看起来挺不错的样子。如果在精确一点的话,应该把网格平面旋转 58.28 度才能达到理想的效果。
几何意义
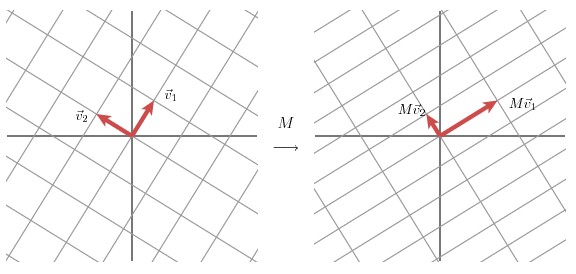
该部分是从几何层面上去理解二维的SVD:对于任意的 2 x 2 矩阵,通过SVD可以将一个相互垂直的网格(orthogonal grid)变换到另外一个相互垂直的网格。
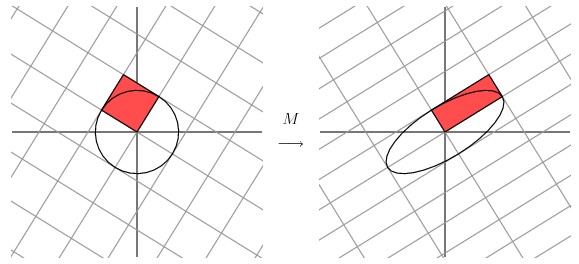
我们可以通过向量的方式来描述这个事实: 首先,选择两个相互正交的单位向量
v1和v2,
向量Mv1
和 Mv2
正交。
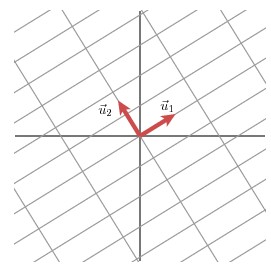
u1 和u2分别表示Mv1
和 Mv2的单位向量,σ1
* u1 = Mv1
和 σ2
* u2 = Mv2。σ1
和 σ2分别表示这不同方向向量上的模,也称作为矩阵M
的奇异值。
这样我们就有了如下关系式
Mv1
= σ1u1
Mv2
= σ2u2
我们现在可以简单描述下经过 M 线性变换后的向量
x 的表达形式。由于向量v1 和v2是正交的单位向量,我们可以得到如下式子:
x = (v1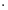 x)v1
x)v1
+ (v2x)v2
这就意味着:
Mx
= (v1x)Mv1
+ (v2x)Mv2
Mx
= (v1x)
σ1u1
+ (v2x)
σ2u2
向量内积可以用向量的转置来表示,如下所示
vx
= vTx
最终的式子为
Mx
= u1σ1 v1Tx
+ u2σ2 v2Tx
M =u1σ1 v1T
+ u2σ2 v2T
上述的式子经常表示成
M =UΣVT
u 矩阵的列向量分别是u1,u2,Σ是一个对角矩阵,对角元素分别是对应的σ1
和 σ2,V矩阵的列向量分别是v1,v2。上角标T
表示矩阵 V 的转置。
这就表明任意的矩阵 M 是可以分解成三个矩阵。V表示了原始域的标准正交基,u表示经过M
变换后的co-domain的标准正交基,Σ表示了V中的向量与u中相对应向量之间的关系。(V
describes an orthonormal basis in the domain, and U describes an orthonormal basis in the co-domain, and Σ describes how much the vectors in V are stretched to give the vectors in U.)
如何获得奇异值分解?( How do we find the singular decomposition? )
事实上我们可以找到任何矩阵的奇异值分解,那么我们是如何做到的呢?假设在原始域中有一个单位圆,如下图所示。经过
M 矩阵变换以后在co-domain中单位圆会变成一个椭圆,它的长轴(Mv1)和短轴(Mv2)分别对应转换后的两个标准正交向量,也是在椭圆范围内最长和最短的两个向量。
换句话说,定义在单位圆上的函数|Mx|分别在v1和v2方向上取得最大和最小值。这样我们就把寻找矩阵的奇异值分解过程缩小到了优化函数|Mx|上了。结果发现(具体的推到过程这里就不详细介绍了)这个函数取得最优值的向量分别是矩阵
MT M 的特征向量。由于MTM是对称矩阵,因此不同特征值对应的特征向量都是互相正交的,我们用vi 表示MTM的所有特征向量。奇异值σi
= |Mvi|
, 向量
ui 为 Mvi
方向上的单位向量。但为什么ui也是正交的呢?
推倒如下:
σi
和 σj分别是不同两个奇异值
Mvi
= σiui
Mvj
= σjuj.
我们先看下MviMvj,并假设它们分别对应的奇异值都不为零。一方面这个表达的值为0,推到如下
Mvi Mvj
= viTMT Mvj
= vi MTMvj
= λjvi vj
= 0
另一方面,我们有
Mvi Mvj
= σiσj ui uj
= 0
因此,ui 和uj是正交的。但实际上,这并非是求解奇异值的方法,效率会非常低。这里也主要不是讨论如何求解奇异值,为了演示方便,采用的都是二阶矩阵。
应用实例(Another example)
现在我们来看几个实例。
实例一
![]()
经过这个矩阵变换后的效果如下图所示
在这个例子中,第二个奇异值为 0,因此经过变换后只有一个方向上有表达。
M =u1σ1 v1T.
换句话说,如果某些奇异值非常小的话,其相对应的几项就可以不同出现在矩阵 M 的分解式中。因此,我们可以看到矩阵 M 的秩的大小等于非零奇异值的个数。
实例二
我们来看一个奇异值分解在数据表达上的应用。假设我们有如下的一张 15 x 25 的图像数据。

如图所示,该图像主要由下面三部分构成。
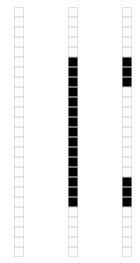
我们将图像表示成 15 x 25 的矩阵,矩阵的元素对应着图像的不同像素,如果像素是白色的话,就取 1,黑色的就取 0. 我们得到了一个具有375个元素的矩阵,如下图所示

如果我们对矩阵M进行奇异值分解以后,得到奇异值分别是
σ1
= 14.72
σ2
= 5.22
σ3
= 3.31
矩阵M就可以表示成
M=u1σ1 v1T
+ u2σ2 v2T
+ u3σ3 v3T
vi具有15个元素,ui
具有25个元素,σi
对应不同的奇异值。如上图所示,我们就可以用123个元素来表示具有375个元素的图像数据了。
实例三
减噪(noise reduction)
前面的例子的奇异值都不为零,或者都还算比较大,下面我们来探索一下拥有零或者非常小的奇异值的情况。通常来讲,大的奇异值对应的部分会包含更多的信息。比如,我们有一张扫描的,带有噪声的图像,如下图所示

我们采用跟实例二相同的处理方式处理该扫描图像。得到图像矩阵的奇异值:
σ1
= 14.15
σ2
= 4.67
σ3
= 3.00
σ4
= 0.21
σ5
= 0.19
...
σ15
= 0.05
很明显,前面三个奇异值远远比后面的奇异值要大,这样矩阵 M 的分解方式就可以如下:
M 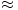 u1σ1 v1T
u1σ1 v1T
+ u2σ2 v2T
+ u3σ3 v3T
经过奇异值分解后,我们得到了一张降噪后的图像。

实例四
数据分析(data analysis)
我们搜集的数据中总是存在噪声:无论采用的设备多精密,方法有多好,总是会存在一些误差的。如果你们还记得上文提到的,大的奇异值对应了矩阵中的主要信息的话,运用SVD进行数据分析,提取其中的主要部分的话,还是相当合理的。
作为例子,假如我们搜集的数据如下所示:
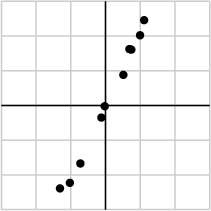
我们将数据用矩阵的形式表示:

经过奇异值分解后,得到
σ1
= 6.04
σ2
= 0.22
由于第一个奇异值远比第二个要大,数据中有包含一些噪声,第二个奇异值在原始矩阵分解相对应的部分可以忽略。经过SVD分解后,保留了主要样本点如图所示
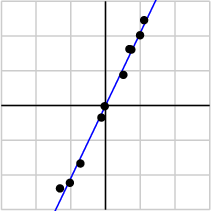
就保留主要样本数据来看,该过程跟PCA( principal component analysis)技术有一些联系,PCA也使用了SVD去检测数据间依赖和冗余信息.
SVD分解
SVD分解是LSA的数学基础,本文是我的LSA学习笔记的一部分,之所以单独拿出来,是因为SVD可以说是LSA的基础,要理解LSA必须了解SVD,因此将LSA笔记的SVD一节单独作为一篇文章。本节讨论SVD分解相关数学问题,一个分为3个部分,第一部分讨论线性代数中的一些基础知识,第二部分讨论SVD矩阵分解,第三部分讨论低阶近似。本节讨论的矩阵都是实数矩阵。
基础知识
1. 矩阵的秩:矩阵的秩是矩阵中线性无关的行或列的个数
2. 对角矩阵:对角矩阵是除对角线外所有元素都为零的方阵
3. 单位矩阵:如果对角矩阵中所有对角线上的元素都为1,该矩阵称为单位矩阵
4. 特征值:对一个M x M矩阵C和向量X,如果存在λ使得下式成立
![]()
则称λ为矩阵C的特征值,X称为矩阵的特征向量。非零特征值的个数小于等于矩阵的秩。
5. 特征值和矩阵的关系:考虑以下矩阵

该矩阵特征值λ1 = 30,λ2 = 20,λ3 = 1。对应的特征向量

假设VT=(2,4,6) 计算S x VT


有上面计算结果可以看出,矩阵与向量相乘的结果与特征值,特征向量有关。观察三个特征值λ1 = 30,λ2 = 20,λ3 = 1,λ3值最小,对计算结果的影响也最小,如果忽略λ3,那么运算结果就相当于从(60,80,6)转变为(60,80,0),这两个向量十分相近。这也表示了数值小的特征值对矩阵-向量相乘的结果贡献小,影响小。这也是后面谈到的低阶近似的数学基础。
矩阵分解
1. 方阵的分解
1) 设S是M x M方阵,则存在以下矩阵分解
![]()
其中U 的列为S的特征向量,![]() 为对角矩阵,其中对角线上的值为S的特征值,按从大到小排列:
为对角矩阵,其中对角线上的值为S的特征值,按从大到小排列:

2) 设S是M x M 方阵,并且是对称矩阵,有M个特征向量。则存在以下分解
![]()
其中Q的列为矩阵S的单位正交特征向量,![]() 仍表示对角矩阵,其中对角线上的值为S的特征值,按从大到小排列。最后,QT=Q-1,因为正交矩阵的逆等于其转置。
仍表示对角矩阵,其中对角线上的值为S的特征值,按从大到小排列。最后,QT=Q-1,因为正交矩阵的逆等于其转置。
2. 奇异值分解
上面讨论了方阵的分解,但是在LSA中,我们是要对Term-Document矩阵进行分解,很显然这个矩阵不是方阵。这时需要奇异值分解对Term-Document进行分解。奇异值分解的推理使用到了上面所讲的方阵的分解。
假设C是M x N矩阵,U是M x M矩阵,其中U的列为CCT的正交特征向量,V为N x N矩阵,其中V的列为CTC的正交特征向量,再假设r为C矩阵的秩,则存在奇异值分解:
![]()
其中CCT和CTC的特征值相同,为![]()
Σ为M X N,其中![]()
![]() ,其余位置数值为0,
,其余位置数值为0,![]() 的值按大小降序排列。以下是Σ的完整数学定义:
的值按大小降序排列。以下是Σ的完整数学定义:
![]()
σi称为矩阵C的奇异值。
用C乘以其转置矩阵CT得:
![]()
上式正是在上节中讨论过的对称矩阵的分解。
奇异值分解的图形表示:

从图中可以看到Σ虽然为M x N矩阵,但从第N+1行到M行全为零,因此可以表示成N x N矩阵,又由于右式为矩阵相乘,因此U可以表示为M x N矩阵,VT可以表示为N x N矩阵
3. 低阶近似
LSA潜在语义分析中,低阶近似是为了使用低维的矩阵来表示一个高维的矩阵,并使两者之差尽可能的小。本节主要讨论低阶近似和F-范数。
给定一个M x N矩阵C(其秩为r)和正整数k,我们希望找到一个M x N矩阵Ck,其秩不大于K。设X为C与Ck之间的差,X=C – Ck,X的F-范数为

当k远小于r时,称Ck为C的低阶近似,其中X也就是两矩阵之差的F范数要尽可能的小。
SVD可以被用与求低阶近似问题,步骤如下:
1. 给定一个矩阵C,对其奇异值分解:![]()
2. 构造![]() ,它是将
,它是将![]() 的第k+1行至M行设为零,也就是把
的第k+1行至M行设为零,也就是把![]() 的最小的r-k个(the
的最小的r-k个(the
r-k smallest)奇异值设为零。
3. 计算Ck:![]()
回忆在基础知识一节里曾经讲过,特征值数值的大小对矩阵-向量相乘影响的大小成正比,而奇异值和特征值也是正比关系,因此这里选取数值最小的r-k个特征值设为零合乎情理,即我们所希望的C-Ck尽可能的小。完整的证明可以在Introduction to Information Retrieval[2]中找到。
我们现在也清楚了LSA的基本思路:LSA希望通过降低传统向量空间的维度来去除空间中的“噪音”,而降维可以通过SVD实现,因此首先对Term-Document矩阵进行SVD分解,然后降维并构造语义空间。