加锁(locking)是一种广泛应用的同步技术。当内核控制路径必须访问共享数据结构或进入临界区时,就需要为自己获取一把“锁”。由锁机制保护的资源非常类似于限制于房间内的资源,当某人进入房间时,就把门锁上。如果内核控制路径希望访问资源,就试图获取钥匙“打开门”。当且仅当资源空闲时,它才能成功。然后,只要它还想使用这个资源,门就依然锁着。当内核控制路径释放了锁时,门就打开,另一个内核控制路径就可以进入房间。
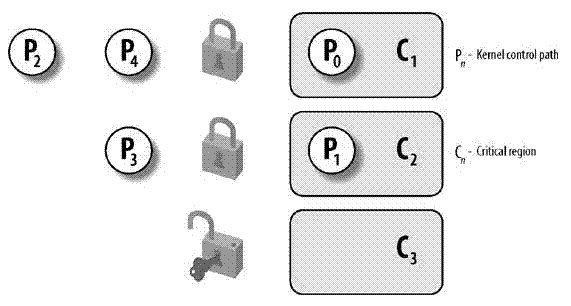
下图显示了锁的使用。5个内核控制路径(P0,PI,P2,P3和P4)试图访问两个临界区(C1和C2)。内核控制路径P0正在C1中,而P2和P4正等待进人C1。同时,P1正在C2中,而P3正在等待进入C2。注意P0和P1可以并行运行。临界区C3的锁现在打开着,因为没有内核控制路径需要进人C3。
Linux锁的应用之一在多处理器环境中,取名叫自旋锁(spin lock)。如果内核控制路径发现自旋锁“开着”,就获取锁并继续自己的执行。相反,如果内核控制路径发现锁由运行在另一个CPU上的内核控制路径“锁着”,就在周围“旋转”,反复执行一条紧凑的循环指令,直到锁被释放。
自旋锁的循环指令表示“忙等”。即使等待的内核控制路径无事可做(除了浪费时间),它也在CPU上保持运行。不过,自旋锁通常非常方便,因为很多内核资源只锁1毫秒的时间片段;所以说,等待自旋锁的释放不会消耗太多CPU的时间。
一般来说,由自旋锁所保护的每个临界区都是禁止内核抢占的。在单处理器系统上,这种锁本身并不起锁的作用,自旋锁技术仅仅是用来禁止或启用内核抢占。请注意,在自旋锁忙等期间,因为并没有进入临界区,所以内核抢占还是有效的,因此,等待自旋锁释放的进程有可能被更高优先级的所取代。这种设计是合理的,因为不能因为占用CPU太久而使系统死锁。
在Linux中,每个自旋锁都用spinlock_t结构表示:
typedef struct {
raw_spinlock_t raw_lock;
#if defined(CONFIG_PREEMPT) && defined(CONFIG_SMP)
unsigned int break_lock;
#endif
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} spinlock_t;
typedef struct {
volatile unsigned int slock;
} raw_spinlock_t;
其中包含两个重要的字段意义如下:
slock:该字段表示自旋锁的状态:值为1表示“未加锁”状态,而任何负数和0都表示“加锁”状态。
break_lock:表示进程正在忙等自旋锁(只在内核支持SMP和内核抢占的情况下使用该标志)。
内核提供六个宏用于初始化、测试及设置自旋锁。所有这些宏都是基于原子操作的,这样可以保证即使有多个运行在不同CPU上的进程试图同时修改自旋锁,自旋锁也能够被正确地更新。
1、spin_lock_init —— 初始化自旋锁,并把自旋锁的lock->raw_lock置为1(未锁)
# define spin_lock_init(lock) /
do { /
static struct lock_class_key __key; /
/
__spin_lock_init((lock), #lock, &__key); /
} while (0)
void __spin_lock_init(spinlock_t *lock, const char *name,
struct lock_class_key *key)
{
#ifdef CONFIG_DEBUG_LOCK_ALLOC
/*
* Make sure we are not reinitializing a held lock:
*/
debug_check_no_locks_freed((void *)lock, sizeof(*lock));
lockdep_init_map(&lock->dep_map, name, key, 0);
#endif
lock->raw_lock = (raw_spinlock_t)__RAW_SPIN_LOCK_UNLOCKED;
lock->magic = SPINLOCK_MAGIC;
lock->owner = SPINLOCK_OWNER_INIT;
lock->owner_cpu = -1;
}
#define __RAW_SPIN_LOCK_UNLOCKED { 1 }
#define SPINLOCK_MAGIC 0xdead4ead
#define SPINLOCK_OWNER_INIT ((void *)-1L)
2、spin_unlock —— 把自旋锁置为1(未锁)
#if defined(CONFIG_DEBUG_SPINLOCK) || defined(CONFIG_PREEMPT) || /
!defined(CONFIG_SMP)
# define spin_unlock(lock) _spin_unlock(lock)
#else //我们还是重点关注后面的吧
# define spin_unlock(lock) __raw_spin_unlock(&(lock)->raw_lock)
#endif
void __lockfunc _spin_unlock(spinlock_t *lock)
{
spin_release(&lock->dep_map, 1, _RET_IP_);
_raw_spin_unlock(lock);
preempt_enable();
}
# define _raw_spin_unlock(lock) __raw_spin_unlock(&(lock)->raw_lock)
static inline void __raw_spin_unlock(raw_spinlock_t *lock)
{
__asm__ __volatile__(
__raw_spin_unlock_string
);
}
#define __raw_spin_unlock_string /
"movb $1,%0" /
:"+m" (lock->slock) : : "memory"
spin_unlock宏释放以前获得的自旋锁,上面的代码本质上执行下列汇编语言指令:
movb $1, slp->slock
并在随后调用preempt_enable()(如果不支持内核抢占,preempt_enable()什么都做)。注意,因为现在的80x86微处理器总是原子地执行内存中的只写访问,所以不用lock字节。
3、spin_unlock_wait —— 等待,直到自旋锁变为1(未锁)
#define spin_unlock_wait(lock) __raw_spin_unlock_wait(&(lock)->raw_lock)
#define __raw_spin_unlock_wait(lock) /
do { while (__raw_spin_is_locked(lock)) cpu_relax(); } while (0)
#define __raw_spin_is_locked(x) /
(*(volatile signed char *)(&(x)->slock) <= 0) //如果大于0则为真,表示未锁,则跳出while循环
#define cpu_relax() rep_nop() //在循环中执行一条空指令:
static inline void rep_nop(void)
{
__asm__ __volatile__("rep;nop": : :"memory");
}
4、spin_is_locked( ) —— 如果自旋锁被置为1(未锁),返回0;否则,返回1
#define spin_is_locked(lock) __raw_spin_is_locked(&(lock)->raw_lock)
#define __raw_spin_is_locked(x) /
(*(volatile signed char *)(&(x)->slock) <= 0)
5、spin_trylock( ) —— 把自旋锁置为0(锁上),如果原来锁的值是1,则返回1;否则,返回0
#define spin_trylock(lock) __cond_lock(_spin_trylock(lock))
int __lockfunc _spin_trylock(spinlock_t *lock)
{
preempt_disable();
if (_raw_spin_trylock(lock)) {
spin_acquire(&lock->dep_map, 0, 1, _RET_IP_);
return 1;
}
preempt_enable();
return 0;
}
6、spin_lock —— 加锁:循环,直到自旋锁变为1(未锁),然后,把自旋锁置为0(锁上)
spin_lock是最重要的一个宏。首先,我们看到在include/spinlock.h头文件里,有:
#if defined(CONFIG_SMP) || defined(CONFIG_DEBUG_SPINLOCK)
# include <linux/spinlock_api_smp.h> //多处理器情况
#else
# include <linux/spinlock_api_up.h> //单处理器情况
#endif
#define spin_lock(lock) _spin_lock(lock)
#ifdef __LINUX_SPINLOCK_API_UP_H
#define _spin_lock(lock) __LOCK(lock) //单处理器情况
#else
注意,该代码上边有一句#if !defined(CONFIG_PREEMPT) || !defined(CONFIG_SMP) || /
defined(CONFIG_DEBUG_LOCK_ALLOC)
别去管它,因为上边的英文注释写得很清楚了,这句代码的意思是即使没有定义内核抢占或SMP,或者是自旋锁调试,只要lockdep激活了,也就是我们在刚才spinlock_t定义的那里看到的#ifdef CONFIG_DEBUG_LOCK_ALLOC,都会假设在整个锁的调试期间保持关中断。这句#if就是这个意思,千万别理解成没有定义内核抢占、SMP或自旋锁调试了,切记切记。
/*
* If lockdep is enabled then we use the non-preemption spin-ops
* even on CONFIG_PREEMPT, because lockdep assumes that interrupts are
* not re-enabled during lock-acquire (which the preempt-spin-ops do):
*/
//多处理器情况,并且允许内核抢占:
void __lockfunc _spin_lock(spinlock_t *lock)
{
//禁止抢占
preempt_disable();
//这个函数在没有定义自旋锁调试的时候是空函数,我们不去管它
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
//相当于_raw_spin_lock(lock)
LOCK_CONTENDED(lock, _raw_spin_trylock, _raw_spin_lock);
}
在没有定义自旋锁调试的时候,LOCK_CONTENDED宏定义如下
#define LOCK_CONTENDED(_lock, try, lock) /
lock(_lock)
我们看到其实就是调用_raw_spin_lock宏(位于include/linux/spinlock.h):
# define _raw_spin_lock(lock) __raw_spin_lock(&(lock)->raw_lock)
于是,定位到include/asm-i386/Spinlock.h
static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
asm(__raw_spin_lock_string : "+m" (lock->slock) : : "memory");
}
展开:
#define __raw_spin_lock_string /
"/n1:/t" /
//原子减,如果不为负,跳转到3f,3f后面没有任何指令,即为退出
LOCK_PREFIX " ; decb %0/n/t" /
"jns 3f/n" /
"2:/t" /
//重复执行nop,nop是x86的小延迟函数,执行空操作
"rep;nop/n/t" /
//比较0与lock->slock的值,如果lock->slock不大于0,跳转到标号2,即继续重复执行nop
"cmpb $0,%0/n/t" /
"jle 2b/n/t" /
//如果lock->slock大于0,跳转到标号1,重新判断锁的slock成员
"jmp 1b/n" /
"3:/n/t"
在上面的函数中,大家可能对"jmp 1b/n“比较难以理解。在我们一般的观念里,获得一个锁,将其值减1;释放锁时将其值加1;实际上在自旋锁的实现中lock->slock只有两个可能值,一个是0. 一个是1。释放锁的时候并不是将lock->slock加1,而是将其赋为1。请看在前面的自旋锁释放代码spin_unlock中的详细分析。