引言
随着消费者数据需求量的不断攀升,全球范围内的运营商无一不面临着对无线带宽前所未有的增长需求。值得庆幸的是,包括标准制定机构 3GPP 等在内的整个行业都在竭尽全力来支持这种需求。LTE 正是为帮助运营商满足这一指数级数据增长需求应运而生的最佳技术选择。由于 LTE 部署实施已趋成熟,基站制造商纷纷热衷于采用片上系统架构 (SoC),以使运营商可在维持并提升服务质量的同时还能大幅降低网络成本。
助力向 LTE 的成功过渡需要在基站 SoC 设计方面实现大量的突破性创新。德州仪器 (TI) 已成功开发了功能强大且极富创新性的 KeyStone 多内核 SoC 架构,旨在优化 WCDMA 、LTE 性能的同时还能降低基站成本和能耗。对于无线基站的应用而言,KeyStone 最基本的组成部分是在无线标准的物理层 (PHY),即第一层,实施可配置协处理器。本文不仅介绍了
TI 基于 KeyStone 多内核 SoC 架构的 TCI6618 无线片上系统 (SoC) 将如何实现可为制造商缩短开发周期的优化型 PHY LTE解决方案,而且还将展示其独具竞争优势且所需资产投资和运营成本更低的 eNodeB 解决方案如何在性能方面实现强大的潜力.
全球移动数据应用的指数级增长给无线运营商带来了巨大挑战。但值得庆幸的是,无线技术不断演进发展,且应运而生的长期演进技术已成为迎接 这一挑战的首选的全球标准。世界前25 强无线运营商已决定部署LTE;其中部分运营商于2010 年开始进行试运行,预计将在2012 年迎来多个市场的增 长契机。采用LTE 技术表明能够通过提高频谱效率来更好地使用运营商的频谱资源,这意味着相对以往技术而言每赫兹能够传输更多比特数。运营商部署LTE 解决方案的速度既要跟上海量数据的流量激增,同时还要确保尽可能地降低每比特开销,从而减少碳足迹并实现从3G
到LTE 的平稳过渡。
对LTE 系统需求的变化给运营商、基站厂商及其提供商带来了全新的挑战。 已开发出一款功能强大且极富创新性的片上系统(SoC) 架构,能够大幅减 少LTE 产品的成本,使生制造商能从领先的基站技术中显著获益。 多内核SoC 架构建立在TI 业经验证的多内核DSP 平台之上,并集成了适用于4G系统的创新浮点架构和协处理器。对于运算增强功能而言,更重大的创新是背板和内部数据能够实现迁移,这对于高速4G SoC 获得全面性能至关重要。
TI 新架构将推动整个行业更快速地朝着实现高价值4G 系统特性的部署方向 LTE 可支持灵活的通道带宽(1.4 20 MHz)、频分多路复用(FDD 和时分多路复用(TDD),从而可在所属频谱范围内实现灵活部署。LTE 通信协议栈的基础是物理层(PHY),有时也称为第1 层(L1) 。PHY 层是固定基站到移动设备连接的基础;若无线连接不稳定,通话会掉线,下载会中断,同时视频也会停顿中的高级PHY是行业可靠性能的黄金标准,而TI 技术基于可支持多种流行无线标准的成熟稳定的的可配置协处理器之上,从而可在通
用平台上实现3G 向4G 的成功升级和无缝过渡。
德州仪器 LTE 无线电广播LTE 是第三代合作伙伴项目(3GPP; 的最新移动标准。LTE 在3G 移动技术基础上实现了重大架构 技术进步,可在20MHz 频谱范围提供至少100 Mbps 的峰值下行速率以及至少50 Mbps的 峰值上行速率。
(无线电广播资源控制[RRC] 层)接口相连,并能为更高层提供数据传输服务。PHY 可处理信道编码、PHY 混合自动中继请求(HARQ) 处理调制和多天线处理,并能将信号映射至相关的物理时频资源。
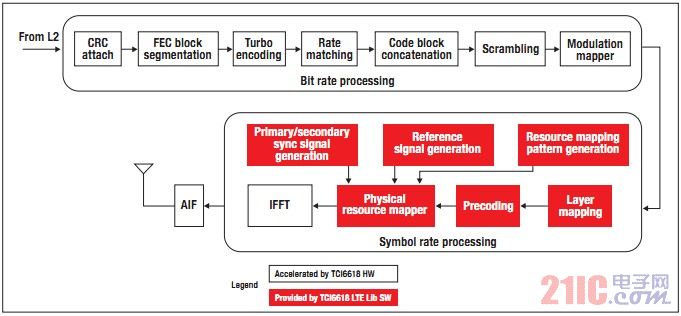
LTE 下行链路物理层处理可接收从MAC 层以传输模块的形式传输的数据流和控制流,计算循环冗余校验(CRC) 开始处理,并将其附加在传输模块。如果传输模块的大小超过编码模块最大允许的6,144 比特,则应执行编码模块分割。新的CRC 计算出来后即可在信道编码前将其附加给每个代码模块。图1 描述了LTE 下行链路的主要功能模块 图12 高性能物理层解决方案

多种调制方案 (正交相移键控[QPSK)、16 QAM [ 正交幅度调制,或64 QAM)均可用于实现LTE 层映射,而且其预编码支持多天线传输。最后,还可将正交频分多路复用(OFDM)符号的资源组件映射至可实现空中传输的每个天线端口。
LTE 技术演进 LTE 可充分利用众多用于3G HSPA+ (高速分组接入)的先进技术,其中包括Turbo 编码、HARQ 和多天线方案。 的下行链路速率以及50 Mbps 以上的上行链路速率。TI TCI6618 解决方案具备加值与推进
算法的信号处理开销,能够支持双通道20 MHz、300 Mbps 下行链接、150 Mbps 上行链接的2x2 多输入多输出(MIMO) 解决方案。此外,与3G 系统相比,LTE 还可使用OFDM 和上下行链路多输入与多输出(MIMO) 技术实现显著的性能提升。
LTE 使用OFDM 支持无线电广播传输,从而能够提供稳定的传输机制来避免恶劣信道条件下的性能衰减、窄带同频串扰、码间干扰和衰减。此外,其还可提供对时间同步错误的高频谱效率及低灵敏度。
LTE 下行链路处理使用带循环前缀的多载波OFDM 传输方式。在上行链路,带有循环前缀的宽带单载波OFDM 传输能够大幅减少所传输信号的瞬时功耗变化。快速傅里叶变换(FFT)能够为OFDM 调制解调提供低复杂度的高效率实施方案。

图2LTE MIMO 信道模型为了提升性能,LTE 同时在发送器和接收机中都采用了使用MIMO 天线的智能无需额外增加带宽或发送功率就能显著提高数据吞吐量并扩大频率覆盖
多天线上行链路MIMO 接收机技术能够有助于提高信噪比。在接收机主要受噪音损害时
最大比合并(MRC) 是一种非常有效的天线合并策略。在干扰幅度非常强的信道条件下,最小均方误差(MMSE) 结合技术是确定最小化均方误差的天线加权矢量的极佳方案。MMSE
MIMO 均衡的浮点实施可显著减低计算复杂度,并实现极高性能,从而成就了高效率的
LTE MIMO 接收机。
LTE 推动器 TCI6618 SoC 是TI TMS320C66x DSP 多内核系列成员。其基于TI 最新的KeyStone多内核架构之上,适用于高性能的无线基础局端应用,是用以应对LTE 设计挑战的完美方案。图3 阐述了该器件的特性和处理组件。
高性能物理层解决方案方框图
TCI6618 针对LTE 的多内核架构在业界率先提供了一种可将精简指令集计算机(RISC)和DSP 内核同专
主要特性 用协处理器和I/O 高度集成在一起的高性能结构。此外,KeyStone 也是业界第一款能够为所有处理内核、外设、协处理器以及I/O 提供足够内部带宽以实现非阻塞、零延迟接入的多内核架构。这主要得益于4 种硬件的支持,如多内核导航器、TeraNet、多内核共享存 储器控制器及超链接。多内核导航器是一种基于分组的创新型管理器,能够对8,192 个队列进行控制。当向向各队列分配任务时,多内核导航器可提供硬件加速的调度,以直接将任务指向相关的可用硬件。基于分组的SoC 可使用2Tbp 容量的TeraNet
交换中心资源进行分组传输。多内核共享存储器控制器能够在无需耗用容量的情况下允许处理内核直接访问共享存储器,因而能够避免因存储器接入造成分组传输的延迟。超链接可提供50 Gbps 的芯片级互连,使SoC 能够协同工作。其极低的协议开销和高吞吐量特性使超链接成为芯片对芯片互连的理想接口。超链接与多内核导航器协同工作,可将任务透明性地分派给串联设备,而且执行这些任务就如同在其本地资源上运行一样。
C66x 内核TCI6618 具有四个支持定点与浮点运算操作的1.2-GHz C66x 内核。其可提供1.2条件下每秒153.6 GMAC 的定点运算性能以及每秒76.8 GFLOP 的浮点运算性能。指令集架构新增了90 条全新的高性能指令,尤其是浮点指令与矢量信号处理指令,从而能够支持16 位数据的双路单指令多数据(SIMD) 操作以及8 位数据的四路SIMD 操作。该款超长指令字架构可支持8 个同步问题,并为复数计算和矩阵处理进行了优化。其具有更低时延的浮点能力与对MAC 性能的4 倍速增强,不仅显著加速了LTE
MIMO 的均衡,同时还提高了LTE 所需的大部分DSP 处理能力。
比特率协处理器(BCP) 是一款可减轻无线信号链中总体比特率处理工作的多标准加速引擎。BCP 对以下处理功能进行了增强:调制 速率匹配解调速率解匹配交错 CRC 附加 解交错与卷积编码 除了能够从这些功能上减轻DSP 内核开销,BCP 也可实现Turbo 干扰消除等高级接收机算法。Turbo 干扰消除可将信噪比(SNR) 提高3 dB,从而使频谱效率最多可提高40%,这也是无线系统的关键性能指标。BCP 能够在提供2.2 Gbps 下行吞吐量和1.1Gbps 上行吞吐量的同时,还能大约减轻DSP 周期的15
GHz 负载。
第三代Turbo 解码器协处理器(TCP3d) 是对LTE 上行链路处理进行Turbo 解码的可编程外设。TCP3d 输入采用针对系统和校验位的软信道决策,而输出则采用硬信道决策。
TCP3d 可生成Turbo 交错表,能够执行Turbo 解码并支持基于编码模块的CRC 计算。TCP3d
具有非常小的驱动器开销,却比此前的TCP2 系列产品快了7 倍。TCI6618 包含三个TCP3d协处理器,总吞吐能力经6 次叠加可高达582 Mbps。
第三代Turbo 编码器协处理器(TCP3e) 是一种可对LTE Turbo 代码进行编码以实现下行链路处理的可编程外设。TCP3e 的输入为信息位,而输出则为已编码的系统化校验位。
其能够支持基于编码模块的CRC、Turbo 编码及Turbo 交错表生成。TCP3e 能以150 Mbps 的下行链路吞吐量速率对每秒450 Mbycles 的CPU 处理减轻负担。TCI6618 具有4 个TCP3e 协处理器,总吞吐量高达2572 Mbps。
快速傅里叶变换协处理器(FFTC)是一款与DSP内核松散耦合的加速器。可将其连接至TeraNet并使用多内核导航器输入、输出需要FFT功能的分组。FFTC 具有循环前缀可插拔特性,能够对其进行编程以便在分组数据的开始部分忽略或添加样本;这允许在无需使用软件对循环前缀进行处理的情况下实现天线接口与FFTC 之间的无缝连接。此外, FFTC 也可根据LTE 要求对输入数据进行频率切换。以下列举了在LTE 中使用FFTC 的应用
2x2 MIMO 配置的LTE 系统中,该FFTC 集群可减少超过1.6 GHz 的DSP 内核处理开销。换句 话说,其可为SoC 节省比一个完整DSP 内核还多的资源。
瑞克搜索加速器(RSA) 可用于LTE 编码块解码。TCI6618 拥有两个与两个DSP 内核中的任一一个都能紧密配合的RSA 。RSA 可为相关性和搜索算法提供硬件加速,允许通过物理上行共享信道(PUSCH) 解码高效实施上行控制信息(UCI) 。使用RSA 可为基于PUSCH 解码算法的UCI 节省超过1GHz 的DSP 处理资源。
TCI6618 第二代天线接口(AIF2) 是一个专有外设模块,可在上下行基带DSP 内核与高 速串行接口(连接至数字无线电广播前端)之间支持基带同相与正交(IQ) 数据的传输。AIF2 可支持LTE 的频分多路复用(FDD)、时分多路复用(TDD)、通用公共无线电广播接口(CPRI) 以及开放式基站架构发起组织(OBSAI) 协议。AIF2 则能支持6 个链路,其中每个链路均带 一个6 GHz 的SERDES 和每链路64 个最大天线载波。
AIF2 内置多内核导航器,并能直接与FFTC 连接,从而为LTE 系统提供了低时延的天线流量。此外,AIF2 也具有用于帧时序和同步的可编程无线电广播定时器,以支持多种标准。
其能够提供12 Gbps 的最大入口带宽和12 Gbps 的最大出口带宽。网络协处理器 网络协处理器可提供主要用于LTE L2 处理的以太网分组加速和安全加速功能。其内置CRC 引擎可用于实现LTE PHY 传输模块的CRC 计算。
高效 FFTC 前端数据分派– KeyStone 多内核架构可在AIF2 和FFTC 之间实现无缝接口,而无 需运行于DSP内核之上的软件的干预。此外,其还使用多内核导航器基础局端支持多内核负载均衡。
AIF2 和FFTC 专为LTE OFDM 处理而精心优化。两者继续沿用多内核导航器的分组直接存储器存取(DMA) 引擎,从而能够在无需DSP 内核干预的情况下通过队列直接在AIF2 和FFTC 形成数据传输通道。
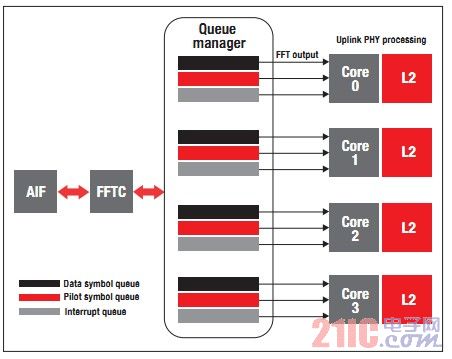
图4阐述了如何在LTE 上行符号处理过程中采用多内核导航器来实现负载均衡、调度、系统分区以及存储器占用的减少。
在该例中,可将4 个天线信号流馈送到FFTC 中,分区及调度信息被编程固化在FFTC 输入队列描述符中。每个内核均具有3 个专用的FFTC 输出队列,队列中具有使用多内核导航器以逐包方式重新分配到不同内核的所需天线及数据符号信息。
通过使用多内核导航器队列描述符报头协议专用信息,可对FFTC 输出数据进行排序,以让一个队列接收FFTC 输出数据符号,另一个队列接收输出导频信号。第三个队列包含可中断内核以启动数据处理的符号数据。内核能够高效处理前端FFTC 数据而无需进行任何数据预处理开销。FFTC 通过将部分数据及导频符号路由到将执行信道估计以及均衡的每个内核来实现负载均衡。
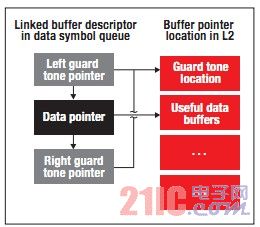
通过为FFTC 输出数据采用多内核导航器队列,L2 使用多区段主机分组描述符的存储器空 间可节省下来。可将主符号前后的干扰保护音调存放在存储器段中,通过每次传输快速回收。仅将有用数据 (主符号)存储在L2 中以备后续处理。其结果是为FFTC 前端处理减少了50% 的存储器; 缓冲器使用量。图5; 阐述了如何采用多内核导航器队列链接的描述符来减少存储器的使用。
2
高性能物理层解决方案 图5 使用多内核导航器分组队列减少存储器使用包含适用于BCP、FFTC、TCP3d、TCP3e、多内核导航器、 网络协处理器、增强型直接存储器接入(EDMA) 以及芯片支持库等的驱动器。其可实现即装即用的精彩用户体验,同时能够大幅缩短研发周期。
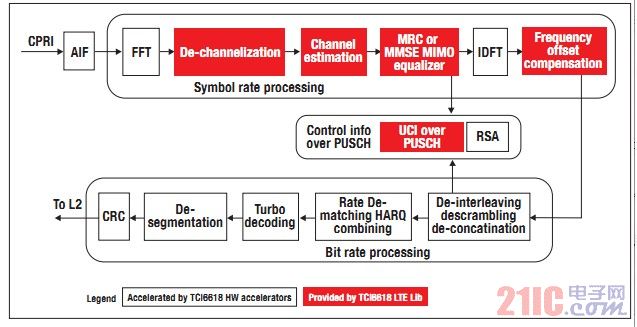
采用TCI6618 的 TI 也提供LTE PHY 软件,从而能够为针对C66x 内核而高度优化的客户PUY 解决方案提供构LTE解决方案 建模块。BCP 可减轻整个比特处理以及硬件中PUCCH 格式2、2a 与2b 解码的负荷。LTE 库包括PUSCH 符号、PUCCH 格式1、1a 与1b 解码、PRACH 接收机处理和物理下行共享信道(PDSCH) 符号速率处理的相关软件。图6 显示了使用TI 具有TCI6618 加速器的LTE 库对下行 From L2 Modulation 处理高性能LTE
上行处理需要有效的CPU 周期来实现PUSCH 信道估计与均衡。根据天线数量,C66x 扩展指令集架构与浮点算术运算相对于C64x+ 架构而言可将MRC 均衡器的周期降低4 倍。由于具备浮点计算能力,诸如分块矩阵转置等更为高效的算法可用于实现同等性能p> 相对于MMSE MIMO 均衡器更为复杂的定点Cholesky 分解算法,其减少的周期数可达5 倍。
BCP 提供的控制信道解码可大幅减少软件周期数,且能够比软件应用中的典型算法提供更高的性能。在某些情况下,这能够节省多达1.4 GHz 的DSP 处理主频,相当于节约了一个多DSP 内核。图7 显示了使用TCI6618 及其高度优化的LTE 库软件而进行的PUSCH 处理 处理
此外,FFTC 也可用于信道估计以减轻DSP 处理负荷。在LTE 中,可基于嵌入在上行帧中的参考信号 (资源模块中第4 类信号)来执行信道估计。TI 的LTE 库软件可提供信道估计功能(在子帧中的每个数据承载资源组件中执行)。信道估计的第一阶段可利用FFTC 来构建频率平滑估计器。执行IDFT 需要将信道估计从频域向时域转换,并利用矩形窗口来截取时域信道带以获得时域信道。或作为备选方案,还可选定能够减少噪声的阈值。随后,执行DFT 可生成频域信道估计。信道估计的第二个阶段可通过对第一阶段估计结果的线性插值法/
外插法,根据每个子载波进行计算。 图8 显示了PUSCH 信道估计处理进程。

图8除了可用于上行PRACH 处理中的各个阶段,也可将FFTC 用于PUSCH 信道频偏补偿和估计。
TCI6618 中的两个FFTC 加速器能够显著降低DSP 内核的LTE 信号处理负荷。通过充分利用 TI C66x DSP 内核上的LTE 库软件,和TCI6618 硬件加速器,我们可在同一TCI6618 器件中度集成物理上行共享信道(PUSCH)、物理上行控制信道(PUCCH)、物理下行共享信道(PDSCH)、 物理下行控制信道(PDCCH) 以及物理随机访问信道(PRACH) 通道的LTE PHY 处理。可支持两个20MHz 带宽区段的FDD LTE,以及2x2 个使用高级接收机算法获取的150
Mbps 下行和75 Mbps 上行吞吐带宽的MIMO。 多内核架构和无与伦比的TCI6618 系统、外设、加速器带宽及吞吐量使得低成本的LTE 移动宽带成为现实,同时也为市场带来了高性价比的LTE 解决方案。
结论 以TI 多年无线基站系统知识和业经验证具有卓越性能的技术为依托,TCI6618 是在此基础上持续创新的成果。TI KeyStone SoC 架构可为LTE 及其持续技术演进提供最高的吞吐量以及符合未来要求的架构。4 款同时集成了定点与浮点功能的高性能DSP 内核可为LTE PHY处理提供业界功能最强大的内核。丰富系列的硬件加速器不仅可减少LTE 系统时延,而且还能完全释放CPU 资源,从而实现最佳的LTE 系统性能以及独具竞争优势的差异化功能。TMS320TCI6618 可提供结合了业界开发生态系统且包含全面优化型LTE
PHY库软件的 最稳健硬件平台。平台开发软件可大幅加速开发进程,以确保为客户提供业界一流的LTE PHY 解决方案。